零基础入门C语言-网易云课堂-乐学偶的
本文最后更新于:2019年9月4日 晚上
1、History of C 2
1.Bell Labs,Dennis Ritchie,Ken thompson
2.Unix
3.Pascal,BASIC,C is POL(Programmers Oriented Language)
2、why we choose C as our language to learn
1)Good Side:
One language to rule them all
1.POL(Programmers Oriented Language):Access to hardware,very simple in Converting data,Library,
2.Efficiency(speed like assembly language),memory save
3.Portability(C compilers is everywhere)
4.FORTRAN,Python,Unix Operating System
2)Bad Side:
With great power, comes great responsibility
1.pointer
2.difficult (hard coring)
3、What is computer?
1.CPU(Central Processing Unit):Computing
1.number
2.program ->machine language
1)RAM 1->Register 1
2)RAM 2-> Register 2
3) Register 1 + Register 2 -> Register 1
4) Register 1-> RAM 3
2.RAM(Random Access Memory):Workspace for programs and files
3.SSD(Solid-State Disk),Hard Disk:
4.Keyboard,Mouse,Monitor…etc…
4、Machine Language <- High-Level Language <- Nature Language(English)
5、Buridan’s ass
14、HL->M L Complier(Program)
15、ANSI C99 American National Standards Institute
ISO C90 International Organization of Standardization
Trust Us
Don’t Prevent
Small and Simple
Operation one way to do it
Fast
16、C9x Committe 1994
1.Internationalization
2.Improvement -> C99
17、C11
Optional
Concurrent Programming
C18 Embedded C:
三、程序设计与项目开发流程
1、Objective
2、Draw the sketch
3、Coding & Commenting
4、Compile (Compiler and Debugging)
5、Run program(Windows Mac *nix IDE)
6、Testing & Debugging
7、Maintaining & Improving
Development & Operation -> DevOps 敏捷开发
四、深入理解程序机制
1、.c(source code)
2、.exe(executable )code
3、.o(Object code) by Compiler
4、Linker (Start-up Code,Library Code)
五:安装虚拟机与Linux系统下的演示
36:
ls:查询目录
man xx 查询手册
q退出 clear清屏
mkdir xxx 新建目录
cd xxx/ 进目录
cat xxx.x 打开文件
nano:
nano 打开nano编辑器 = 记事本
VIM:
VIM xxx.x 用VIM编辑器打开文件,没有则会新建(退出需保存)
先按 I 键,启动编写 退出编写 esc
shift+: -> wq! 写入文件并退出VIM
课时 45/46
cc xx.c 编译(Enter) -> a.out(所有文件的编译都会默认输出为a.out)
重命名 mv 源文件 目标文件 (Enter)
47/48
pwd -> 输入要执行的文件名(Enter) 不安全,不存在的文件名也会在hi行
安全做法:
echo $PATEH(大写) -> ./xx.out
49
cc -v 查看gcc版本(GNU Complier Collection)
gcc -std=c99(C11) xx.c 指定编译器版本
50
GNU GNU is not unix
六:C语言简要介绍
cheader file:#include <stdio.h> standard input and outputfunction:int main(void) /* this is a comment */{ int num; num = 888; printf(“this number %d”, num);}
“int” :means it will return an integer,by the code “return 0”;
the fuction name is “name”
“void” :means no argument give to this function
some old write
1、main() C90 BUT ! C99-Cx
2、void main()
comments:
/* */ :is a comment ,just help person to know this programer,will not be compiler
