嵌入式Linux学习笔记-精简版
本文最后更新于:2022年6月12日 晚上
Ubuntu系统入门篇
一、 基础概念
嵌入式和单片机的区别
较早的定义
- 英国电器工程师协会定义的: 嵌入式系统(Embedded System),是一种“完全嵌入受控器件内部,为特定应用而设计的专用计算机系统”。
- 行业定义: 以应用为中心,计算机技术为基础,软硬件可剪裁,适应应用系统对功能、成本、体积、可靠性、功耗严格要求的计算机系统。
- 个人总结:除PC外的所有带有程序,可独立工作的系统都是嵌入式系统,包含单片机
目前行业定义
- 行业中普遍将两者区分开来,依据则是从软件上进行区分。

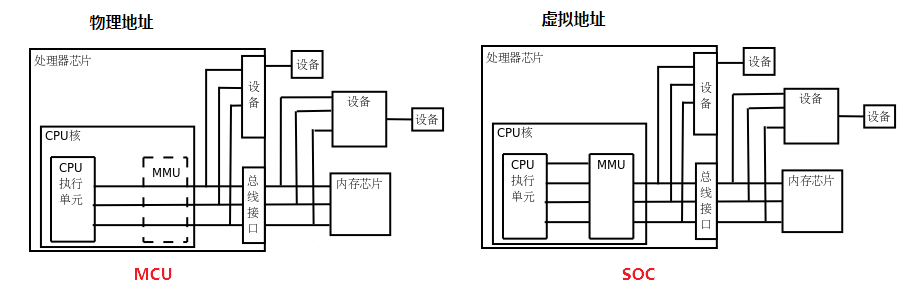
CPU概念基本指中央处理器,微处理器都可以称为CPU
MPU,和SOC概念模糊,不做区分,认为是一个
参考资料
MMU(内存管理单元)
没有MMU,CPU执行单元发出的内存地址将直接传到芯片引脚上,被内存芯片接收,这称为物理地址(Physical Address):
有MMU,CPU执行单元发出的内存地址将被MMU截获,从CPU到MMU的地址称为虚拟地址(Virtual Address),而MMU将这个地址翻译成另一个地址发到CPU芯片的外部地址引脚上,也就是将虚拟地址映射成物理地址:
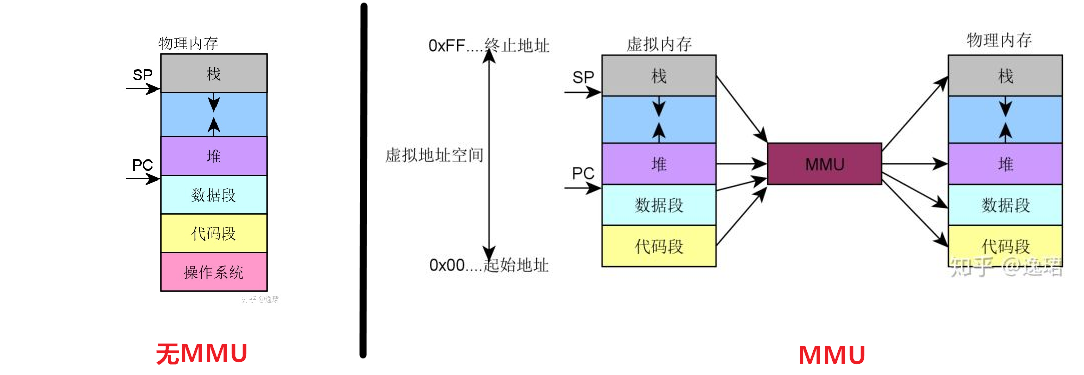
处理器一般有用户模式(User Mode)和特权模式(privileged Mode)之分。当CPU要访问一个VA(Virtual Address)时,MMU会检查CPU当前处于用户模式还是特权模式,访问内存的目的是读数据、写数据还是取指令执行,如果与操作系统设定的权限相符,则允许访问,把VA转换成PA,否则不允许执行,产生异常(Exception)。
参考资料
嵌入式软件
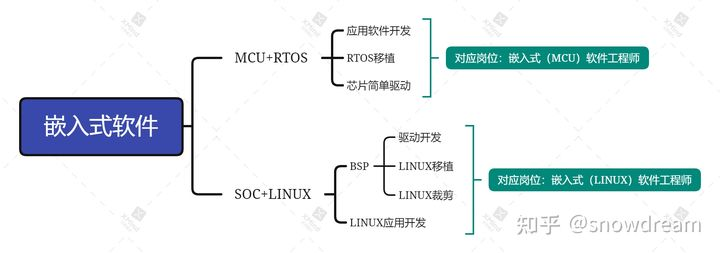
参考资料
STM32是否可以跑linux
操作系统有两种 用MMU的 和 不用MMU的
- 用MMU的是Windows MacOS Linux Android
- 不用MMU的是FreeRTOS VxWorks ucOS…
CPU有两种 带MMU的 和 不带MMU的
- 带MMU的有 Cortex-A系列 ARM9 ARM11系列
- 不带MMU的有 Cortex-M系列…
STM32是M系列…不可能运行Linux…(ucLinux不算Linux的…)
在开发环境、程序开发上也都有很大区别,基本算是两种开发模式
参考资料:
什么是linux
区分linux内核和linux操作系统
- Linux严格来说是单指作业系统的内核。
- 如今Linux常用来指基于Linux的完整操作系统,内核则改以Linux内核称之。
Linux内核由林纳斯·托瓦兹(Linus Torvalds)在1991年10月5日首次发布,在加上使用者空间的应用程序之后,成为Linux操作系统。除了一部分专家之外,大多数人都是直接使用Linux 发行版(Linux操作系统),而不是自己选择每一样组件或自行设置。

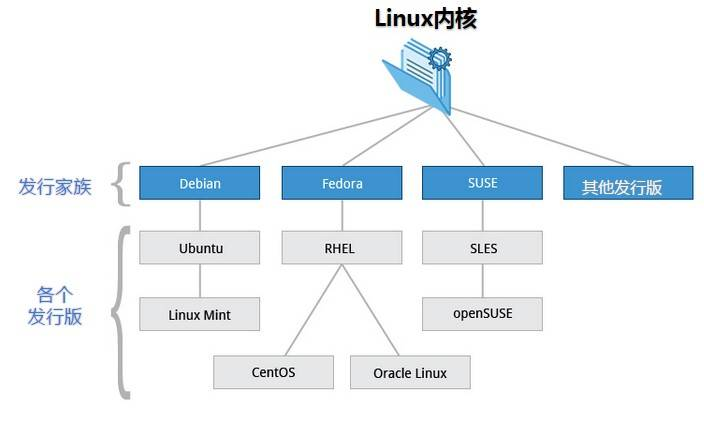
参考资料:
gcc编译
gcc编译器ubuntu自带,gcc -v 查看当前版本
gcc [选项] [文件名字]
选项如下:
- c: 只编译不链接为可执行文件,编译器将输入的.c 文件编译为.o 的目标文件。
- o:编译成可执行文件,默认编译出来的可执行文件名字为 a.out。
+ <输出文件名>指定编译结束以后的输出文件名
1 | |
gcc main.c –o main.out
./main.out
编译流程:
- 预处理(Preprocessing):.c 文件中的文件包含(include)、预处理语句(e.g. 宏定义 define 等)进行分析,并替换成为真正的内容。
- 编译(Compilation):生成 .s 汇编文件。
- 汇编(Assembly):.生成以 .o 的目标文件。
- 链接(Linking):多个.o文件、库文件链接成一个文件,变成可执行文件。
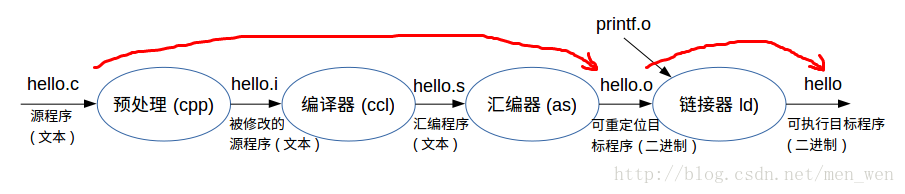
我们需要操作的步骤:.o 和可执行文件
二、Ubuntu系统安装与使用
Ubuntu系统是基础linux内核的操作系统。就像开发电脑软件需要在win10系统上一样,我们之后的linux软件开发也需要在 Linux 系统上(即Ubuntu系统)
本章内容:
虚拟机安装 -> 使用虚拟机安装ubuntu -> ubuntu配置使用
1. 虚拟机安装
要想在windows系统安装 ubuntu ,就得借助虚拟机。这样就可以在电脑上同时存在两个操作系统,并且可以同时运行。
下载
VirtualBox下载地址
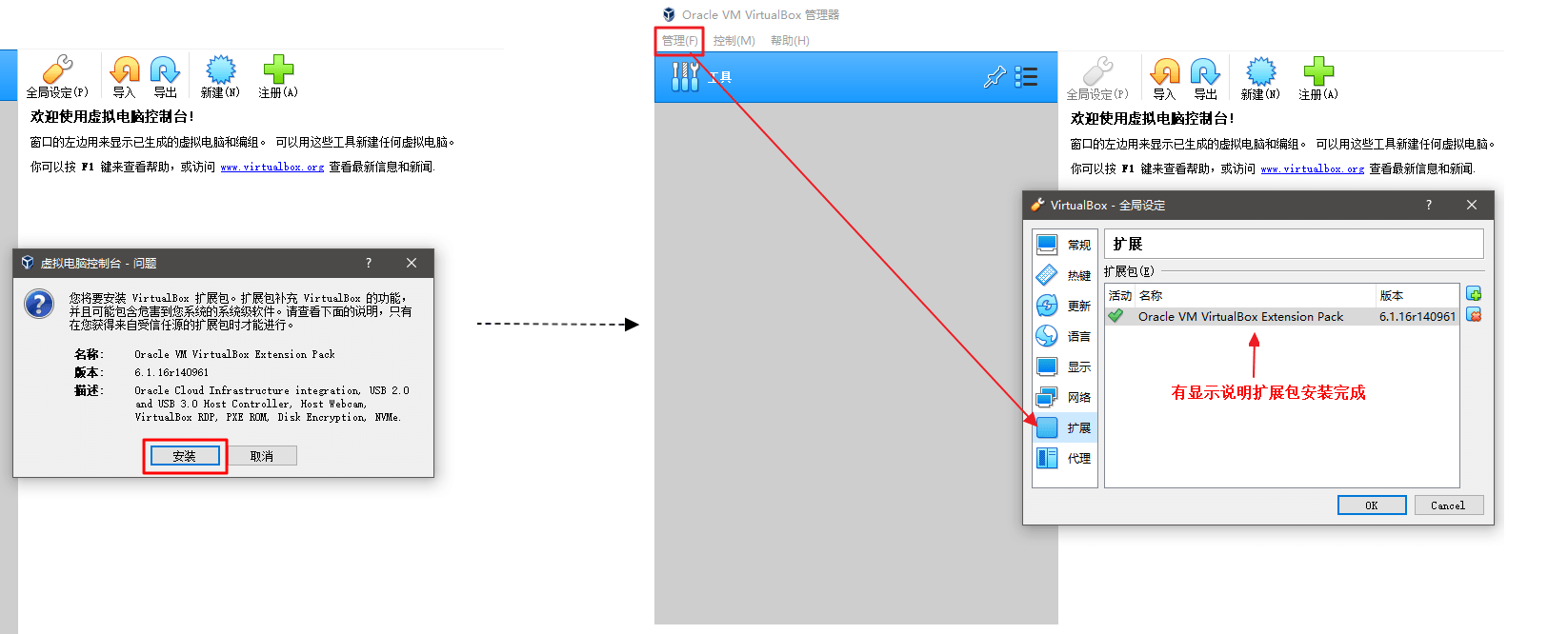
选择你需要下载的版本 (32位系统请务必选择5.2)。这里我的是 64 位系统,选择最新版 (下图左半图红框)。单击进入文件选择界面(下图右半图)选择文件下载,其中一个是 VirtualBox 主体安装包,一个是 扩展包,扩展包必须和 VirtualBox 主体安装包版本保持一致(后缀140961也要一样)。
- 扩展包提供了对USB 2.0、USB 3.0、远程桌面协议 VRDP(VirtualBox Remote Desktop Protocol)等实用功能的支持。但相关扩展包并非开源软件,而是在 VirtualBox Personal Use and Evaluation License (PUEL) 许可证限制下发布的软件,所以扩展包并未与 VirtulBox 安装文件集成在一起,而是需要单独下载和安装。

安装
上述两个文件下载完成后,先双击运行 VirtualBox-6.1.16-140961-Win.exe 安装VirtualBox。安装过程全程按照提示进行,点击下一步,遇到弹窗,点选 “是” 或 “安装” 即可。可以更改软件安装位置。