//xxxxx :C++ and JAVA new add comment type
braces:
{…}:braces,means the code in it is a block
bracker […]
parenthaeses(…)
declaration:
“num” is a variable that can stort something,before they are used,all variable must be declared at the first of function (Defore C99)
you can declare a variable whenever they be used(After C99,not recommend)
int means this variable can stort “Int” type data,other type:floating point,character,bool,etc…
assigment:
printf: is a function
以某种格式输出formatted(argument参数) 真实参数(actual argument) 形式参数(formal argument)
\xx:escape sequence(转义字符)
%d:% is placeholder (占位) for the “num”,d means this place is a decimal variable
other function:
after c99:
void dragon(void); // prototype (function declaration)
prototype -> compiler
void -> return empty
(void) :this function not have a argument
before C99:
void dragon(); // if have no argument ,not recommend
other function:
after c99:
void dragon(void); // prototype (function declaration)
prototype -> compiler
void -> return empty
(void) :this function not have a argument
before C99:
void dragon(); // if have no argument ,not recommend
reserved identifiers:
if int float for while else case
七:数据与类型
scanf();:获取用户键盘输入
printf(“%.2f”,price); //以两位小数精度打印price,多余的四舍五入
%s string格式输出
%d int格式输出
%f float格式输出
%o
%#o/x
octal(base 8)
hexadecimal(base 16)
data:varibles 变量 constants 常量
bit:最小的储存单位01
byte:8 bits 0000 0001
words:储存一个字符的单位,视平台定大小
integer:(整数类型):123 、-123、2
float:(浮浮点类型)12.0、-12.3、2.8 注意存储方式0.7E2
多个同类型变量声明:
int xx1, xx2, xx3; // 同时声明三个int类型的变量
initializing variables
int xx1 = 0; // 声明并初始化变量,避免随机值
int xx1= 0, xx2, xx3= 0; // just init xx1 、xx3
signed type:
short int
long int
long long int C99,long long(64bit)
unsigned type:
unsighed (nonnegetive)
unsigned long int/unsigned long unsigned short int
93 string和char
www.acsilltable.com
string:”xx”
char:‘x’
96 分辨char十进制码练习
int main(void)
{
char user_input_char;
printf(“Please enter a char: \n”);
scanf(“%c”,&user_input_char);
printf(The dec number is %d for char %c”,user_input_char,user_input_char);
return 0;
}
99 float
stm32030由于内存小,只能进行float型计算,使用printf类的函数stdio中的会占用大量内存(8KB左右)
查看数据类型占用位数
printf(“%d”,sizeof(int))
八、字符串与格式IO
1 | |
scanf(%s) 遇见空格退出,空格相当于表示字符串中断了,认为是两个字符串了name[10] 只能存储9各字符和一个结束符#define 108 小tip,查找文件find / -type d -name "c_edu"
常量
const int RATE = 0.2;
#define RATE 0.2
课时115-117
控制下的字符串 printf()
1 | |
要输出”%“,增加一个
printf(“占比 d%%%\n”,num); //输出 8%
输出改变器Modifier
“xd%” // 指定输出位数,x为数字,x为正,靠右显示,x为负靠左显示
“x.xf%” // 指定小数点前和后显示位数
进制转换
%x %X %#X,15
f F 0XF