VirtualBox安装后。双击 Oracle_VM_VirtualBox_Extension_Pack-6.1.16.vbox-extpack 安装扩展包。(下图左半图)。安装完成后,运行 VirtualBox,在左上角 管理 -> 全局设定 -> 扩展,确认扩展包安装成功。
新建虚拟机
虚拟机,相当于一台虚拟的电脑,用于后面的 Ubuntu 操作系统安装。
单击新建
虚拟机配置
名称: 随意
文件夹: 存放虚拟机的配置文件,区别与存放Ubuntu操作系统的文件夹。随意。
类型: Linux
版本: Ubuntu(64-bit)
内存大小: 一般是本机的一半,例如你电脑是16G内存,这里就选8G
勾选现在创建虚拟硬盘,点击创建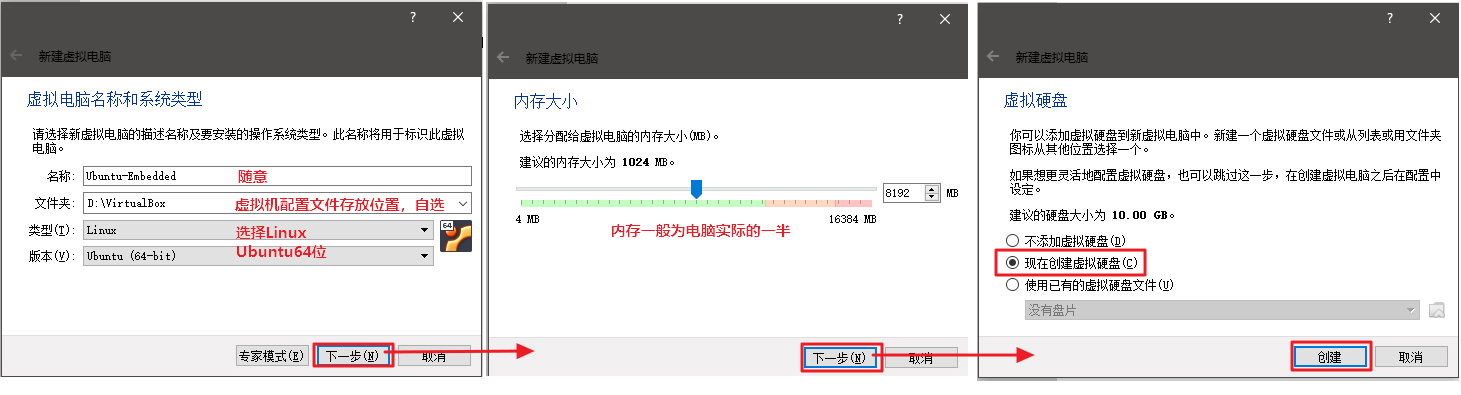
创建虚拟硬盘
建议单独创建一个电脑硬盘分区,且大小最好在100G以上,用来安装 LInux 操作系统,学习中可能会经常格式化。
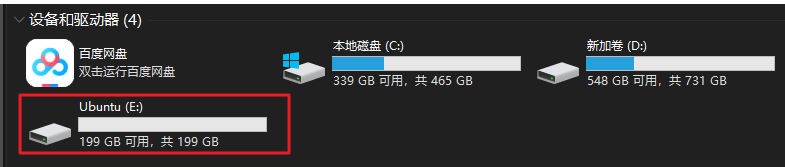
虚拟硬盘文件类型:VDI
内存分配:固定大小。
文件位置和大小:文件位置就选择我们上面新建的分区,大小剩5-10G作用,用于存放我们的ubuntu映像文件(即.iso文件)
点击创建,配置完毕,等待软件自动创建完成。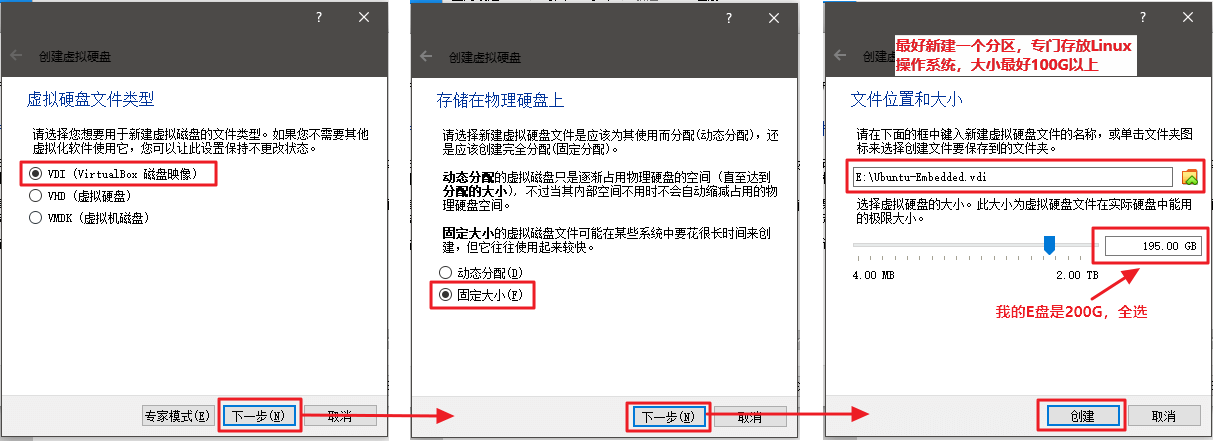
虚拟机创建完成的样子
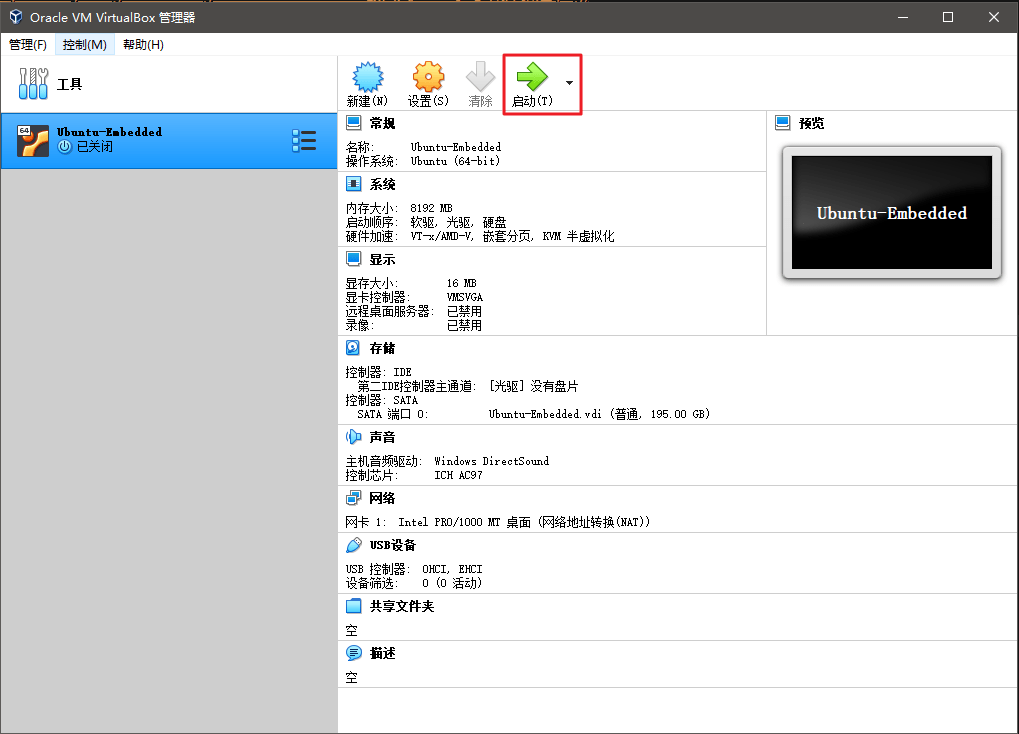
2. Ubuntu安装
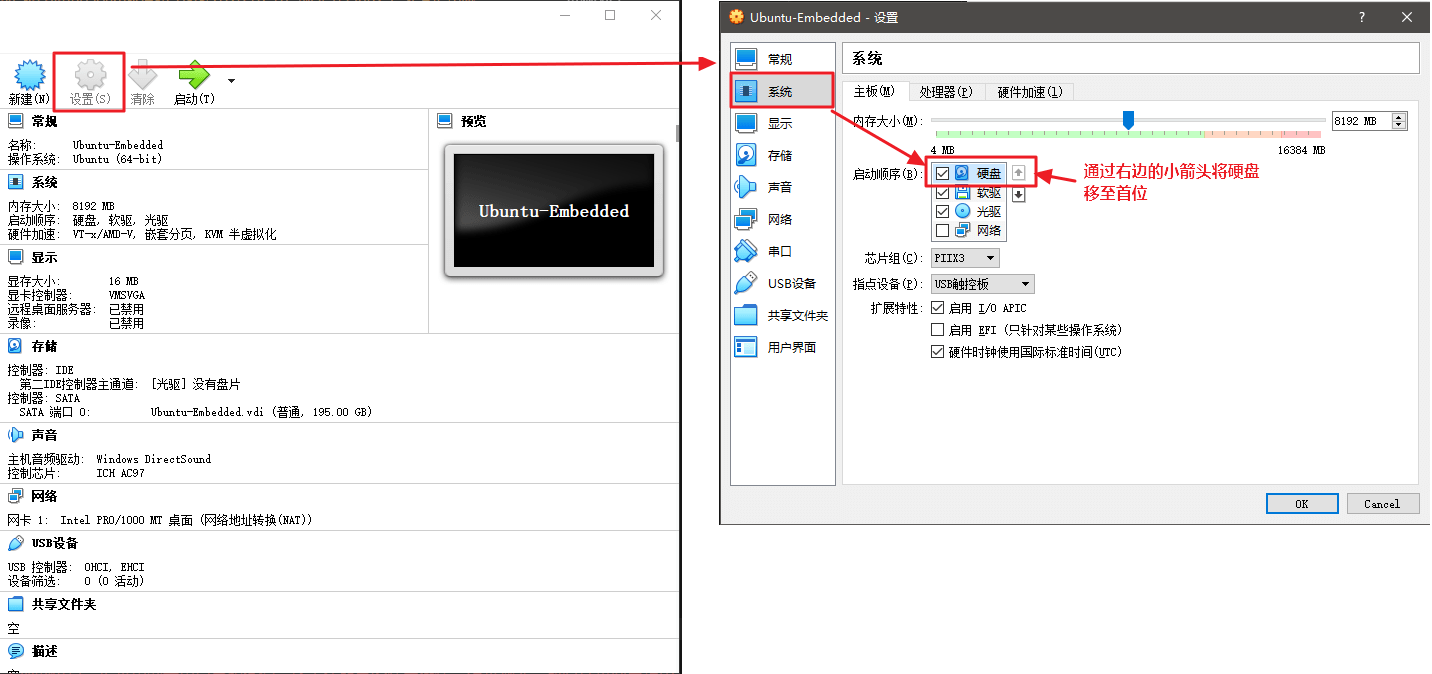
修改启动顺序。设置 -> 系统,将硬盘移到首位。不然会默认使用光驱启动,这会导致下面系统安装成功后会又进入系统安装界面。
下载 Ubuntu,进入Ubuntu 阿里云镜像下载,下载 18.04.5 版。建议放在我们之前新建的磁盘分区中即E盘下,后面可能会涉及频繁重装系统,所以 iso 文件最好不要删。
不推荐下载最新版,软件适配不足,bug较多。资料较少。还是下载老版本。–20201207
后面教程中版本都是 20.04.1(写教程时一开始使用的最新版,后面出现很多问题,亲身教训)。实际以 18.04.5 版本为准
点击
启动选择启动盘

点击注册,在弹出界面选择我们第一步下载好的 ISO 文件
点击选择
点击启动
等待安装启动,语言选择
English(个人推荐,程序员应该拥抱英语),然后选择install Ubuntu- 选择英文,后面会涉及输入法无法写中文的问题,需要在系统中安装语言包。如果怕麻烦,这里可以选中文,安装时系统会自动安装。
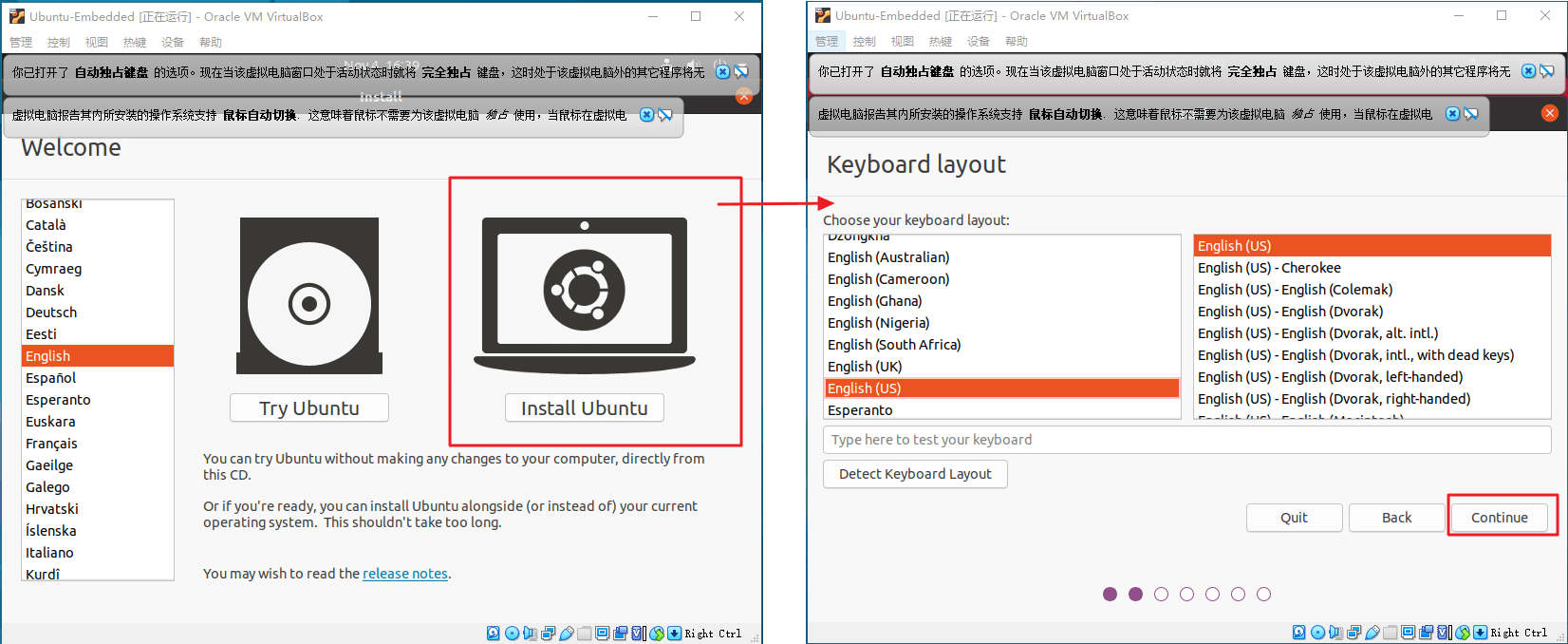
- 选择英文,后面会涉及输入法无法写中文的问题,需要在系统中安装语言包。如果怕麻烦,这里可以选中文,安装时系统会自动安装。
选择
Nomal installation,安装时更新(系统自带的软件更新)可以不勾选,安装时间会加长,建议勾选。点击继续。
安装类型选择擦除磁盘并安装。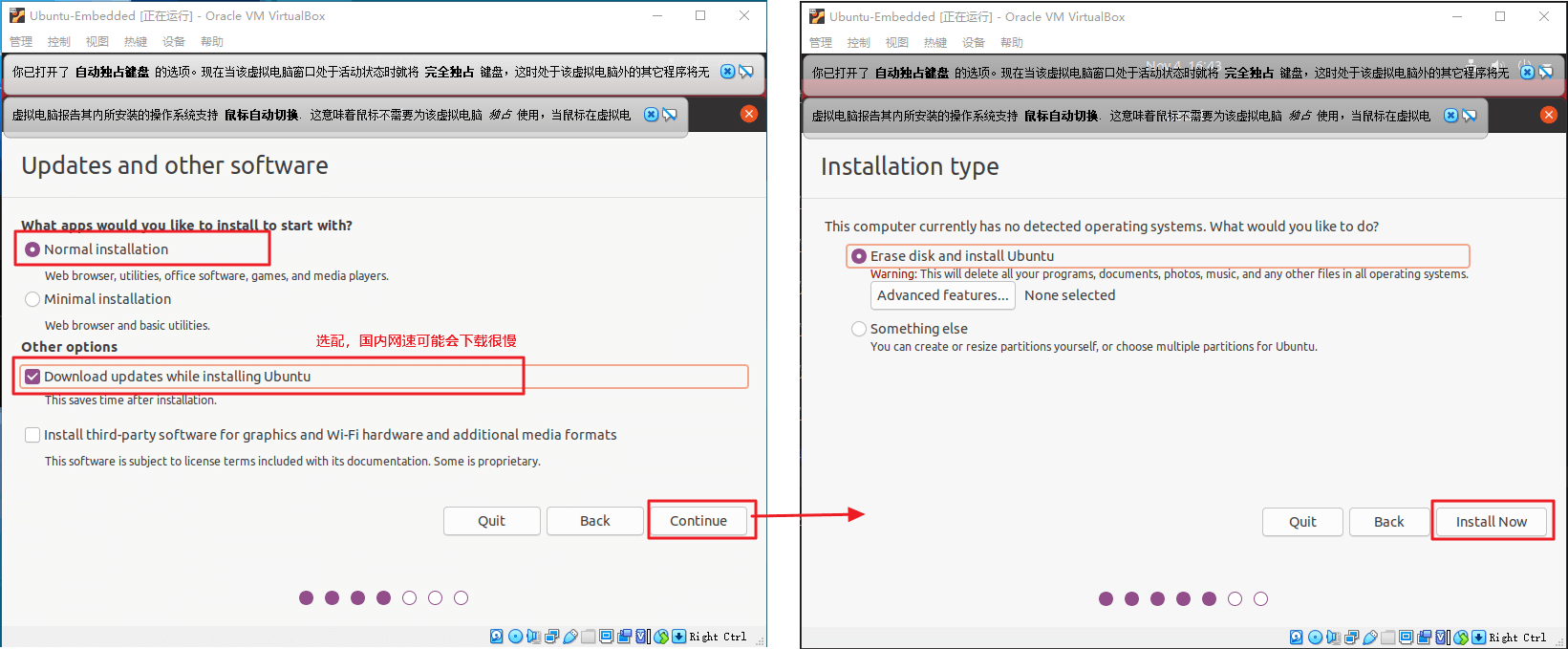
写入磁盘。弹窗里点击继续。
时区正常选择中国时区就可以,继续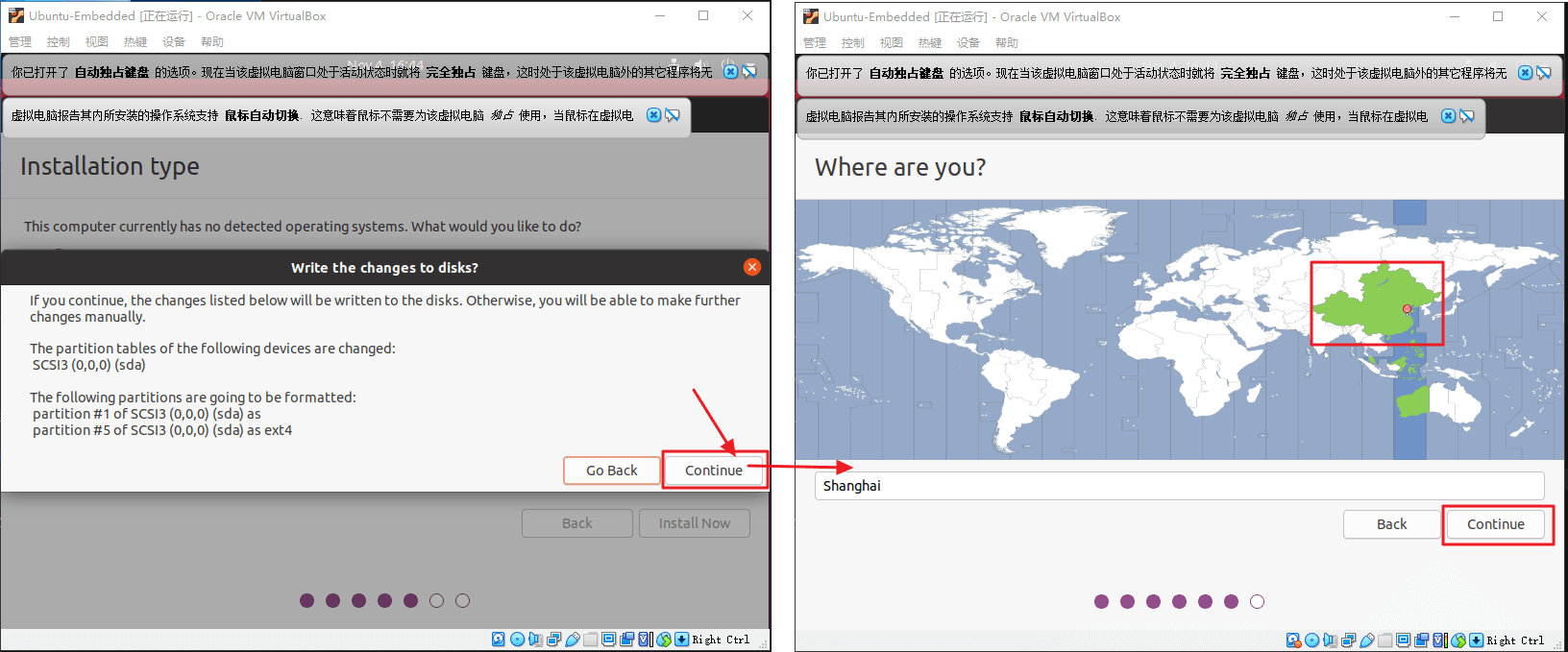
设置用户名和密码。又图是其会出现的位置。最常用的是用户名和密码,这个在命令终端中操作会经常输入,所有尽量简单短小。
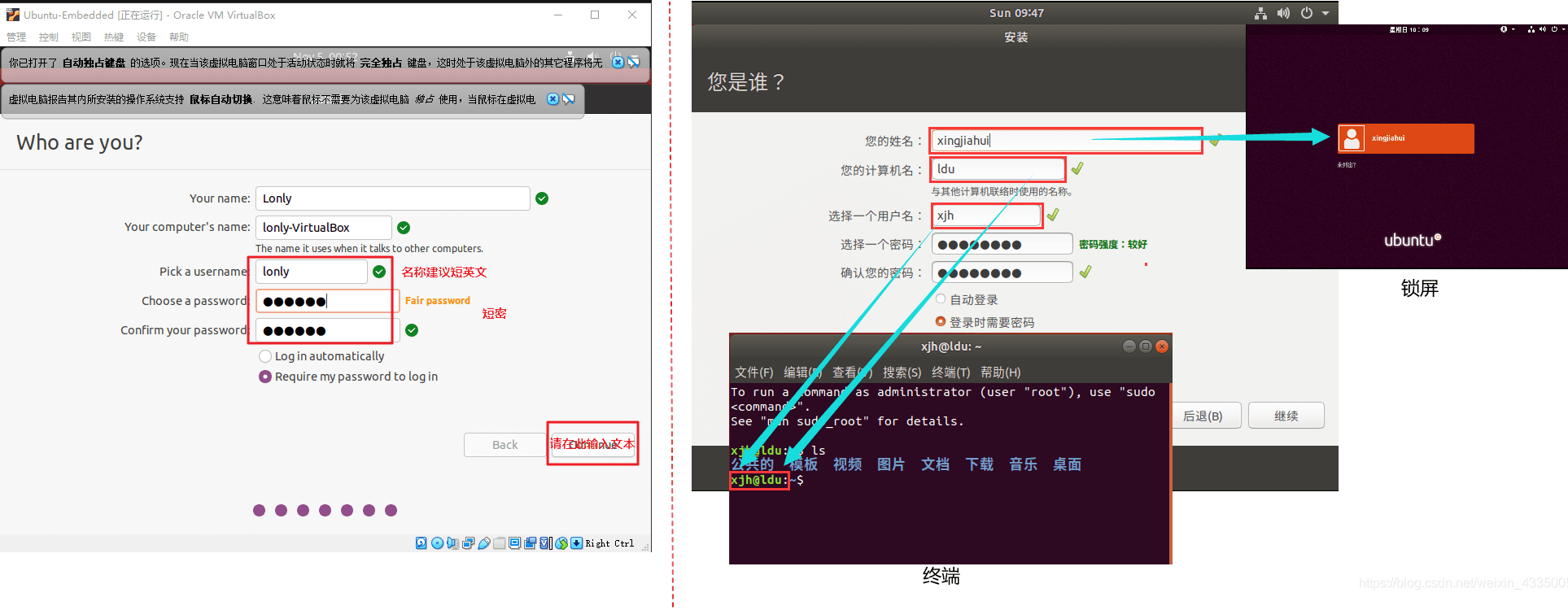
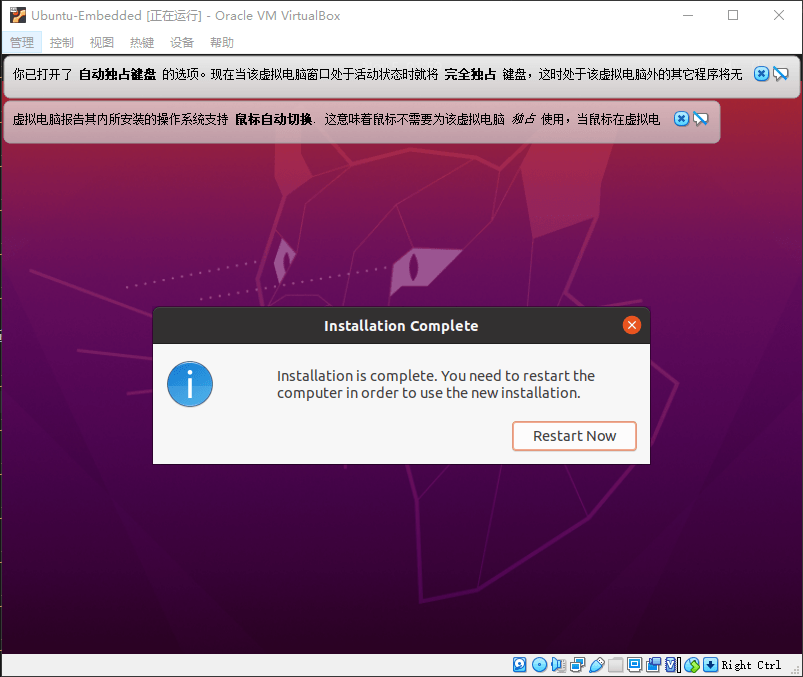
接下来就是漫长的安装过长,我这里大概用了2小时。出现下面弹窗表示安装完成,点击重新启动即可。
参考资料
3. Ubuntu配置
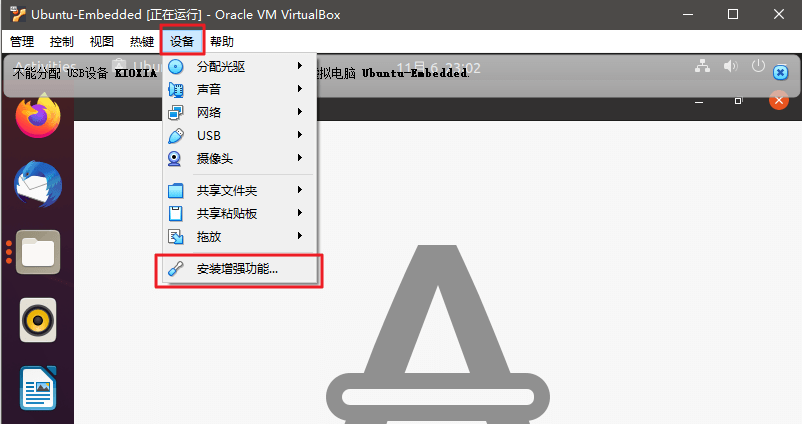
增强扩展功能
安装增强扩展功能。解决以下问题:
- 更改屏幕分辨率,解决显示界面太小问题
- 本地电脑和虚拟机电脑文件共享
- 剪贴板共享等等等等
- 设备->安装增强功能
- 弹窗点击
Run,输入密码。(数字小键盘关闭可能会无法输入。)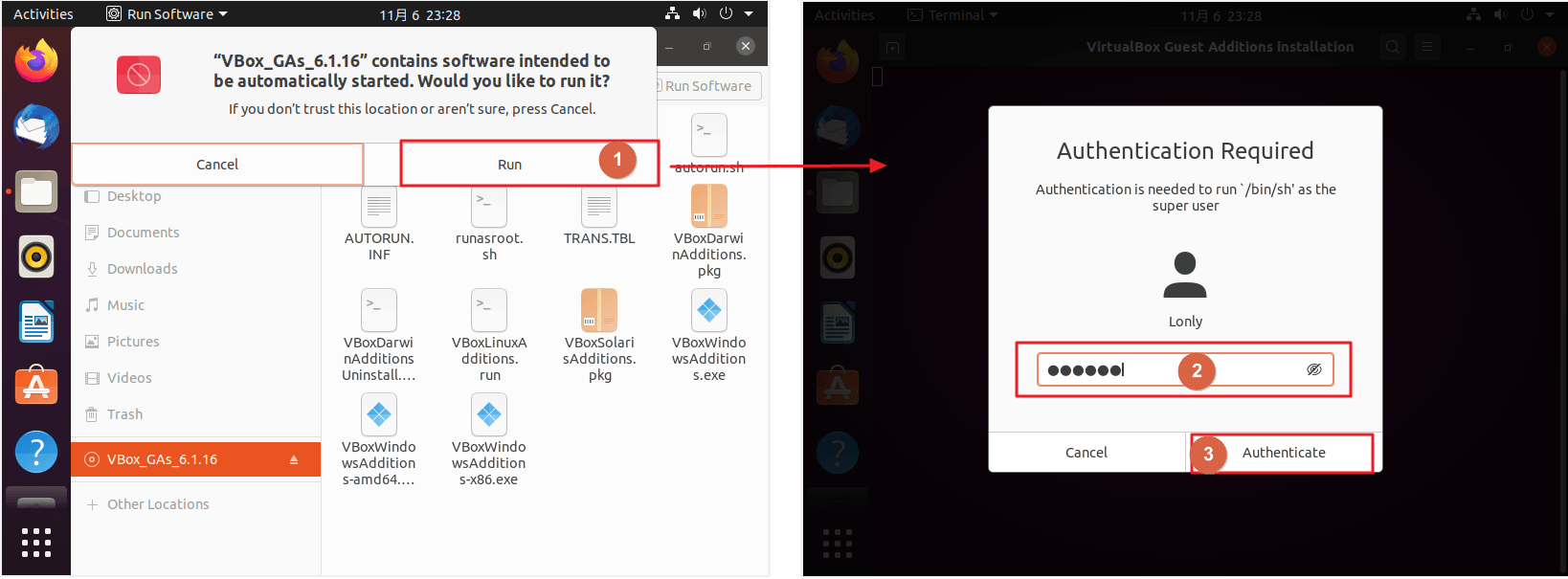
- 不出意外的话,会出现下左图的安装失败。我们需要打开终端,并输入
sudo apt-get install build-essential gcc make perl dkms
等待系统自动安装,再重新安装增强功能。直到出现下右图表示安装成功。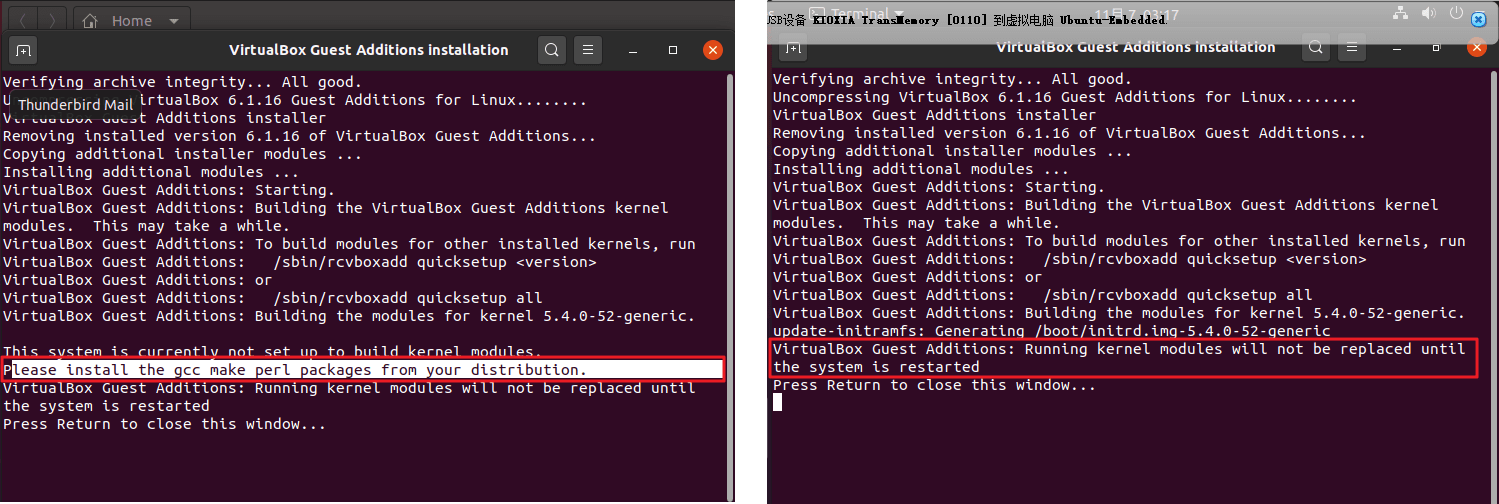
安装失败后,桌面会多出一个 iso 文件,双击打开,点击运行,就可以直接安装增强功能,不用再从菜单栏选择了。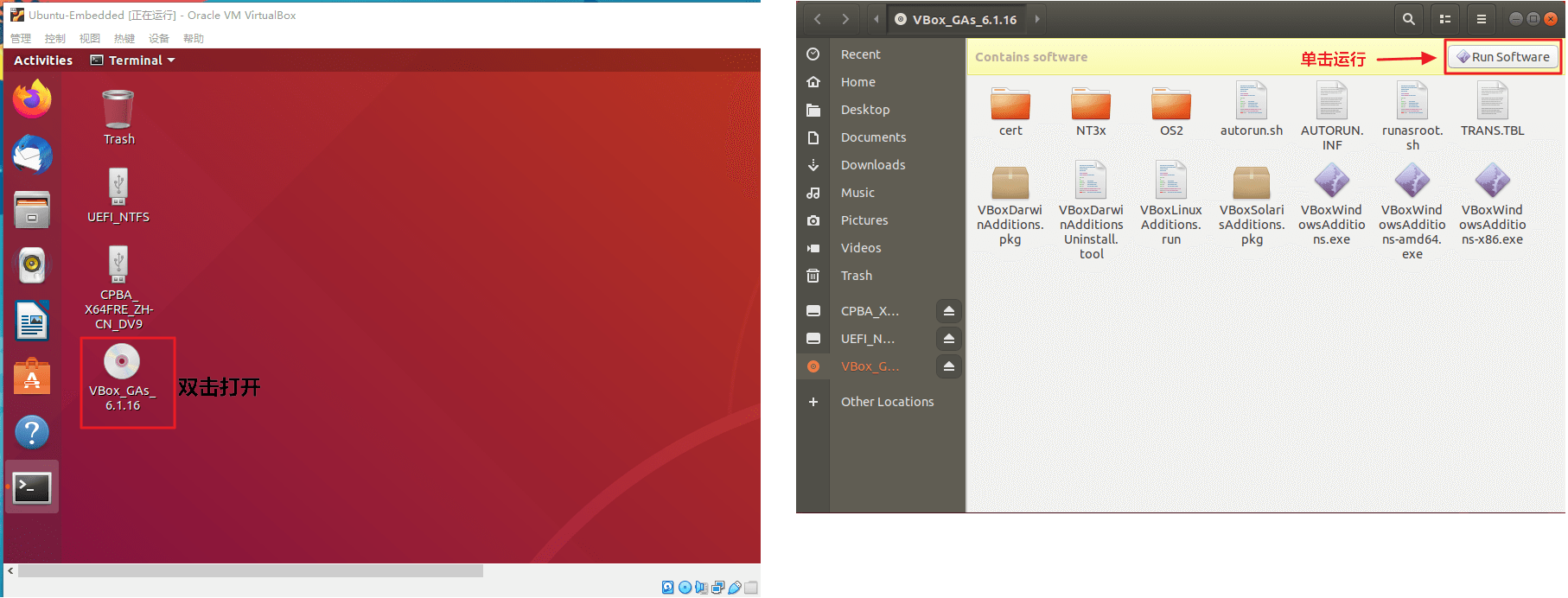
- 关闭虚拟机,在virtualbox主界面打开
设置:常规->高级:共享剪切板 和 拖拽都 选择 双向存储->控制器SATA:勾选 使用主机输入输出(I/O)缓存存储->控制器SATA->Ubuntu-Embeded.vdi:勾选 固态驱动器
启动虚拟机。此时就可以直接从 Windows 系统窗口拖动文件到 Linux 界面了。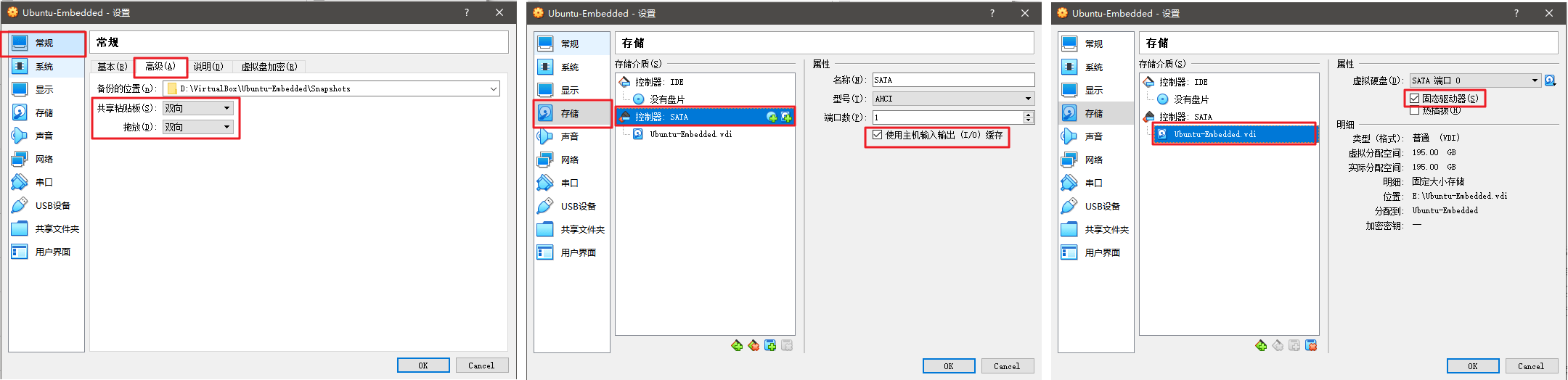
- 更改分辨率。在设置里找到系统设置,选择合适的屏幕分辨率即可。
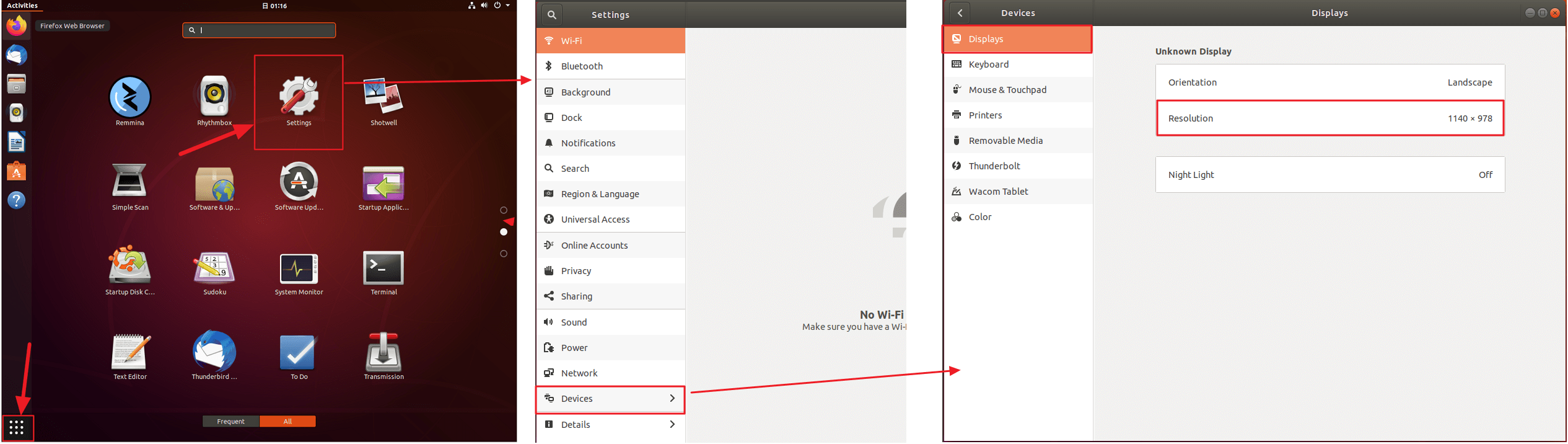
参考链接
Ubuntu 使用 apt 进行软件包安装管理,默认情况下其使用国外的软件源进行软件包的下载/安装/更新等操作。而由于不可抗力,这些下载操作可能会很慢。此时可以采用国内的镜像软件源替换 Ubuntu 的默认软件源,提高软件更新下载速度。
- 打开 Software&Updates -> Ubuntu Software,其界面有个 Download from 项,找到 China 项,会有很多源,选择其中一个即可。