C_C++-应用笔记”
以下内容涉及面较广,有些内容并未详细展开说明,也有些未彻底深入探讨,请大家在阅读时多参考文末参考文章,自行斟酌、独立思考。
static的作用
static作为C和C++语句中的修饰符,可以修饰变量和函数,主要用于控制变量的存储方式和可见性。
为了更好理解 static 作用,我们需要先了解程序在内存中的分布情况,具体请参考文章
程序在内存中的分布
static的内部机制
static修饰的数据成员是在数据段定义的,数据段同样也存放了全局变量,静态数据成员按定义出现的先后顺序依次初始化,注意静态成员嵌套时,要保证所嵌套的成员已经初始化了。消除时的顺序是初始化的反顺序。
C 语言的 static 关键字三种用途
1. 静态局部变量
1 | |
静态局部变量和局部变量对比
存储方式:
- 静态局部变量在数据段分配内存,局部变量在栈区分配内存。
- 因此静态局部变量的生存周期直到程序运行结束,局部变量在函数执行结束立即释放。
可见性:
- 都仅能在函数内被访问
初始化
- 静态局部变量在首次调用该函数时执行一次初始化,此后不再进行初始化,局部变量在每次该函数被调用时都会被初始化。
- 静态局部变量如果没有在声明时被显示初始化为确定的值,则在首次调用该函数时自动初始化为0。局部变量不会被自动初始化
注意:
这里局部变量在函数执行结束后立即释放,该变量名是不存在了,但存放该值的地址处所存储的值依旧没变。释放的意义在于告诉程序该地址空闲,可以被用作它用。
2、静态全局变量
实例
1 | |
从实例中可以知道我们的 b.c 文件通过 extern 使用了 a.c 定义的全局变量 n。
但如果我们将 n 改为静态全局变量后,则会出现类似 undeference to "n" 的报错,提示找不到 n ,因为static 限制了 n 的可见性,总结如下:
静态全局变量和局部变量对比
存储方式:
- 两者都是存储在数据段,因此存在周期是一样的
可见性:
- 静态全局变量不能被其它文件所用,只能在其定义的文件内使用(可以理解为文件内全局变量),而全局变量可以被任意文件访问(使用extern)
- 因此其它文件中可以定义相同名字的静态全局变量,不会发生冲突(因为static隔离了文件,其它文件使用相同的名字的变量,也跟它没关系了);
初始化
- 两者都是在程序执行前(main函数执行之前、编译器编译时)初始化
- 静态全局变量如果没有在声明时被显示初始化为确定的值,则在程序执行前(区别于局部静态变量的函数首次执行时)自动初始化为0。全局变量不会被自动初始化
3、静态函数
静态函数和静态全局变量类似。
1 | |
以上实例,程序运行可以正常输出:this is non-static func in a 。
但如果我们给 void fn() 加上 static 变为静态函数,则会 undefined reference to "fn"。
静态函数和一般函数对比
存储方式:
- 函数都是存储在代码段,
static并不改变存储位置。
可见性:
- 静态函数不能被其它文件所用,只能在其定义的文件内使用,而一般函数可以被任意文件访问(使用
extern或包含该函数的声明的头文件) - 因此其它文件中可以定义相同名字的函数,不会发生冲突(因为static隔离了文件,其它文件使用相同的名字的变量,也跟它没关系了);
初始化
- 好像没这个说法
C++ 语言的 static 关键字额外二种用途
C++ 中除了包含上述三种用法和概念外,还有额外两种用法。
1、静态数据成员
用于修饰 class 的数据成员,即所谓“静态成员”。这种数据成员的生存期大于 class 的对象(实体 instance)。
静态数据成员是每个 class 有一份(即所有类实例共享一个该变量),普通数据成员是每个 instance 有一份(即每个实例都有各自的该变量,互相独立),因此静态数据成员也叫做类变量,而普通数据成员也叫做实例变量
1 | |
由图可知。所有类或类对象的占用内存都为 8 bytes = 两个int 型变量的内存和。也就是说静态成员并不占用类Rectangle和其对象的内存空间。
那么static在哪里分配内存的呢?是的,全局数据区(静态区)。
再看看GetSum(),第一次 12=3*4,第二次 18=12+2*3。由此可得,所有类实例共享一个 sum ,且 sum 只会被初始化一次,与实例无关。
存储方式:
- 静态成员在数据段分配内存(独立于类实例)
- 一般数据成员,请参考文章 《程序在内存中的分布》
可见性:
- 由于静态数据成员不属于特定的类实例,所以在没有类实例时其在作用域就可见(即可访问)
- 即一般数据成员只有在类实例创建后,才可以通过实例名访问
- 而静态数据成员除了实例名,还可以直接通过类名访问
初始化
- 由于静态成员先于类实例存在,所以初始化在类体外进行,在程序一开始就初始化
- 一般类成员在实例创建时初始化(一般在类构造函数内)
2、静态成员函数
1 | |
存储方式:
- 函数都是存储在代码段,static并不改变存储位置。
可见性:
- 静态成员之间可以相互访问,即静态成员函数(仅)可以访问静态成员变量、静态成员函数
- 静态成员函数不能访问非静态成员函数和非静态成员变量(因为静态函数先于他们存在)
- 非静态成员函数可以任意地访问静态成员函数和静态数据成员
- 静态函数可以使用类名或实例名访问,但一般函数只能通过实例名访问
初始化
- 好像没这个说法
补充说明
在一些代码中,我们可能看到 class 类数据成员和成员函数都使用 static 修饰,此时类一般都是只实例化一个对象,其对象的概念较轻。类在这里的作用的更多的是可见性和方便管理。
参考资料
1. C++static类成员,static类成员函数
2. c++中static的用法详解
3. c++ static的作用,以及static对象在类和函数中区别
4. C++之静态详解
5. static作用(修饰函数、局部变量、全局变量)
6. C/C++ 中的static关键字
7. C++ 局部静态变量,全局变量,全局静态变量,局部变量的区别和联系
8. C++局部静态变量在什么时候分配内存和初始化?
9. C++ static、const 和 static const 类型成员变量声明以及初始化
new和malloc-2020-04-11
malloc
void * malloc(size_t大小);
简介:
分配一个内存大小为 size 字节的块,并返回一个指向该块开头的指针。
新分配的内存块的内容未初始化,剩余的值不确定。
如果size为零,则返回值取决于特定的库实现(它可以是null指针,也可以不是null指针),但不应取消对返回的指针的引用。
参数:
size – 内存块的大小,以字节为单位。
size_t 是无符号整数类型。
返回值:
成功时,指向函数分配的内存块的指针。
该指针的类型始终为void*,可以将其强制转换为所需的数据指针类型,以便将其取消引用。
如果函数未能分配所请求的内存块,则返回空指针。
实例
1 | |
运行结果:
1 | |
注意: str = (char *) malloc(15);
这里的15 必须必须要大于要存储的字符宽度,包含结束符。
如果小于所要存储的字符大小(比如将上文中 15 改为 1),实际上运行结果还是一样的,但问题在于多出的字符空间是会随时被其它变量覆盖,不安全。
malloc 的作用就是开辟一个专用空间,不会被其它程序和变量占用。
参考链接:
1. malloc
2. C 库函数 - malloc()
new
new data-type;
data-type 可以是包含数组在内的任意内置的数据内省,也可以包括类或结构在内的用户自定义的任何数据类型。
内置数据类型分配
实例:
1 | |
运行结果:
1 | |
数组内存分配
一维数组
1 | |
二维数组
1 | |
类对象实例内存分配
对象与简单的数据类型没有什么不同。例如,请看下面的代码,我们将使用一个对象数组来理清这一概念:
1 | |
如果要为一个包含四个 Box 对象的数组分配内存,构造函数将被调用 4 次,同样地,当删除这些对象时,析构函数也将被调用相同的次数(4次)。
当上面的代码被编译和执行时,它会产生下列结果:
1 | |
delete 与 delete[] 区别:
1、针对简单类型 使用 new 分配后的不管是数组还是非数组形式内存空间用两种方式均可 如:
1 | |
此种情况中的释放效果相同,原因在于:分配简单类型内存时,内存大小已经确定,系统可以记忆并且进行管理,在析构时,系统并不会调用析构函数, 它直接通过指针可以获取实际分配的内存空间,哪怕是一个数组内存空间(在分配过程中 系统会记录分配内存的大小等信息,此信息保存在结构体_CrtMemBlockHeader中, 具体情况可参看VC安装目录下CRT\SRC\DBGDEL.cpp)
2、针对类Class,两种方式体现出具体差异
当你通过下列方式分配一个类对象数组:
1 | |
所以总结下就是,如果ptr代表一个用new申请的内存返回的内存空间地址,即所谓的指针,那么:
- delete ptr – 代表用来释放内存,且只用来释放ptr指向的内存。
- delete[] rg – 用来释放rg指向的内存,!!还逐一调用数组中每个对象的 destructor!!
对于像 int/char/long/int*/struct 等等简单数据类型,由于对象没有 destructor,所以用 delete 和 delete [] 是一样的!但是如果是C++ 对象数组就不同了!
new 和 malloc 内部的实现方式区别
new 的功能是在堆区新建一个对象,并返回该对象的指针。
所谓的【新建对象】的意思就是,将调用该类的构造函数,因为如果不构造的话,就不能称之为一个对象。
而 malloc 只是机械的分配一块内存,如果用 mallco 在堆区创建一个对象的话,是不会调用构造函数的。
严格说来用 malloc 不能算是新建了一个对象,只能说是分配了一块与该类对象匹配的内存而已,然后强行把它解释为【这是一个对象】,按这个逻辑来,也不存在构造函数什么事。
同样的,用 delete 去释放一个堆区的对象,会调用该对象的析构函数。
用 free 去释放一个堆区的对象,不会调用该对象的析构函数。
做个简单的实验即可明了:
1 | |
参考资料
数组_array_vector- 2019-5-27
C++ 中有三种数组:C风格的数组、std::array、std::vector。
编译软件:Visual Studio 2019
C风格的数组
这个风格不够现代,且不够安全,示例如下:
1 | |
可能的输出如下:
0 0 -1572448 32766 -1460174784 21991 -1460174775 21991 1327354688 10961
1 0 0 0 0 0 0 0 0 0
1 2 0 0 0 0 0 0 0 0
std::array
std::array是C++11引入的一个模板类,封装了C风格的数组,因此是固定大小的数组容器。所谓固定大小,是指编译时就确定了大小。通常情况下是占用栈(stack)上的空间,且性能更好(相比std::vector)。
需要头文件:
#include <array>
示例如下:
1 | |
输出结果:
—— 第一个编译直接报错,显示未赋初值
1 0 0 0 0 0 0 0 0 0
1 2 0 0 0 0 0 0 0 0
std::array相比C风格数组的另一个优势是:可以使用STL的各种算法函数。 更多方法见这里
例如这里的示例:
1 | |
输出结果:
1 2 3
std::vector
std::vector是一个老牌的C++模板类,提供了动态大小的数组。std::vector的数据是存储在堆(heap)上的,因此性能上不如std::array(堆的访问速度小于栈的访问速度)。
首先包含头文件:
示例如下:
1 | |
输出结果:
7 5 16 8 25 13
由于std::vector是动态大小的数组,那必然存在已有空间不够的情况,那空间大小是如何再次分配的呢?