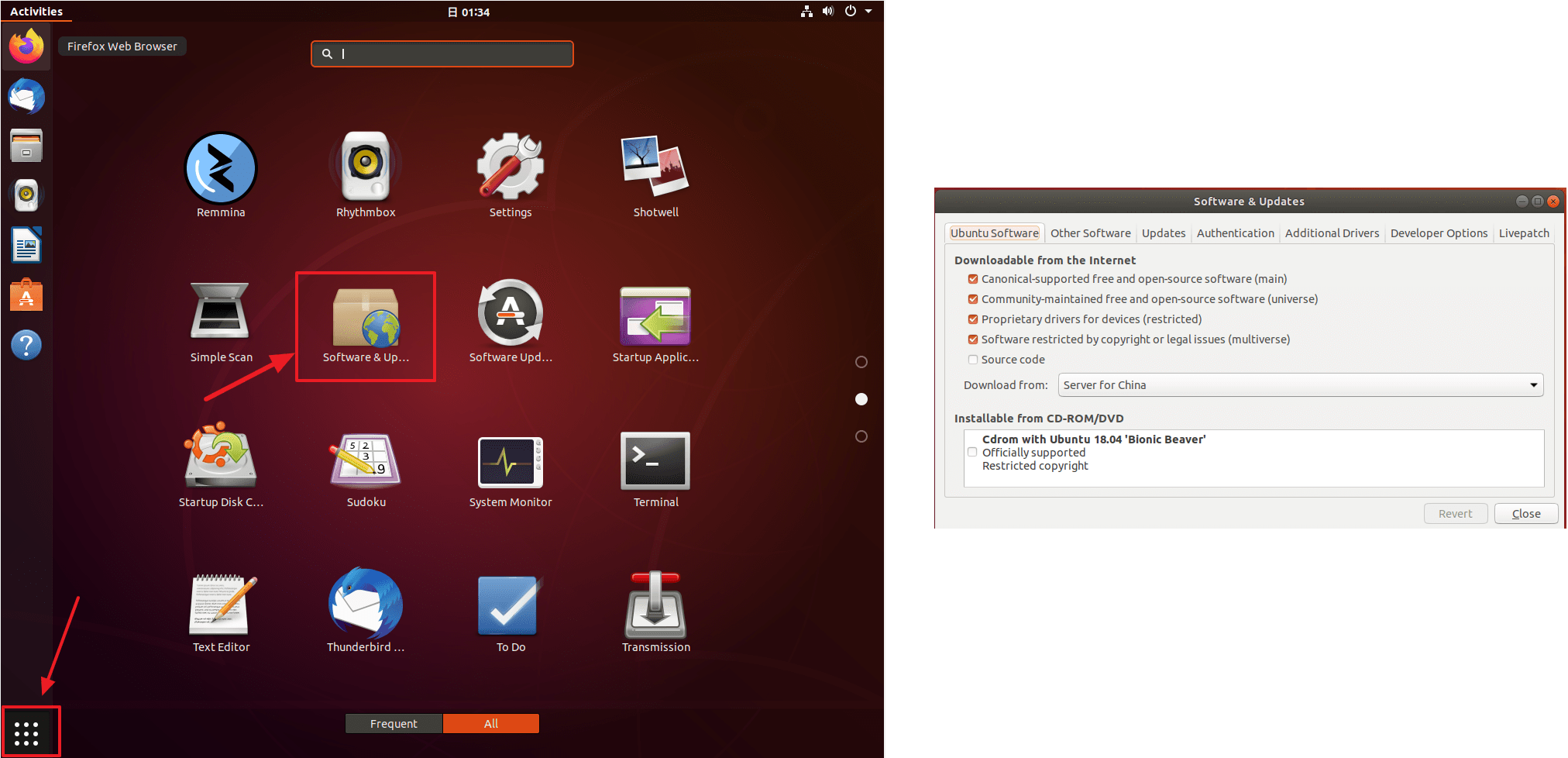
参考资料
U盘支持
我们也希望能在 LInux 系统中读取电脑上的 usb 设备。此时就发挥我们之前安装的扩展包作用了。
- 这里实测,不安装扩展包,也是可以使用 usb3.0 的hub识别usb2.0读卡器读写SD卡
- 关闭虚拟机,virtualbox主界面打开
设置->USB设备,勾选USB 3.0。并将USB设备添加进来(只有添加进这里的才能在虚拟机中被识别到)。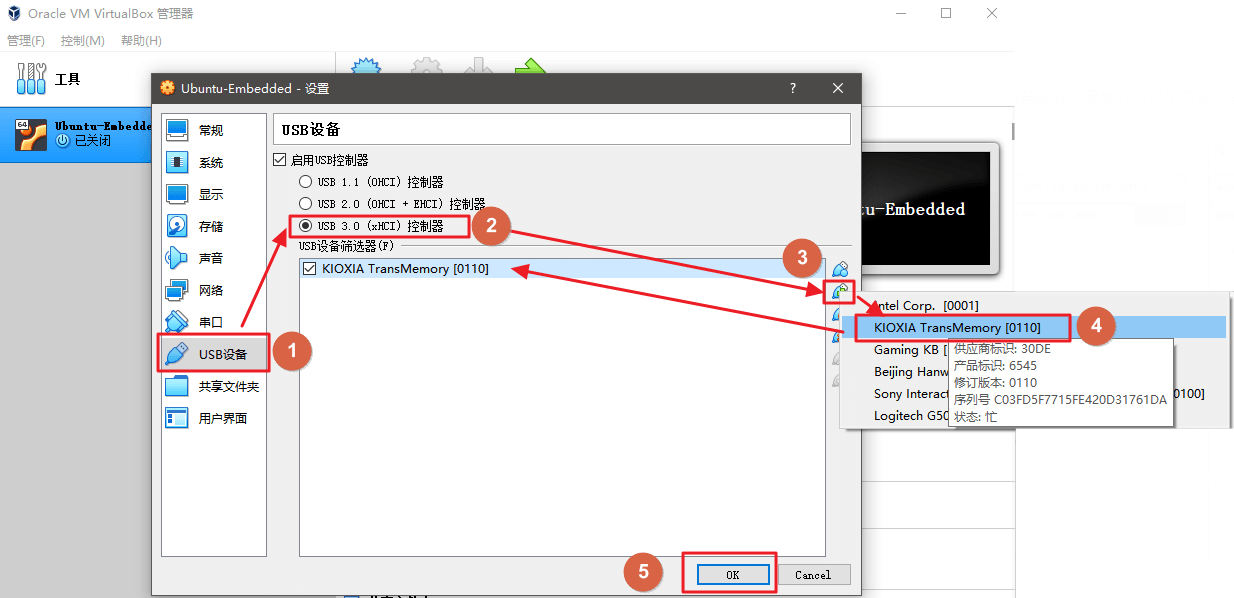
- 打开虚拟机,一般会自动加载设备(左下角两个设备图标),直接双击即可打开。如果没有:
设备->USB,单击USB设备名字,将完成设备加载。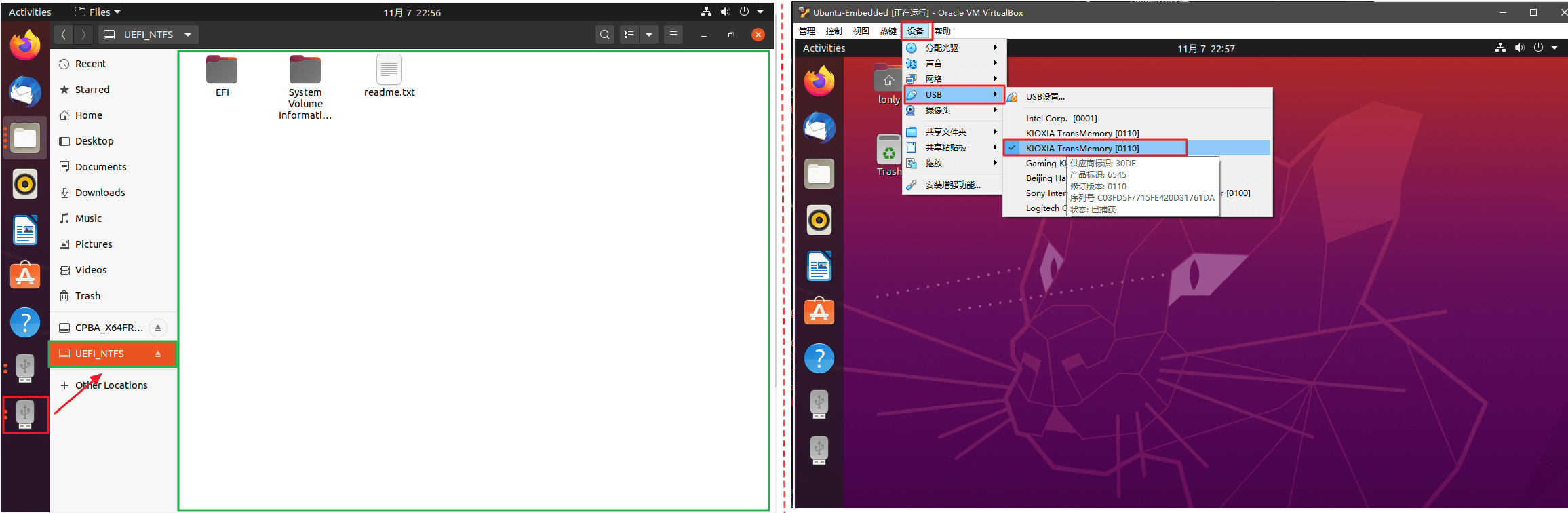
- 移除设备,右键左下角设备图标,单击
Eject弹出;或者虚拟机右下角,右键U盘图标,单击设备名弹出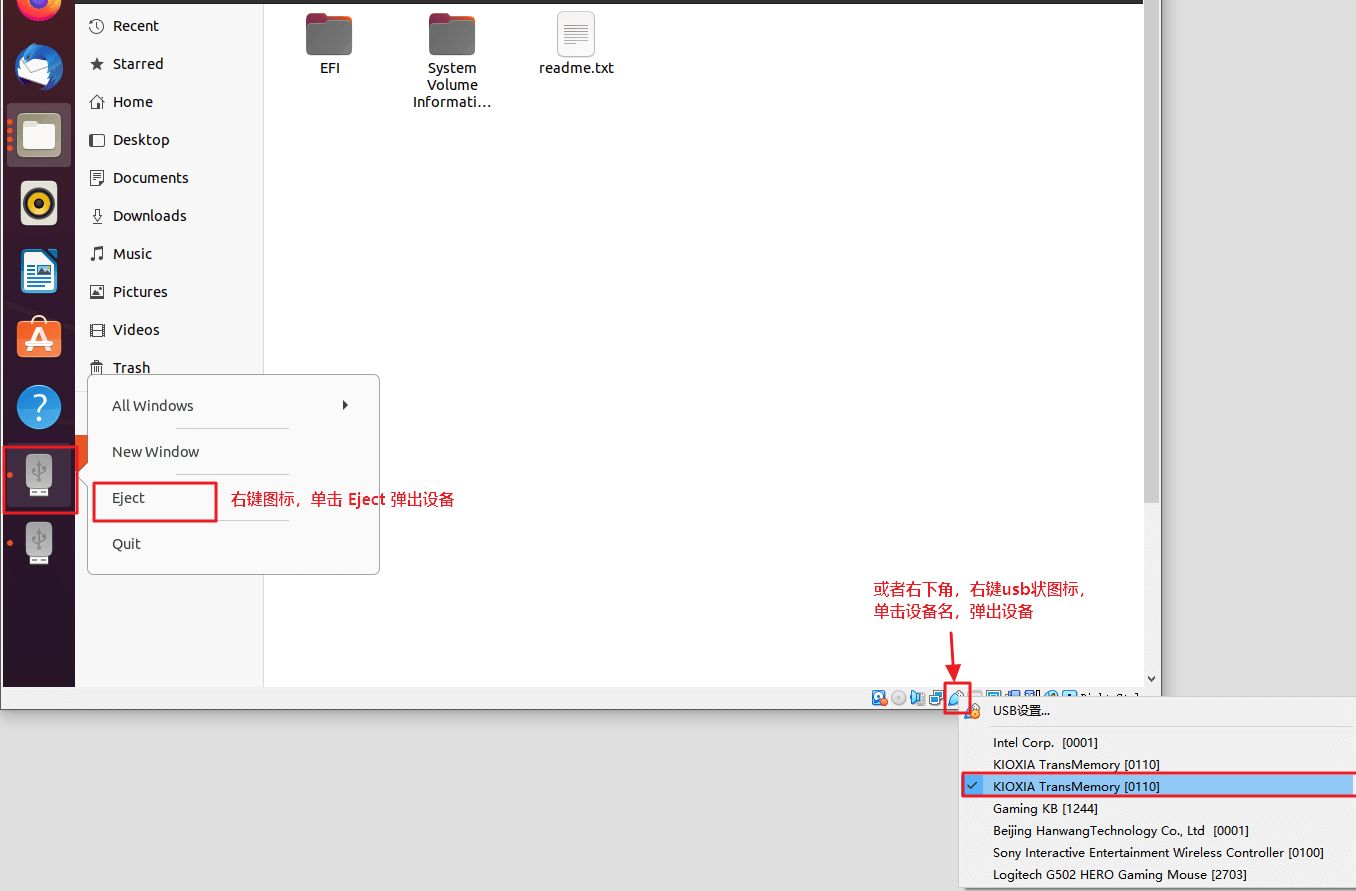
参考链接
图标对齐
虽然LInux基本都是命令行操作,但桌面有时也会偶尔存放东西。默认拖动到桌面的文件图标会堆叠在一起,不像 Windows 或自动整理、对齐。其实这里需要我们自己选择。在桌面右键:
- keep aligned:保持对齐
- Organize Desktop by Name:按名称排序桌面
锁屏
Ubuntu默认5分钟自动锁屏,我们希望永不锁屏,打开设置界面,找到Power,设置自己的时间即可。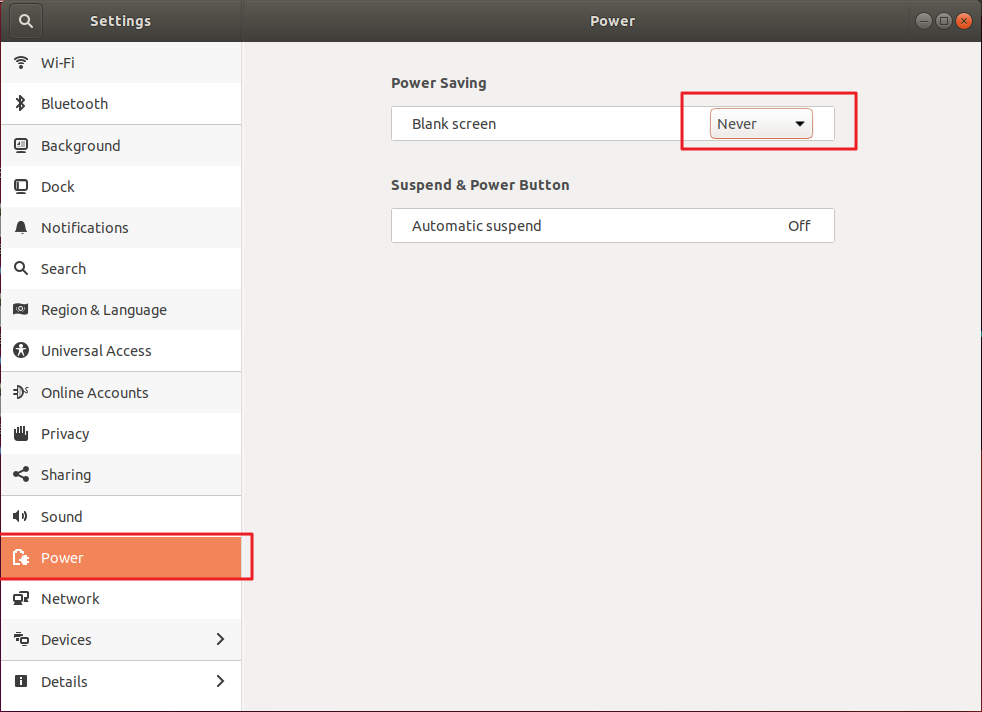
参考链接
- virtualbox虚拟机使用教程
- Oracle VM VirtualBox 使用教程(Windows操作系统下)
- 优麒麟使用教程第二期:VirtualBox 虚拟机安装
- win10虚拟机Oracle VM VirtualBox安装和使用教程
- 虚拟框 / Windows 10 主机 / 文件位置
- 一张图搞懂Ubuntu安装时姓名、计算机名、用户名
- https://zhuanlan.zhihu.com/p/35619204
- https://www.jianshu.com/p/796866e933e1
- https://segmentfault.com/a/1190000022468063
- https://www.codeleading.com/article/61115145053/
三、Ubuntu系统入门
shell命令
命令区分大小写
查询一个命令:man xx 或者 xx –help
q键退出当前操作* 为通配符
重复执行上条命令的 4 种方法:
- 使用上方向键,并回车执行。(推荐)
- 按 Ctrl+P 并回车执行。(备选,有的命令上下键会没有,这个绝对会有)
- 按 !! 并回车执行。
- 输入 !-1 并回车执行。
- !$ 使用上一个命令的参数
参考链接
cd 切换目录
changeDirectorym,这是一个非常基本、经常需要使用的命令,它用于切换当前目录,它的参数是要切换到的目录的路径,可以是绝对路径,也可以是相对路径。如:
1 | |
- “.” 表示当前目录 ,其实就是使用 “.” 代替了当前目录的目录名
- “..” 表示上一层目录
- “/“ 在首位表示根目录,其它位置后面表示其目录下
1
2
3lonly@lonly-VirtualBox:~$ cd ~
lonly@lonly-VirtualBox:~$ cd / # 默认用户目录 '$' 为 '~' 符号
lonly@lonly-VirtualBox:/$ # 根目录 '$' 为 '/' 符号
ls 查看文件与目录
list ,查看文件与目录的命令,它的参数非常多,下面就列出一些我常用的参数吧,如下:
1 | |
uname 显示系统相关信息
Unix name,用于显示系统相关信息,比如主机名、内核版本号、硬件架构等。
1 | |
clear 清除屏幕
clear命令用于清除屏幕。这个命令将会刷新屏幕,本质上只是让终端显示页向后翻了一页,如果向上滚动屏幕还可以看到之前的操作信息。
cat 查看文本
该命令用于查看文本文件的内容,后接要查看的文件名cat [参数] [文件]
1 | |
sudo 超级用户
允许一个已授权用户以超级用户或者其它用户的角色运行一个命令。
1 | |
举例:sudo xxx指令 # 以超级用户(管理员)执行该指令,临时切换当前身份 sudo su # 切换身份为超级用户(永久),不建议这么做,可能会误删除一些系统核心文件,导致系统崩溃
cp 复制文件
copy,该命令用于复制文件,它还可以把多个文件一次性地复制到一个目录下, 常用参数如下:
1 | |
举例:cp -a file1 file2 #连同文件的所有特性把文件file1复制成文件file2cp file1 file2 file3 dir #把文件file1、file2、file3复制到目录dir中,以默认 "-i" 方式
touch 创建新的空文件
touch命令有两个功能:一是创建新的空文件,二是改变已有文件的时间戳属性。
touch命令会根据当前的系统时间更新指定文件的访问时间和修改时间。如果文件不存在,将会创建新的空文件,除非指定了”-c”或”-h”选项。
1 | |
rm 删除文件或目录
remove,该命令用于删除文件或目录,它的常用参数如下:
1 | |
举例:rm -i file # 删除文件file,在删除之前会询问是否进行该操作rm -fr dir # 强制删除目录dir中的所有文件
mkdir 创建目录
make directories创建目录。
1 | |
实例mkdir test # 创建名为 test 的目录mkdir dir1 dir2 dir3 # 同时创建子目录dir1,dir2,dir3mkdir -p linuxcool/dir # 同时创建目录linuxcool,并在linuxcool目录下创建子目录dir
rmdir 删除空目录
remove directory,删除空的目录
注意: rmdir命令只能删除空目录。当要删除非空目录时,就要使用带有 “-r” 选项的rm命令。
1 | |
mv 移动文件
move,用于移动文件、目录或更名,常用参数如下:
1 | |
注:该命令可以把一个文件或多个文件一次移动一个文件夹中,但是最后一个目标文件一定要是“目录”。
实例:mv file1 file2 file3 dir # 把文件file1、file2、file3移动到目录dir中mv file1 file2 # 把文件file1重命名为file2mv test/ test1/ # 重命名文件夹mv a.c test1/ # 将 a.c 移动到 test1 文件夹下
ifconfig 网络配置
network interfaces configuring,配置和显示Linux内核中网络接口的网络参数。用ifconfig命令配置的网卡信息,在网卡重启后机器重启后,配置就不存在。要想将上述的配置信息永远的存的电脑里,那就要修改网卡的配置文件了。
1 | |
reboot 重启
用于用来重新启动计算机,和Windows系统中的restart一样。但是机器重启必须要root用户才有权限。
1 | |
poweroff 断电
关闭计算机操作系统并且切断系统电源。如果确认系统中已经没有用户存在且所有数据都已保存,需要立即关闭系统,可以使用poweroff命令。
1 | |
sync 数据同步
在Linux/Unix系统中,在文件或数据处理过程中一般先放到内存缓冲区中,等到适当的时候再写入磁盘,以提高系统的运行效率。
sync命令则可用来强制将内存缓冲区中的数据立即写入磁盘中。用户通常不需执行sync命令,系统会自动执行update或bdflush操作,将缓冲区的数据写 入磁盘。只有在update或bdflush无法执行或用户需要非正常关机时,才需手动执行sync命令。
find 查找文件
find是一个基于查找的功能非常强大的命令,相对而言,它的使用也相对较为复杂,参数也比较多,所以在这里将给把它们分类列出,它的基本语法如下:find [PATH] [option] [action]
与时间有关的参数:
1 | |
例如:find ./ -mtime 0 # 在当前目录下查找今天之内有改动的文件
与用户或用户组名有关的参数:
1 | |
例如:find /home/lonly -user lonly # 在目录/home/ljianhui中找出所有者为ljianhui的文件
与文件权限及名称有关的参数:
1 | |
例如:find / -name passwd # 查找文件名为passwd的文件find ./ -name '*.log' # 在当前目录查找 以 .log 结尾的文件。 . 代表当前目录find . -perm 0755 # 查找当前目录中文件权限的0755的文件find . -size +12k # 查找当前目录中大于12KB的文件,注意c表示byte
grep查找内容
global search regular expression and print out the line,用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。
grep命令的选项用于对搜索过程的补充,而其命令的模式十分灵活,可以是变量、字符串、正则表达式。需要注意的是:当模式中包含了空格,务必要用双引号将其引起来。grep [参数][-A<显示列数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...]
它的常用参数如下:
1 | |
实例
1 | |
1 | |
1 | |
du 查看文件大小
Disk Usage,即用于查看磁盘占用空间的意思。但是与df命令不同的是du命令是对文件和目录磁盘使用的空间的查看,而不是某个分区。
1 | |
实例
1 | |
df 可使用的磁盘空间
Disk Free,用于显示系统上可使用的磁盘空间。默认显示单位为KB,建议使用“df -h”的参数组合,根据磁盘容量自动变换合适的单位,更利于阅读。
日常普遍用该命令可以查看磁盘被占用了多少空间、还剩多少空间等信息。
1 | |
实例
1 | |
gedit 官方文本编辑器
gedit命令是GNOME桌面环境的官方文本编辑器,尽管gedit旨在简化和易用,但它是功能强大的通用文本编辑器;它可以用来创建和编辑各种文本文件。和 notepad 类似。
1 | |
ps 显示当前系统的进程状态
process status,显示当前系统的进程状态。可以搭配 kill 指令随时中断、删除不必要的程序。
ps命令是最基本同时也是非常强大的进程查看命令,使用该命令可以确定有哪些进程正在运行和运行的状态、进程是否结束、进程有没有僵死、哪些进程占用了过多的资源等等,总之大部分信息都是可以通过执行该命令得到的。
1 | |
其实我们只要记住ps一般使用的命令参数搭配即可,它们并不多,如下:
1 | |
kill 删除执行中的程序或工作
linux系统中kill命令用来删除执行中的程序或工作。
kill命令可将指定的信号发送给相应的进程或工作。 kill命令默认使用信号为15,用于结束进程或工作。如果进程或工作忽略此信号,则可以使用信号9,强制杀死进程或作业。
语法格式:kill [参数] [进程号]
1 | |
实例
1 | |
file 识别文件类型
file命令用来识别文件类型,也可用来辨别一些文件的编码格式。因为在Linux下文件的类型并不是以后缀为分的,所以这个命令对我们来说就很有用了,它的用法非常简单,基本语法如下:file filename
top 显示系统中各个进程的资源占用状况
Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,常用于服务端性能分析。