通过跟进push_back的代码,可看到如下: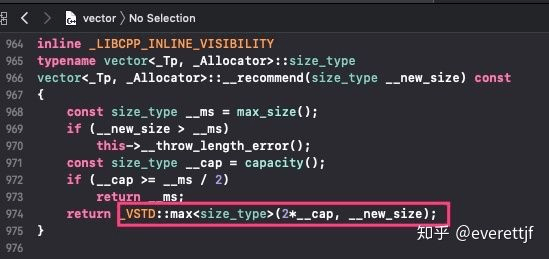
可知当最终空间不足时,会不断的把容量*2。容量是capacity,而不是size。size是已经占用数据的大小,capacity是vector为了实现动态数组,提前申请出的空间。因此vector当发生容量乘以2时,会带来数据的复制。从老的地址空间复制数据到扩大后的地址空间。这也是可能带来性能问题的地方。因此有时可以提前一次申请足够的空间,例如:std::vector<int> v(100)。
参考:
扩展:二维数组,可变数组
1、array <array<int, 5>, 3 >array_t 二维数组
1 | |
输出结果:
1 2 3 4 5
6 7 8 9 10
11 12 13 14 15
2、vector<vector<int>> array_t 可变数组
1 | |
输出结果:注意这里数组大小是变化的
1 2 3 4 5
6 7 8 9 10 11
11 12 13 14 15 16
3、array <vector<int>, 3> array_t 局部可变二维数组
1 | |
这里和上一个很相似,注意程序区别。
输出结果:
1 2 3 4 5
6 7 8 9 10 11
11 12 13 14 15 16
4、vector<array<int,5>> array_t
这个留着大家自己探索吧
注意这里行是可变的,列示固定的。
注意事项
array <array<int, 5>, 3 >array_t = { array1, array2, array3 }; //定义一个二维数组 3行5列
在声明以上数组时,初始化的一维数组 array1 类型必须和 array<int, 5>是统一的,即不能按照 C写法(int array1[] = {......})声明,否则会报错。当然你可以挨个赋值,就不用提前声明array1了。
程序在内存中的分布_2020-04-13
函数执行: 从函数的 { 开始,到 } 结束,这之后继续执行下一个函数。
程序执行: 从main() 函数的 {开始,到 } 结束,这之后启动执行下一个程序。但其实对于大多数没有操作系统的单片机来说,只有一个 main() 函数,程序执行结束则意味着重启或停机。
内存分布
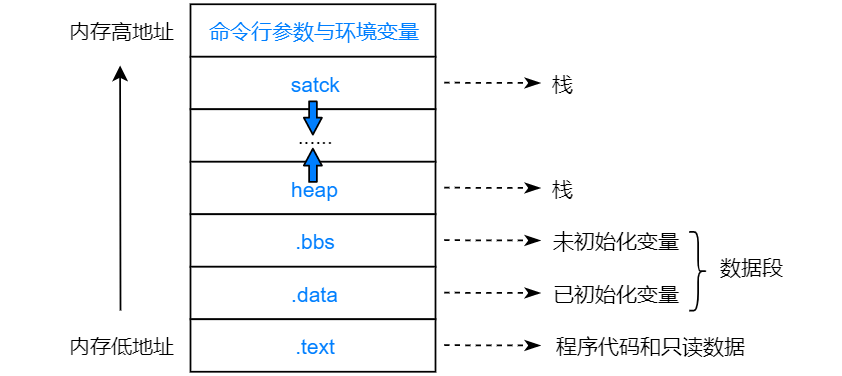
1. stack栈区
- 存储自动变量、每次函数调用时需要保存的信息(函数参数,函数内局部变量,函数返回值,函数调用时的返回地址)
- 函数返回时(执行结束),系统自动回收内存
- 先入后出:最先存入栈中的数据最后取出。
2. heap堆区
- 动态分配的内存,由程序员申请(使用malloc()、new()等内存分配函数实现)
- 若不手动释放内存,则一直存在。对于 new(),会在程序执行结束后由系统回收。
3. 数据段
编译器编译时就已经分配好内存
bbs段
未初始化的变量,在执行时由系统初始化为 0。例如:对于全局数组,会在程序执行(main函数开始)之前由系统全部初始化为0。
data段
具有明确初始值的变量
4. text代码段