在 top 命令中按 f按可以查看显示的列信息,按对应字母来开启/关闭列,大写字母表示开启,小写字母表示关闭。带*号的是默认列。
1 | |
实例
1 | |
gcc命令
gcc命令使用GNU推出的基于C/C++的编译器,是开放源代码领域应用最广泛的编译器,具有功能强大,编译代码支持性能优化等特点。现在很多程序员都应用gcc,目前gcc可以用来编译C/C++、FORTRAN、JAVA、OBJC、ADA等语言的程序,可根据需要选择安装支持的语言。
1 | |
实例
1 | |
Ubuntu 软件安装
1、软件商店安装
2、 sudo apt-get
直接使用该命令在线下载并自动安装软件。sudo apt-get install git # 安装 get 工具
3. deb 软件包
类似windows下的 .exe 安装包。要先去官网下载软件的 .deb 安装包。
1 | |
4、源码编译
一般下下载好软件的源码并解压,进入到源码根目录下,执行
1 | |
安装命令各软件不尽相同,这里仅举一般例子说明
Ubuntu 文件系统结构
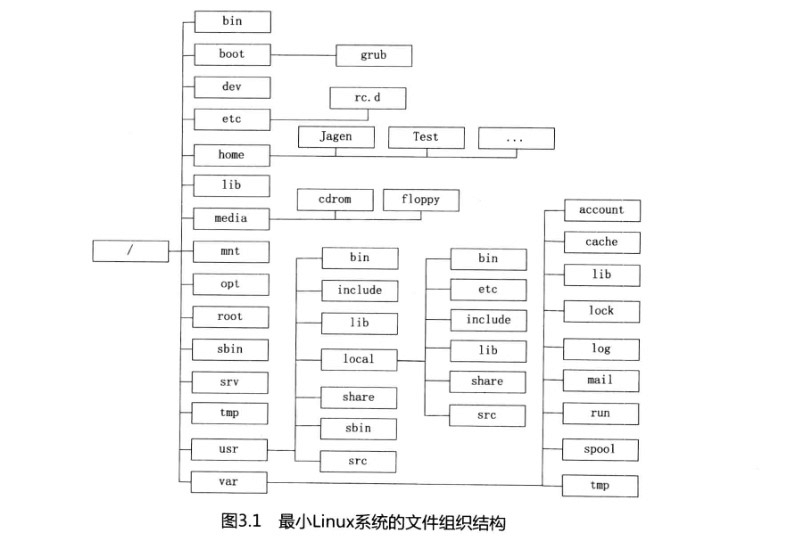
/bin:
bin 是 Binaries (二进制文件) 的缩写, 这个目录存放着最经常使用的命令。存放着最常用的程序和指令
/sbin:
s 就是 Super User 的意思,是 Superuser Binaries (超级用户的二进制文件) 的缩写,这里存放的是系统管理员使用的程序和指令。
/boot:
这里存放的是启动 Linux 时使用的一些核心文件,包括一些连接文件以及镜像文件。
/dev :
dev 是 Device(设备) 的缩写, 该目录下存放的是 Linux 的外部设备,在 Linux 中访问设备的方式和访问文件的方式是相同的。
/etc:
etc 是 Etcetera(等等) 的缩写,这个目录用来存放所有的系统管理所需要的配置文件和子目录。更改目录下的文件可能会导致系统不能启动。
/home:
用户的主目录,在 Linux 中,每个用户都有一个自己的目录,一般该目录名是以用户的账号命名的,如上图中的 alice、bob 和 eve。
/lib:
lib 是 Library(库) 的缩写这个目录里存放着系统最基本的动态连接共享库,其作用类似于 Windows 里的 DLL 文件。几乎所有的应用程序都需要用到这些共享库。
/media:
linux 系统会自动识别一些设备,例如U盘、光驱等等,当识别后,Linux 会把识别的设备挂载到这个目录下。
/mnt:
系统提供该目录是为了让用户临时挂载别的文件系统的,我们可以将光驱挂载在 /mnt/ 上,然后进入该目录就可以查看光驱里的内容了。
/opt:
opt 是 optional(可选) 的缩写,这是给主机额外安装软件所摆放的目录。比如你安装一个ORACLE数据库则就可以放到这个目录下。默认是空的。
/proc:
管理内存空间!proc 是 Processes(进程) 的缩写,/proc 是一种伪文件系统(也即虚拟文件系统),存储的是当前内核运行状态的一系列特殊文件,这个目录是一个虚拟的目录,它是系统内存的映射,我们可以通过直接访问这个目录来获取系统信息。
这个目录的内容不在硬盘上而是在内存里,我们也可以直接修改里面的某些文件,比如可以通过下面的命令来屏蔽主机的ping命令,使别人无法ping你的机器:echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all
/root:
该目录为系统管理员,也称作超级权限者的用户主目录。
/srv:
该目录存放一些服务启动之后需要提取的数据。(不用服务器就是空)
/sys:
这是 Linux2.6 内核的一个很大的变化。该目录下安装了 2.6 内核中新出现的一个文件系统 sysfs 。
sysfs 文件系统集成了下面3种文件系统的信息:针对进程信息的 proc 文件系统、针对设备的 devfs 文件系统以及针对伪终端的 devpts 文件系统。
该文件系统是内核设备树的一个直观反映。
当一个内核对象被创建的时候,对应的文件和目录也在内核对象子系统中被创建。
/tmp:
tmp 是 temporary(临时) 的缩写这个目录是用来存放一些临时文件的。
/usr:
usr 是 unix shared resources(共享资源) 的缩写,这是一个非常重要的目录,用户的很多应用程序和文件都放在这个目录下,类似于 windows 下的 program files 目录。
/usr/bin:
系统用户使用的应用程序。
/usr/sbin:
超级用户使用的比较高级的管理程序和系统守护程序。
/usr/src:
内核源代码默认的放置目录。
/var:
var 是 variable(变量) 的缩写,这个目录中存放着在不断扩充着的东西,我们习惯将那些经常被修改的目录放在这个目录下。包括各种日志文件。
这是一个非常重要的目录,系统上跑了很多程序,那么每个程序都会有相应的日志产生,而这些日志就被记录到这个目录下,具体在 /var/log 目录下,另外 mail 的预设放置也是在这里。
/run:
是一个临时文件系统,存储系统启动以来的信息。当系统重启时,这个目录下的文件应该被删掉或清除。如果你的系统上有 /var/run 目录,应该让它指向 run。
磁盘管理
Linux下,不像Windows可以有C,D,E,多个目录,Linux只有一个根目录/。在装系统时,我们分配给linux的所有区都在/下的某个位置,比如/home等等。
df
该命令上文有说说明,这里更多以实例讲解回顾。
检查文件系统的磁盘空间占用情况。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息。
语法:df [-ahikHTm] [目录或文件名]
实例
将系统内所有的文件系统列出来!默认会将系统内所有的 (不含特殊内存内的文件系统与 swap) 都以 1 Kbytes 的容量来列出来!
1 | |
将容量结果以易读的容量格式显示出来
1 | |
将 /etc 底下的可用的磁盘容量以易读的容量格式显示
1 | |
du
该命令上文有说说明,这里更多以实例讲解回顾。
du命令也是查看使用空间的,但是与df命令不同的是Linux du命令是对文件和目录磁盘使用的空间的查看,还是和df命令有一些区别的,这里介绍Linux du命令。
df不光考虑文件占用空间,还统计被命令和程序占用的空间(又是文件被删除时,只有等其没有被占用时才会真正删除,但磁盘中已经不存在了,属于程序暂用空间)
du命令只计算文件或目录占用的空间
所以,df统计的会大于du统计的。
语法:du [-ahskm] 文件或目录名称
实例
只列出当前目录下的所有文件夹容量(包括隐藏文件夹),直接输入 du 没有加任何选项时,则 du 会分析当前所在目录的文件与目录所占用的硬盘空间。
1 | |
将文件的容量也列出来
1 | |
检查根目录底下每个目录所占用的容量
1 | |
fdisk
Partition table manipulator for Linux,Linux 的磁盘分区表操作工具。 进行硬盘分区从实质上说就是对硬盘的一种格式化, 用一个形象的比喻,分区就好比在一张白纸上画一个大方框,而格式化好比在方框里打上格子。
语法: fdisk [-l] 装置名称
1 | |
菜单操作指令
1 | |
实例
1 | |
进入磁盘sdc,注意这里命令后面不带数字。xvda1/2 其实都是svda这个磁盘的一个分区。好比一个 U 盘的两个分区。那么分区操作肯定时相对于 U 盘 (svda)来说。要进行分区磁盘操作,必须先进入该磁盘目录下。fdisk 硬盘设备名 例如:fdisk /dev/sdb
1 | |
先输入 p 查看磁盘目前分区情况。
- 一个扇区sectors = 512 bytes
- 1GB = 1024MB = 1024 * 1024 KB = 1024 * 1024* 1024 = 1073741824 byte = 1073741824/512 sectors
- 这里的 sectors 在后面新建分区时输入分区大小时会需要
- 下面的英文一定要每个都能看懂并理解输入 d 然后选择分区,删除现有分区:
1
2
3
4
5
6
7
8
9
10
11
12Disk /dev/sdc: 14.6 GiB, 15648948224 bytes, 30564352 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0xf6057dc9
## 笔者注释
## 分区 开始扇区位置 结束位置 扇区大小 字节大小
Device Boot Start End Sectors Size Id Type
/dev/sdc1 2048 6291456 6289409 3G 83 Linux
/dev/sdc2 6293504 30564351 24270848 11.6G 83 Linux查看分区情况,确认已删除。1
2
3
4
5
6
7
8
9Command (m for help): d
Partition number (1,2, default 2): 1
Partition 1 has been deleted.
Command (m for help): d # 当仅有一个分区时,输入 d 直接删除分区,请小心。
Selected partition 2
Partition 2 has been deleted.输入n建立新的磁盘分区,建立两个主磁盘分区:1
2
3
4
5
6
7Command (m for help): p
Disk /dev/sdc: 14.6 GiB, 15648948224 bytes, 30564352 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0xf6057dc9至此两个分区已经建立完成,输入 w 保存1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37Command (m for help): n
Partition type
p primary (0 primary, 0 extended, 4 free) # 主分区
e extended (container for logical partitions) # 扩展分区。关于两者区别请看下文
Select (default p): p # 建立主分区
Partition number (1-4, default 1): 1 # 分区号
First sector (2048-30564351, default 2048): # 回车,默认分区起始位置
Last sector, +sectors or +size{K,M,G,T,P} (2048-30564351, default 30564351): +3G # 分区结束位置,单位为G,注意看本句前面提示
Created a new partition 1 of type 'Linux' and of size 3 GiB.
## 剩余空间再建立一个分区
Command (m for help): n
Partition type
p primary (1 primary, 0 extended, 3 free)
e extended (container for logical partitions)
Select (default p): p
Partition number (2-4, default 2): 2
First sector (6293504-30564351, default 6293504): # 回车,默认
Last sector, +sectors or +size{K,M,G,T,P} (6293504-30564351, default 30564351): # 回车,默认
Created a new partition 2 of type 'Linux' and of size 11.6 GiB.
## 查看分区情况,确认
Command (m for help): p
Disk /dev/sdc: 14.6 GiB, 15648948224 bytes, 30564352 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0xf6057dc9
Device Boot Start End Sectors Size Id Type
/dev/sdc1 2048 6293503 6291456 3G 83 Linux
/dev/sdc2 6293504 30564351 24270848 11.6G 83 Linux
1 | |
建立好分区之后我们还需要对分区进行格式化才能在系统中使用磁盘。
1 | |
建立两个目录,将新建好的两个分区挂载到系统
1 | |
查看分区挂载情况:
1 | |
主分区、扩展分区和逻辑分区
概念
硬盘分区有三种,主磁盘分区、扩展磁盘分区、逻辑分区。这三个术语是针对操作系统而言,主要是从功能上划分的概念。
主分区:
也叫引导分区,一个硬盘主分区至少有1个,最多4个,当创建四个主分区时候,就无法再创建扩展分区了,当然也就没有逻辑分区了。
在windows下激活的主分区是硬盘的启动分区,他是独立的,也是硬盘的第一个分区,正常分的话就是C区。
扩展分区:
分出主分区后,其余的部分可以分成扩展分区,一般是剩下的部分全部分成扩展分区,扩展分区可以没有,最多1个。 且主分区+扩展分区总共不能超过4个。严格地讲它不是一个实际意义的分区,它仅仅是一个指向下一个分区的指针,这种指针结构将形成一个单向链表。这样在主引导扇区中除了主分区外,仅需要存储一个被称为扩展分区的分区数据,通过这个扩展分区的数据可以找到下一个分区(实际上也就是下一个逻辑磁盘)的起始位置,以此起始位置类推可以找到所有的分区。无论系统中建立多少个逻辑磁盘,在主引导扇区中通过一个扩展分区的参数就可以逐个找到每一个逻辑磁盘。
逻辑分区:
但扩展分区是不能直接用的,他是以逻辑分区的方式来使用的,所以说扩展分区可分成若干逻辑分区。 他们的关系是包含的关系,所有的逻辑分区都是扩展分区的一部分。逻辑分区相当于一块存储截止,和操作系统还有别的逻辑分区、主分区没有什么关系,是“独立的”。
补充
给新硬盘上建立分区时都要遵循以下的顺序:建立主分区→建立扩展分区→建立逻辑分区→激活主分区→格式化所有分区。
主分区+扩展分区总共不能超过4个,(扩展分区也可以看成是主分区)其个数是由硬盘的主引导记录MBR(Master Boot Recorder)决定的,MBR存放启动管理程序(如GRUB)和分区表记录。扩展分区下又可以包含多个逻辑分区.
在linux中第一块硬盘分区为hda分区(或者是sda分区),主分区编号为hda1-4,逻辑分区从5开始。
(hd0,0)表示第一块硬盘第一个主分区,(hd1,4)表示第2块硬盘第一个逻辑分区。
硬盘的容量=主分区的容量+扩展分区的容量 扩展分区的容量=各个逻辑分区的容量之和
主分区也可成为“引导分区”,会被操作系统和主板认定为这个硬盘的第一个分区。 所以C盘永远都是排在所有磁盘分区的第一的位置上。
MBR(主引导记录)的分区表(主分区表)只能存放4个分区,如果要分更多的分区的话就要 一个扩展分区表(EBR),扩展分区表放在一个系统ID为0x05的主分区上,这个主分区就是扩展分区, 扩展分区能可以分若干个分区,每个分区都是个逻辑分区
参考链接
磁盘格式化
磁盘分割完毕后自然就是要进行文件系统的格式化,格式化的命令非常的简单,使用 mkfs(make filesystem) 命令。
语法:
1 | |
1 | |
实例 1
查看 mkfs 支持的文件格式
1 | |
将分区 /dev/sdc1 格式化为 vfat (fat32)文件系统:
1 | |
磁盘挂载与卸除
- 提一句Windows下,mount挂载,就是给磁盘分区提供一个盘符(C,D,E,…)。比如插入U盘后系统自动分配给了它I:盘符其实就是挂载,退优盘的时候进行安全弹出,其实就是卸载unmount。
- 插入了新硬盘,分了新磁盘区sdb1。它现在还不属于/。我们虽然可以在一些图形桌面系统里找到他的位置,浏览管理里面的文件,但在命令行却不知怎么访问它的目录,比如无法使用cd或者ls。也无法在编程时指定一个目录对它操作。
- 这时使用了 mount /dev/sdb1
/Share/ ,把新硬盘的区sdb1挂载到工作目录的/Share/文件夹下,之后访问这个~/Share/文件夹就相当于访问这个硬盘2的sdb1分区了。对/Share/的任何操作,都相当于对sdb1里文件的操作。 - 所以Linux下,mount挂载的作用,就是将一个设备(通常是存储设备)挂接到一个已存在的目录上。访问这个目录就是访问该存储设备。
- linux操作系统将所有的设备都看作文件,它将整个计算机的资源都整合成一个大的文件目录。我们要访问存储设备中的文件,必须将文件所在的分区挂载到一个已存在的目录上,然后通过访问这个目录来访问存储设备。挂载就是把设备放在一个目录下,让系统知道怎么管理这个设备里的文件,了解这个存储设备的可读写特性之类的过程。
- 我们不是有/dev/sdb1 吗,直接对它操作不就行了?这不是它的目录吗?
- 这不是它的目录。虽然/dev是个目录,但/dev/sdb1不是目录。可以发现ls/dev/sdb1无法执行。/dev/sdb1,是一个类似指针的东西,指向这个分区的原始数据块。mount前,系统并不知道这个数据块哪部分数据代表文件,如何对它们操作。
- 挂载一个设备前,必须先建立一个挂在点
Linux 的磁盘挂载使用 mount 命令,卸载使用 umount 命令。
磁盘挂载语法:mount [-t 文件系统] [-L Label名] [-o 额外选项] [-n] 装置文件名 挂载点
磁盘卸载命令 umount 语法:umount [-fn] 装置文件名或挂载点
1 | |
实例
用默认的方式,将刚刚创建的 /dev/hdc6 挂载到 /mnt/hdc6 上面!
1 | |
卸载/dev/hdc6
1 | |
压缩与解压缩
压缩格式:windows (zip、rar)
linux (gz ,bzip,zip)
打包与压缩
打包: 将多个文件打包成一个文件,没有层级目录之分。文件大小不变。类似多个购物袋放进一个袋子,方便好拿。
压缩: 把打包后的那个文件压缩,文件大小减小。先将多个购物袋放进一个袋子,再抽真空压缩,减小尺寸。
先打包再压缩, 打包后可以拆包,压缩后可以解压 。一般压缩软件自带打包与压缩,所以看似是只有压缩一步。
压缩软件
该压缩软件是要安装在 windows系统下,方便和 linux 文件传输,同意格式。LInux 不安装 。
我经常使用的 360 压缩不支持 gzip、bzip2 压缩格式,所以不选择。另一个免费的 7-Zip 支持这两种格式。
tar命令
该命令用于对文件进行打包,ta文件通常都是以 .tar 结尾。默认情况并不会压缩,如果指定了相应的参数,它还会调用相应的压缩程序(如gzip和bzip等)进行压缩和解压。它的常用参数如下:
1 | |
上面的解说可以已经让你晕过去了,但是通常我们只需要记住下面三条命令即可:
1 | |
rar压缩格式
要在 linux 下处理 .rar 文件,需要安装 RAR for Linux。 安装方式:sudo apt-get install rar
1 | |
ZIP压缩格式
linux 下自带了 zip 和 unzip 程序,zip 是压缩程序,unzip 是解压程序。它们的参数选项很多,这里只做简单介绍,依旧举例说明一下其用法:
1 | |
实例
1 | |
用户和用户组
Linux系统是一个多用户多任务的分时操作系统,任何一个要使用系统资源的用户,都必须首先向系统管理员申请一个账号,然后以这个账号的身份进入系统。用户的账号一方面可以帮助系统管理员对使用系统的用户进行跟踪,并控制他们对系统资源的访问;另一方面也可以帮助用户组织文件,并为用户提供安全性保护。
每个用户账号都拥有一个唯一的用户名(UID)和各自的口令。
实现用户账号的管理,要完成的工作主要有如下几个方面:
- 用户账号的添加、删除与修改。
- 用户口令的管理。
- 用户组的管理。
注意三个文件:
- /etc/passwd 存储用户的关键信息
- /etc/group 存储用户组的关键信息
- /etc/shadow 存储用户的密码信息
Linux用户
Linux是一个多用户操作系统,不同的用户拥有不同的权限。可以查看和操作不同的文件。 Ubuntu有三种用户:
- 初次创建的用户
- root用户
- 普通用户
root 用户和初次创建的用户其实就是一个用户,是第一次安装这个 Linux 系统的那个用户。初次创建的用户权限其实就是 root 用户约束了一部分权力(防止误操作删除了系统文件,导致系统崩溃),但仍可以使用 sudo 命令获取临时的root权限或永久切换为 root 权限。普通用户无法创建用户,也无法获得 root 权限。
Linux用户组
为了方便管理,将用户进行分组。这样就可以设置非本组人员不能访问某些文件。每个用户可以属于多个不同的组。
用户:家里有你、弟弟、妹妹个人,每个人都有自己的房间,你们三个人都是用户,你们都不能随便的乱翻别人的房间。
用户组:你们三个都是一个家庭的,也就是属于同一个用户组,你们三个可以共用厨房,书房等空间。
因此:
用户和用户组的存在就是为了控制文件的访问权限的。
每个用户组都有一个ID,叫做GID。
创建用户和用户组
图形化界面创建
要使用图形化界面创建用户和用户组的话就需要安装gnome-system-tools这个工具:sudo apt-get install gnome-system-tools
命令创建用户和用户组
1 | |
实例:
1 | |
参考链接
- Linux 用户和用户组管理enter description here
- 管理文件权限和所有权
文件基本属性
inux 系统是一种典型的多用户系统,不同的用户处于不同的地位,拥有不同的权限。
为了保护系统的安全性,Linux 系统对不同的用户访问同一文件(包括目录文件)的权限做了不同的规定。
在 Linux 中我们通常使用以下两个命令来修改文件或目录的所属用户与权限:
- chown (change ownerp) : 修改所属用户与组。
- chmod (change mode) : 修改用户的权限。
在 Linux 中我们可以使用 ll 或者 ls –l 命令来显示一个文件的属性以及文件所属的用户和组,如:
1 | |
实例中,bin 文件的第一个属性用 d 表示。d 在 Linux 中代表该文件是一个目录文件。
在 Linux 中第一个字符代表这个文件是目录、文件或链接文件等等。
1 | |
接下来的字符中,以三个为一组,且均为 r、w、x 三个参数的组合。其中, r 代表可读(read)、 w 代表可写(write)、 x 代表可执行(execute)。 要注意的是,这三个权限的位置不会改变,如果没有权限,就会出现减号 - 而已。
每个文件的属性由左边第一部分的 10 个字符来确定(如下图)。
从左至右用 0-9 这些数字来表示。
- 第 0 位确定文件类型,第 1-3 位确定属主(该文件的所有者)拥有该文件的权限。
- 第4-6位确定属组(所有者的同组用户)拥有该文件的权限,第7-9位确定其他用户拥有该文件的权限。
- 其中,第 1、4、7 位表示读权限,如果用 r 字符表示,则有读权限,如果用 - 字符表示,则没有读权限;
- 第 2、5、8 位表示写权限,如果用 w 字符表示,则有写权限,如果用 - 字符表示没有写权限;
- 第 3、6、9 位表示可执行权限,如果用 x 字符表示,则有执行权限,如果用 - 字符表示,则没有执行权限。
Linux文件属主和属组
1 | |
对于文件来说,它都有一个特定的所有者,也就是对该文件具有所有权的用户。
同时,在Linux系统中,用户是按组分类的,一个用户属于一个或多个组。文件所有者以外的用户又可以分为文件所有者的同组用户和其他用户。
在以上实例中,mysql 文件是一个目录文件,属主和属组都为 mysql,属主有可读、可写、可执行的权限;与属主同组的其他用户有可读和可执行的权限;其他用户也有可读和可执行的权限。
对于 root 用户来说,一般情况下,文件的权限对其不起作用。
更改文件属性
1、chgrp:更改文件属组
语法:chgrp [-R] 属组名 文件名
1 | |
2、chown:更改文件属主,也可以同时更改文件属组
语法:
1 | |
3、chmod:更改文件9个属性
数字格式
文件的权限字符为: -rwxrwxrwx , 这九个权限是三个三个一组的!其中,我们可以使用数字来代表各个权限,各权限的分数对照表如下:
owner = rwx = 4+2+1 = 7
group = rwx = 4+2+1 = 7
others= — = 0+0+0 = 0
所以等一下我们设定权限的变更时,该文件的权限数字就是 770。变更权限的指令 chmod 的语法是这样的:
chmod [-R] xyz 文件或目录
选项与参数:
1 | |
符号格式
user:用户
group:组
others:其他
那么我们就可以使用 u, g, o 来代表三种身份的权限。
1 | |
1 | |
连接文件
文件都有文件名与数据,这在 Linux 上被分成两个部分:用户数据 (user data) 与元数据 (metadata)。用户数据,即文件数据块 (data block),是记录文件真实内容的地方;而元数据则是文件的附加属性,如文件大小、创建时间、所有者等信息。在 Linux 中,元数据中的 inode 号(索引节点号,inode 是元数据的一部分但并不包含文件名)才是文件的唯一标识而非文件名。文件名仅是为了方便人们的记忆和使用,系统或程序实际是通过 inode 号寻找正确的文件数据块。下图展示了程序通过文件名获取文件内容的过程。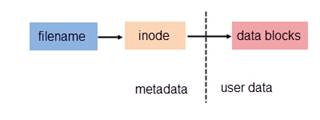
在 Linux 系统中查看 inode 号可使用命令 stat 或 ls -i。
1 | |
为解决文件的共享使用,Linux 系统引入了两种链接:硬链接 (hard link) 与软链接(又称符号链接,即 soft link 或 symbolic link)。链接为 Linux 系统解决了文件的共享使用,还带来了隐藏文件路径、增加权限安全及节省存储等好处。
硬链接:
若一个 inode 号对应多个文件名,则称这些文件为硬链接。换言之,硬链接就是同一个文件使用了多个别名。由于硬链接是有着相同 inode 号仅文件名不同的文件,因此硬链接存在以下几点特性:
- 文件有相同的 inode 及 data block;
- 只能对已存在的文件进行创建;
- 不能跨文件系统,因为不同的文件系统有不同的inode table;
- 不能对目录进行创建,只可对文件创建;
- 删除一个硬链接文件并不影响其他有相同 inode 号的文件。
- 所有硬链接文件修改时同步的。
inode 是随着文件的存在而存在,因此只有当文件存在时才可创建硬链接,inode 号仅在各文件系统下是唯一的,当 Linux 挂载多个文件系统后将出现 inode 号重复的现象,因此硬链接创建时不可跨文件系统。
软链接
软链接(也叫符号链接),类似于windows系统中的快捷方式。软链接就是一个普通文件,只是数据块内容有点特殊,存放的内容是另一文件的路径名的指向,通过这个方式可以快速定位到软连接所指向的源文件实体。软链接有着自己的 inode 号以及用户数据块。因此软链接的创建与使用没有类似硬链接的诸多限制:
- 软链接有自己的文件属性及权限等;
- 可对不存在的文件或目录创建软链接;
- 软链接可交叉文件系统;
- 软链接可对文件或目录创建;
- 删除软链接并不影响被指向的文件,但若被指向的原文件被删除,则相关软连接被称为死链接(即 dangling link,若被指向路径文件被重新创建,死链接可恢复为正常的软链接)。
软链接创建时原文件的路径指向使用绝对路径较好。使用相对路径创建的软链接被移动后该软链接文件将成为一个死链接,因为链接数据块中记录的亦是相对路径指向。
二者区别
硬链接实际上是为文件建一个别名,链接文件和原文件实际上是同一个文件。而软链接建立的是一个指向,即链接文件内的内容是指向原文件的指针,它们是两个文件。
不论是硬链接或软链接都不会将原本的档案复制一份,只会占用非常少量的磁碟空间。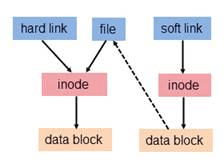
ln命令
软链接和硬链接都是通过ln命令来创建,只是参数不同。命令格式如下:ln 参数 源文件或目录 目标文件或目录
注意:源目录和目标目录都必须是绝对路径!