- CPU执行的机器指令,即程序代码。
- 只读数据(常量)
总结如下:
堆栈和数据区存放的都是变量,但堆栈存放程序运行时的数据(由系统分配)。数据区则是在编译器编译期就已经分配好的
代码段存放代码和常量,即变量之外的数据
5. 命令行参数和环境变量
这个不是太明白,目前只是粗略了解,可能理解会有很多错误:
命令行参数
只要有操作系统就会有命令行这个概念,是操作系统的一个最基本的对外交互操作方式,使用者可以在命令行界面输入各种参数指令来执行比如读取文件,写入文件,运行程序等等操作。 这样使用者就可以正常运行整个系统程序。如果没有了命令行,就相当于整个操作系统(程序)对外封闭,别人无法获取任何信息,那么系统也就没有了意义。
对于 windows系统,我们也可以理解我们每次双击打开文件,读写文件时其实是后台在调用命令行操作,这样用户不需要了解任何程序也可以正常使用这个系统。
环境变量
可以理解为系统运行时的用到的各种 用户可修改的变量,比如 “Path” 变量,里面存储了一些常用命令所存放的目录路径, 当用户将自定义文件目录添加到 “Path” 下之后,运行某些程序除了在当前文件夹查找,还会到设置的 Path 路径中区查找。还比如 系统语言 等变量。
堆和栈的区别
1.分配和管理方式不同
- 堆是动态分配的,其空间的分配和释放都由程序员控制。
- 栈由编译器自动管理。栈有两种分配方式:静态分配和动态分配。
- 静态分配由编译器完成,比如局部变量的分配。
- 动态分配由
malloc()函数进行分配,但是栈的动态分配和堆是不同的,它的动态分配是由编译器进行释放,无须手工控制。
2.产生碎片不同
- 对堆来说,频繁的new/delete或者malloc/free势必会造成内存空间的不连续,造成大量的碎片,使程序效率降低。
- 对栈而言,则不存在碎片问题,因为栈是先进后出的队列,永远不可能有一个内存块从栈中间弹出。
3.生长方向不同
- 堆是从内存的低地址向高地址方向增长。
- 栈是从内存的高地址向低地址方向增长。
程序举例
C程序
1 | |
C++程序
1 | |
函数外部:
语句1实例化的对象及其一般数据成员存放在全局数据段
语句2实例化的对象及其一般数据成员存放在堆区,因为使用 new 分配。
函数外部:
语句3 实例化的对象及其一般数据成员存放在栈中,随着函数执行结束而结束
语句4 实例化的对象及其一般数据成员存放在堆中,随着函数执行结束而结束。但此时销毁的只是指针 obj4,其指向的对象并没有,也就是还在占用内容,会造成内存泄露,所以必须要手动释放。
参考资料
1. 程序在内存中的分布
2. 程序在内存中的分布
3. C 程序的内存空间布局
4. C++:在堆上创建对象,还是在栈上?
5. c++类的成员变量的存储位置?
6. c++中的类和实例分别存储在什么地方
7. C++成员函数在内存中的存储方式
8. Class Members on Stack Or Heap?
9. Memory Layout of C Programs
10. In what address do the variables get stored when declared in C or C++?