1 | |
创建软链接 (符号链接)使用:ln -s source target
创建硬链接 (实体链接)使用:ln source target
参考链接
四、linux 编程
LInux下编程分为两步:
- 编写
- 编译
而这两步是使用不同的软件实现的。
更新本地数据库:sudo apt-get update
vim编译器
Linux系统都会自带vi编辑器,但是vi编辑器太难用了!所以建议大家安装vim编辑器,安装命令:sudo apt-get install vim
vi/vim 的使用
vi xxx 使用vi编辑器打开文件,没有则自动创建。
基本上 vi/vim 共分为三种模式,分别是命令模式(Command mode),输入模式(Insert mode)和底线命令模式(Last line mode)。 这三种模式的作用分别是:
命令模式
用户刚刚启动 vi/vim,便进入了命令模式。
此状态下敲击键盘动作会被Vim识别为命令,而非输入字符。比如我们此时按下i,并不会输入一个字符,i被当作了一个命令。
以下是常用的几个命令:
- “i、I、a、A、o、O、s、r”等任一个切换到输入模式,以输入字符。
- x 删除当前光标所在处的字符。
- : 切换到底线命令模式,以在最底一行输入命令。
- dd,删除光标所在行,ndd,删除光标所在行及其下n行。
- u,撤销,恢复上一步。
- . ,重复前一个操作。
- yy,复制光标所在行
- nyy,复制光标所在向下n行,比如10yy就是复制光标下10行。
- p和P,p为复制到光标下一行,P复制到光标上一行。
命令模式只有一些最基本的命令,因此仍要依靠底线命令模式输入更多命令
输入模式
在命令模式下按下i就进入了输入模式。
在输入模式中,可以使用以下按键:
- 字符按键以及Shift组合,输入字符
- ENTER,回车键,换行
- BACK SPACE,退格键,删除光标前一个字符
- DEL,删除键,删除光标后一个字符
- 方向键,在文本中移动光标
- HOME/END,移动光标到行首/行尾
- Page Up/Page Down,上/下翻页
- Insert,切换光标为输入/替换模式,光标将变成竖线/下划线
- ESC,退出输入模式,切换到命令模式
底线命令模式
在命令模式下按下:(英文冒号)就进入了底线命令模式。
底线命令模式可以输入单个或多个字符的命令,可用的命令非常多。
在底线命令模式中,基本的命令有(已经省略了冒号):
1 | |
按ESC键可随时退出底线命令模式。
简单的说,我们可以将这三个模式想成底下的图标来表示: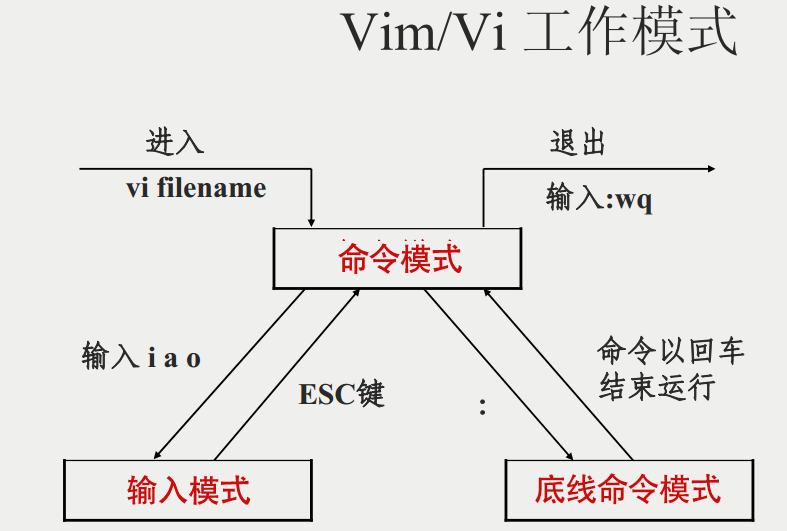
编写第一个程序
使用前,还需要简单配置一下
vim /etc/vim/vimrc打开文件(如果保存时提示错误,加 sudo)set ts = 4按下i进入编辑模式,找到文件最后面,输入该代码,设置TAB键为空4格set nu再 输入,打开行号显示。esc退出编辑模式,:wq保存
1 | |
vi main.c 创建一个源文件。输入如下代码:
1 | |
参考链接
GCC
gcc命令使用GNU推出的基于C/C++的编译器,是开放源代码领域应用最广泛的编译器,具有功能强大,编译代码支持性能优化等特点。
现在很多程序员都应用gcc,目前gcc可以用来编译C/C++、FORTRAN、JAVA、OBJC、ADA等语言的程序,可根据需要选择安装支持的语言。
1 | |
实例:
无选项编译文件,默认编译并生成 a.out 可执行文件
1 | |
自定义输出文件文件名
1 | |
运行可执行文件
1 | |
程序编译流程
- 预处理:生成 .i 的文件[预处理器cpp]
展开所有的头文件、替换程序中的宏、解析条件编译并添加到文件中 - 编译:生成文件 .s [编译器egcs]
将经过预编译处理的代码编译成汇编代码,也就是我们常说的程序编译 - 汇编:生成 .o 的文件[汇编器as]
将汇编语言文件编译成二进制目标文件(机器代码) - 链接:生成可执行程序 [链接器ld]
将汇编出来的多个二进制目标文件链接在一起,形成最终的可执行文件,链接的时候还会涉及到静态库和动态库等问题。
上面演示的例程都只有一个文件,因此可以直接使用gcc命令生成可执行文件 main.out,并没有先将c文件编译成.o文件,然后再链接在一起。
参考链接
Makefile编写
make工具
利用make工具可以自动完成编译工作。这些工作包括:
- 如果仅仅修改了某几个源文件,则只重新编译这几个源文件;
- 如果某个头文件被修改,则重新编译所有包含该头文件的源文件。
利用这种自动编译可大大简化开发工作,避免不必要的重新编译。
Makefile
make工具通过一个称为Makefile的文件来完成并自动维护编译工作。Makefile文件描述了整个工程的编译、链接等规则。
Makefile一般规则
1 | |
- 目标(TARGET):程序产生的文件,如可执行文件和目标文件;目标也可以是要执行的动作,如clean,也称伪目标。
- 依赖(DEPENDENCIES)是用来产生目标的输入文件列表,一个目标通常依赖于多个文件。有的目标可以没有依赖文件。
- 命令(COMMAND):是make执行的动作(命令是shell命令或者是可在shell下执行的程序)。注意:每个命令行的起始字符必须为TAB字符,命令可以不止一条。
- 如果依赖文件中有一个或多个文件更新的话,命令就要执行,这就是Makefile最核心的内容。
以上由目标,命令组成的就叫做一条规则语句,Makefile 会包含很多规则语句,但每条规则都遵循上面的规则
接下来就根据这个Makefile基本规则来编写一个最基本的Makefile文件
1 | |
我们可以看到,我们使用了 6 条规则,main是我们最终想要生成的目标文件,它依赖main.o sub.o add.o print.o这四个 .o文件。因此要执行 gcc -o main main.o add.o sub.o print.o命令来生成目标文件 main,但是当前没有这些 .o文件( 一开始只有编写为 .c和.h文件),因此就要先生成这些 .o文件。我们写了四条xxx.o:xxx.c然后执行gcc -Wall -g -c xxx.c -o xxx.o,这些语句就会生成目标文件的依赖项。
clean 是一个伪目标文件,因为它没有依赖项。我们只是想通过 make clean 来将 .o 文件删除,但是我们通常要指定 .PHONY:clean 这条语句,用来显式的指定 clean 是伪目标,来防止当前目录下有一个同名的 clean 文件。这样,一个简单呢的Makefile文件就写好了。
实例
我们完成这样一个小工程,通过键盘输入两个整形数字,然后计算他们的和并将结果显示在屏幕上,在这个工程中我们有main.c、input.c和calcu.c这三个C文件和input.h、calcu.h这两个头文件。其中main.c是主体,input.c负责接收从键盘输入的数值,calcu.h进行任意两个数相加。
其中main.c文件内容如下:
1 | |
input.c文件内容如下:
1 | |
calcu.c文件内容如下:
1 | |
文件input.h内容如下:
1 | |
文件calcu.h内容如下:
1 | |
1
gcc方法
1 | |
gcc方法特点:
- 有多少个文件每次就得写多少个文件名,几千个文件的话就不太现实了
- 每次编译都是所有文件都编译,不论有没有修改过,太花时间
因此我们需要:
- 如果工程没有编译过,那么工程中的所有.c文件都要被编译并且链接成可执行程序。
- 如果工程中只有个别C文件被修改了,那么只编译这些被修改的C文件即可。
- 如果工程的头文件被修改了,那么我们需要编译所有引用这个头文件的C文件,并且链接成可执行文件。
能够完成这个功能的就是Makefile了。
make方法
在工程目录下创建名为“Makefile”的文件,文件名一定要叫做“Makefile”!!! Makefile和C文件是处于同一个目录的。
1 | |
在Makefile文件中输入如下代码:
1 | |
Makefile编写好以后我们就可以使用make命令来编译我们的工程了,直接在命令行中输入“make”即可,make命令会在当前目录下查找是否存在“Makefile”这个文件,如果存在的话就会按照Makefile里面定义的编译方式进行编译,如下所示:
1 | |
Makefile变量
Makefile中变量的引用方法是:$(变量名)
跟C语言一样Makefile也支持变量的,先观察一下前面的例子:
1 | |
这里main.o input.o calcu.o 书写了两边,重复书写,为了解决这个问题,Makefile加入了变量支持。不像C语言中的变量有int、char等各种类型,Makefile中的变量都是字符串,且无需声明!类似C语言中的宏。使用变量将上面的代码修改,修改以后如下所示:
1 | |
我们定义了一个变量叫OBJ,他是我们的依赖项列表。然后使用变量来代替对应的文件,这样就可以避免重复书写 main.o sub.o add.o print.o。后面使用$(objects) 调用变量objects。
我们再观察:
1 | |
似乎有一些规律,都是
1 | |
那么能不能够用一两句来替代上述语句呢,答案是有的。此时我们需要引入 Makefile 模式规则和自动化变量。
Makefile模式规则
模式规则中,至少在规则的目标定义中要包含 “%”,否则,就是一般的规则(上述内容就是一般规则)。 格式如下:
%.o : %.c ;
目标中的 “%” 定义表示对文件名的匹配,”%” 表示长度任意的非空字符串。例如:”%.c” 表示以 “.c” 结尾的文件名(文件名的长度至少为3),而 “s.%.c” 则表示以 “s.” 开头,”.c” 结尾的文件名(文件名的长度至少为5)。
如果 “%” 定义在目标中,那么,目标中的 “%” 的值决定了依赖目标中的 “%” 的值,也就是说,目标中的模式的” %” 决定了依赖目标中 “%” 的样子。
例如 %.o表示要生成的目标是main.o,那么依赖中 %c 就会自动表示为 main.c。如果有多个目标文件,%.o : %.c 就会轮询这些文件。
如此我们便可以简写之前的 一般规则,实例如下:
1 | |
Makefile自动化变量
在上述的模式规则中,目标和依赖文件都是一系例的文件,但在每一次的对模式规则的解析时,都会是不同的目标和依赖文件。命令 gcc -c xxx.c 中的 xxx.c 也就会不一样, 那么我们如何代替 xxx.c呢,答案是自动化变量。
所谓自动化变量,就是这种变量会把模式中所定义的一系列的文件自动地挨个取出,直至所有的符合模式的文件都取完了。这种自动化变量只应出现在规则的命令中。
下面是一部分自动化变量及其说明:
1 | |
如此我们便可以简写之前的 一般规则,实例如下:
1 | |
这里我们用 $^ 代替了 xxx.c,这样其实每一条命令书写方式就是一样的了。再结合上述的模式规则,我们的Makefile 代码最终像是如下:
1 | |
可以看出相比原来的代码要精简了很多,1、3 行使用了变量,4、6 行使用了自动化变量,5 行使用了模式规则
Makefile 条件判断
在C语言中我们通过条件判断语句来根据不同的情况来执行不同的分支,Makefile也支持条件判断,语法有两种如下:
1 | |
以及:
1 | |
其中条件关键字有4个:ifeq、ifneq、ifdef和ifndef,这四个关键字其实分为两对、ifeq与ifneq、ifdef与ifndef
| 关键字 | 功能 |
|---|---|
| ifeq | 判断参数是否不相等,相等为 true,不相等为 false。 |
| ifneq | 判断参数是否不相等,不相等为 true,相等为 false。 |
| ifdef | 判断是否有值,有值为 true,没有值为 false。 |
| ifndef | 判断是否有值,没有值为 true,有值为 false。 |
ifeq 和 ifneq
条件判断的使用方式如下:
1 | |
上述用法中都是用来比较“参数1”和“参数2”是否相同,如果相同则为真,“参数1”和“参数2”可以为函数返回值。
实例:
1 | |
条件语句中使用到三个关键字“ifeq”、“else”、“endif”。其中:“ifeq”表示条件语句的开始,并指定一个比较条件(相等)。括号和关键字之间要使用空格分隔,两个参数之间要使用逗号分隔。参数中的变量引用在进行变量值比较的时候被展开。“ifeq”,后面的是条件满足的时候执行的,条件不满足忽略;“else”表示当条件不满足的时候执行的部分,可以没有;“endif”是判断语句结束标志,Makefile 中条件判断的结束都要有。
ifneq的用法类似,只不过ifneq是用来了比较“参数1”和“参数2”是否不相等,如果不相等的话就为真。
ifdef和ifndef
的用法如下:
1 | |
如果“变量名”的值非空,那么表示表达式为真,否则表达式为假。“变量名”同样可以是一个函数的返回值。
实例 1:
1 | |
实例 2:
1 | |
通过打印 “yes” 或 “no” 来演示执行的结果。我们执行 make 可以看到实例 1打印的结果是 “yes” ,实例 2打印的结果是 “no” 。其原因就是在实例 1 中,变量“foo”的定义是“foo = $(bar)”。虽然变量“bar”的值为空,但是“ifdef”的判断结果为真,这种方式判断显然是不行的,因此当我们需要判断一个变量的值是否为空的时候需要使用“ifeq” 而不是“ifdef”。
ifndef用法类似,但是含义用户ifdef相反
注意:在条件表达式中不能使用自动化变量,自动化变量在规则命令执行时才有效
Makefile 函数使用
Makefile支持函数,类似C语言一样,Makefile中的函数是已经定义好的,我们直接使用,不支持我们自定义函数。make所支持的函数不多,但是绝对够我们使用了,函数的用法如下:
1 | |
或者
1 | |
可以看出,调用函数和调用普通变量一样,使用符号“$”来标识。参数集合是函数的多个参数,参数之间以逗号“,”隔开,函数名和参数之间以“空格”分隔开,函数的调用以“$”开头。接下来我们介绍几个常用的函数。
1、subst
函数subst用来完成字符串替换,调用形式如下:
1 | |
此函数的功能是将字符串 <text> 中的<from>内容替换为<to>`,函数返回被替换以后的字符串,比如如下示例:
1 | |
把字符串 “myname is zzk” 中的 “zzk” 替换为“ZZK”,替换完成以后的字符串为“my name is ZZK”。
2、patsubst
函数patsubst用来完成模式字符串替换,使用方法如下:
1 | |
此函数查找字符串 \<text>中的单词是否符合模式\<pattern>,如果匹配就用 \<replacement> 来替换掉,\<pattern>可以使用包括通配符“%”,表示任意长度的字符串,函数返回值就是替换后的字符串。如果 \<replacement> 中也包涵“%”,那么 \<replacement> 中的“%”将是\<pattern> 中的那个“%”所代表的字符串,比如:
1 | |
将字符串“a.c b.c c.c”中的所有符合“%.c”的字符串,替换为“%.o”,替换完成以后的字符串为“a.o b.o c.o”。
3、dir
函数dir用来获取目录,使用方法如下:
1 | |
此函数用来从文件名序列 <names> 中提取出目录名,返回值是文件名序列 <names>的目录部分,比如:
1 | |
提取文件“/src/a.c”的目录部分,也就是“/src”。
4、notdir
去除文件中的目录部分,也就是提取文件名,用法如下:
1 | |
此函数用与从文件名序列<names>中提取出文件名非目录部分,比如:
1 | |
提取文件“/src/a.c”中的非目录部分,也就是文件名“a.c”。
5、foreach
foreach函数用来完成循环,用法如下:
1 | |
此函数的意思就是把参数 <list> 中的单词逐一取出来放到参数 <var> 中,然后再执行 <text>所包含的表达式。每次 <text> 都会返回一个字符串,循环的过程中,<text>中所包含的每个字符串会以空格隔开,最后当整个循环结束时,<text>所返回的每个字符串所组成的整个字符串将会是函数foreach函数的返回值。比如:
1 | |
执行 make 命令,我们得到的值是“a.o b.o c.o d.o”。
6、wildcard
通配符“%”只能用在规则中,只有在规则中它才会展开,如果在变量定义和函数使用时,通配符不会自动展开,这个时候就要用到函数wildcard,使用方法如下:
1 | |
函数的功能是列出当前目录下所有符合模式 PATTERN 格式的文件名。返回值为空格分隔并且存在当前目录下的所有符合模式 PATTERN 的文件名。比如:
1 | |
上面的代码是用来获取当前目录下所有的 .c文件,类似“%”。这个函数通常跟的通配符 “*“ 连用,使用在依赖规则的描述的时候被展开
参考链接:
跟我一起写Makefile
Make 命令教程
GNU make
What is a Makefile and how does it work?
Makefile的工作流程
Makefile编写入门教程
shell 脚本
Shell 是一个用 C 语言编写的程序,它是用户使用 Linux 的桥梁。Shell 既是一种命令语言,又是一种程序设计语言。
Shell 脚本(shell script),是一种为 shell 编写的脚本程序。类似windows的批处理文件,shell脚本就是将连续执行的命令写成一个文件。
shell脚本提供数组、循环、条件判断的等功能。shell脚本一般是Linux运维或者系统管理员要掌握的,作为嵌入式开发人员,只需要掌握shell脚本最基础的部分即可。
Shell 编程跟 JavaScript、php 编程一样,只要有一个能编写代码的文本编辑器和一个能解释执行的脚本解释器就可以了。
Linux 的 Shell 种类众多,常见的有:
- Bourne Shell(/usr/bin/sh或/bin/sh)
- Bourne Again Shell(/bin/bash)
- C Shell(/usr/bin/csh)
- K Shell(/usr/bin/ksh)
- Shell for Root(/sbin/sh)
本教程关注的是 Bash,也就是 Bourne Again Shell,由于易用和免费,Bash 在日常工作中被广泛使用。同时,Bash 也是大多数Linux 系统默认的 Shell。
在一般情况下,人们并不区分 Bourne Shell 和 Bourne Again Shell,所以,像 #!/bin/sh,它同样也可以改为 #!/bin/bash。
#! 告诉系统其后路径所指定的程序即是解释此脚本文件的 Shell 程序。
所以脚本其实就是短小的、用来让计算机自动化完成一系列工作的程序,这类程序可以用文本编辑器修改,不需要编译,通常是解释运行的。
第一个shell脚本
shell脚本是个纯文本文件,命令从上而下,一行一行的开始执行。
使用 vim 新建一个文件 test.sh,扩展名并不影响脚本执行,见名知意就好。文本内容如下:
1 | |
#! 是一个约定的标记,它告诉系统这个脚本需要什么解释器来执行,即使用哪一种 Shell。echo 命令用于向窗口输出文本。
写完保存,我们还不能直接运行。
运行 Shell 脚本有两种方法:
作为可执行程序
将上面的代码保存为 test.sh,在该文件目录下输出命令:1
2chmod +x ./test.sh #使脚本具有执行权限
./test.sh #执行脚本作为解释器参数
这种运行方式是,直接运行解释器,其参数就是 shell 脚本的文件名,如:1
2/bin/sh test.sh
/bin/php test.php这种方式运行的脚本,不需要在程序第一行指定解释器信息(
#!/bin/bash),写了也没用。
Shell 注释
以 # 开头的行就是注释,会被解释器忽略。
1 | |
多行注释
多行注释可以使用以下格式:
1 | |
EOF 也可以使用其他符号:
1 | |
Shell 变量
定义变量时,变量名不加美元符号($,PHP语言中变量需要),如:
1 | |
注意,变量名和等号之间不能有空格,这可能和你熟悉的所有编程语言都不一样。同时,变量名的命名须遵循如下规则:
- 命名只能使用英文字母,数字和下划线,首个字符不能以数字开头。
- 中间不能有空格,可以使用下划线(_)。
- 不能使用标点符号。
- 不能使用bash里的关键字(可用help命令查看保留关键字)。
使用变量
使用一个定义过的变量,只要在变量名前面加美元符号即可,和 Makefile 类似:
1 | |
变量名外面的花括号是可选的,加不加都行,推荐给所有变量加上花括号。
只读变量
使用 readonly 命令可以将变量定义为只读变量,只读变量的值不能被改变。
下面的例子尝试更改只读变量,结果报错:
1 | |
运行脚本,结果如下:
1 | |
删除变量
使用 unset 命令可以删除变量。语法:
1 | |
变量被删除后不能再次使用。unset 命令不能删除只读变量。
实例
1 | |
以上实例执行将没有任何输出。
变量类型
运行shell时,会同时存在三种变量:
- 局部变量 局部变量在脚本或命令中定义,仅在当前shell实例中有效,其他shell启动的程序不能访问局部变量。
- 环境变量 所有的程序,包括shell启动的程序,都能访问环境变量,有些程序需要环境变量来保证其正常运行。必要的时候shell脚本也可以定义环境变量。
- shell变量 shell变量是由shell程序设置的特殊变量。shell变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了shell的正常运行
Shell 字符串
字符串是shell编程中最常用最有用的数据类型(除了数字和字符串,也没啥其它类型好用了),字符串可以用单引号,也可以用双引号,也可以不用引号。
单引号
1 | |
单引号字符串的限制:
- 单引号里的任何字符都会原样输出,单引号字符串中的变量是无效的;
- 单引号字串中不能出现单独一个的单引号(对单引号使用转义符后也不行),但可成对出现,作为字符串拼接使用。
双引号
1 | |
输出结果为:
1 | |
双引号的优点:
- 双引号里可以有变量
- 双引号里可以出现转义字符
拼接字符串
1 | |
输出结果为:
1 | |
获取字符串长度
1 | |
提取子字符串
以下实例从字符串第 2 个字符开始截取 4 个字符:
1 | |
注意:第一个字符的索引值为 0。
查找子字符串
查找字符 i 或 o 的位置(哪个字母先出现就计算哪个):
1 | |
注意: 以上脚本中 ` 是反引号(键盘数字 1 左边按键),而不是单引号 ',不要看错了哦。
Shell 数组
bash支持一维数组(不支持多维数组),并且没有限定数组的大小。
类似于 C 语言,数组元素的下标由 0 开始编号。获取数组中的元素要利用下标,下标可以是整数或算术表达式,其值应大于或等于 0。
定义数组
在 Shell 中,用括号来表示数组,数组元素用 “空格” 符号分割开。定义数组的一般形式为:
1 | |
例如:
1 | |
或者
1 | |
还可以单独定义数组的各个分量:
1 | |
可以不使用连续的下标,而且下标的范围没有限制。
读取数组
读取数组元素值的一般格式是:
1 | |
例如:
1 | |
使用 @ 符号可以获取数组中的所有元素,例如:
1 | |
会依次打印出数组中的所有元素。
获取数组的长度
获取数组长度的方法与获取字符串长度的方法相同,例如:
1 | |
Shell 传递参数
我们可以在执行 Shell 脚本时,向脚本传递参数,脚本内获取参数的格式为:$n。n 代表一个数字,1 为执行脚本的第一个参数,2 为执行脚本的第二个参数,以此类推……。
0 为执行的文件名(包含文件路径):
实例
以下实例我们向脚本传递三个参数,并分别输出,其中 $0 为执行的文件名(包含文件路径):
1 | |
为脚本设置可执行权限,并执行脚本,输出结果如下所示:
1 | |
另外,还有几个特殊字符用来处理参数:
| 参数处理 | 说明 |
|---|---|
| $# | 传递到脚本的参数个数 |
| $* | 以一个单字符串显示所有向脚本传递的参数。如”$*“用「”」括起来的情况、以”$1 $2 … $n”的形式输出所有参数。 |
| $$ | 脚本运行的当前进程ID号 |
| $! | 后台运行的最后一个进程的ID号 |
| $@ | 与$*相同,但是使用时加引号,并在引号中返回每个参数。 如”$@”用「”」括起来的情况、以”$1” “$2” … “$n” 的形式输出所有参数。 |
| $- | 显示Shell使用的当前选项,与set命令功能相同。 |
| $? | 显示最后命令的退出状态。0表示没有错误,其他任何值表明有错误。 |
1 | |
执行脚本,输出结果如下所示:
1 | |
$ 与 $@ 区别:*
- 相同点:都是引用所有参数。
- 不同点:只有在双引号中体现出来。假设在脚本运行时写了三个参数 1、2、3,,则 “ * “ 等价于 “1 2 3”(传递了一个参数),而 “@” 等价于 “1” “2” “3”(传递了三个参数)。
1 | |
执行脚本,输出结果如下所示:
1 | |
echo 执行默认回车,演示1 这里实际只执行了一次,演示2 执行了两次。 这里涉及 for 语句,后续将会讲解。
运算符
Shell 和其他编程语言一样,支持多种运算符,包括:
- 算数运算符
- 关系运算符
- 布尔运算符
- 字符串运算符
- 文件测试运算符
原生bash不支持简单的数学运算,但是可以通过其他命令来实现,例如 awk 和 expr,expr 最常用。
expr 是一款表达式计算工具,使用它能完成表达式的求值操作。
例如,两个数相加(注意使用的是反引号 ` 而不是单引号 ‘):
实例
1 | |
执行脚本,输出结果如下所示:
1 | |
两点注意:
- 表达式和运算符之间要有空格,例如
2+2是不对的,必须写成2 + 2,这与我们熟悉的大多数编程语言不一样。 - 完整的表达式要被
算术运算符
下表列出了常用的算术运算符,假定变量 a 为 10,变量 b 为 20:
| 运算符 | 说明 | 举例 |
|---|---|---|
| + | 加法 | expr $a + $b 结果为 30 |
| - | 减法 | expr $a - $b 结果为 -10。 |
| * | 乘法 | expr $a \* $b 结果为 200。 |
| / | 除法 | expr $b / $a 结果为 2。 |
| % | 取余 | expr $b % $a 结果为 0。 |
| = | 赋值 | a=$b 将把变量 b 的值赋给 a。 |
| == | 相等 | 用于比较两个数字,相同则返回 true。[ $a == $b ] 返回 false |
| != | 不相等 | 用于比较两个数字,不相同则返回 true。 [ $a != $b ] 返回 true。 |
注意: 条件表达式要放在方括号之间,并且要有空格,例如: [$a==$b] 是错误的,必须写成 [ $a == $b ]。
实例
算术运算符实例如下:
1 | |
执行脚本,输出结果如下所示:
1 | |
注意:
- 乘号(*)前边必须加反斜杠()才能实现乘法运算;
- if…then…fi 是条件语句,后续将会讲解。
- 在 MAC 中 shell 的 expr 语法是:$((表达式)),此处表达式中的 “*“ 不需要转义符号 “" 。
关系运算符
关系运算符只支持数字,不支持字符串,除非字符串的值是数字。
下表列出了常用的关系运算符,假定变量 a 为 10,变量 b 为 20:
| 运算符 | 说明 | 举例 |
|---|---|---|
| -eq | 检测两个数是否相等,相等返回 true。 | [ $a -eq $b ] 返回 false。 |
| -ne | 检测两个数是否不相等,不相等返回 true。 | [ $a -ne $b ] 返回 true。 |
| -gt | 检测左边的数是否大于右边的,如果是,则返回 true。 | [ $a -gt $b ] 返回 false。 |
| -lt | 检测左边的数是否小于右边的,如果是,则返回 true。 | [ $a -lt $b ] 返回 true。 |
| -ge | 检测左边的数是否大于等于右边的,如果是,则返回 true。 | [ $a -ge $b ] 返回 false。 |
| -le | 检测左边的数是否小于等于右边的,如果是,则返回 true。 | [ $a -le $b ] 返回 true。 |
实例
1 | |
执行脚本,输出结果如下所示:
1 | |
布尔运算符
下表列出了常用的布尔运算符,假定变量 a 为 10,变量 b 为 20:
| 运算符 | 说明 | 举例 |
|---|---|---|
| ! | 非运算,表达式为 true 则返回 false,否则返回 true。 | [ ! false ] 返回 true。 |
| -o | 或运算,有一个表达式为 true 则返回 true。 | [ $a -lt 20 -o $b -gt 100 ] 返回 true。 |
| -a | 与运算,两个表达式都为 true 才返回 true。 | [ $a -lt 20 -a $b -gt 100 ] 返回 false。 |
实例
1 | |
执行脚本,输出结果如下所示:
1 | |
逻辑运算符
以下介绍 Shell 的逻辑运算符,假定变量 a 为 10,变量 b 为 20:
| 运算符 | 说明 | 举例 |
|---|---|---|
| && | 逻辑的 AND | [[ $a -lt 100 && $b -gt 100 ]] 返回 false |
| || | 逻辑的 OR | [[ $a -lt 100 |
实例
1 | |
执行脚本,输出结果如下所示:
1 | |
字符串运算符
下表列出了常用的字符串运算符,假定变量 a 为 “abc”,变量 b 为 “efg”:
| 运算符 | 说明 | 举例 |
|---|---|---|
| = | 检测两个字符串是否相等,相等返回 true。 | [ $a = $b ] 返回 false。 |
| != | 检测两个字符串是否相等,不相等返回 true。 | [ $a != $b ] 返回 true。 |
| -z | 检测字符串长度是否为0,为0返回 true。 | [ -z $a ] 返回 false。 |
| -n | 检测字符串长度是否不为 0,不为 0 返回 true。 | [ -n “$a” ] 返回 true。 |
| $ | 检测字符串是否为空,不为空返回 true。 | [ $a ] 返回 true。 |
实例
1 | |
执行脚本,输出结果如下所示:
1 | |
文件测试运算符
文件测试运算符用于检测 Unix 文件的各种属性。
属性检测描述如下:
| 操作符 | 说明 | 举例 |
|---|---|---|
| -b file | 检测文件是否是块设备文件,如果是,则返回 true。 | [ -b $file ] 返回 false。 |
| -c file | 检测文件是否是字符设备文件,如果是,则返回 true。 | [ -c $file ] 返回 false。 |
| -d file | 检测文件是否是目录,如果是,则返回 true。 | [ -d $file ] 返回 false。 |
| -f file | 检测文件是否是普通文件(既不是目录,也不是设备文件),如果是,则返回 true。 | [ -f $file ] 返回 true。 |
| -g file v检测文件是否设置了 SGID 位,如果是,则返回 true。其他检查符: | [ -g $file ] 返回 false。 | |
| -k file | 检测文件是否设置了粘着位(Sticky Bit),如果是,则返回 true。 | [ -k $file ] 返回 false。 |
| -p file | 检测文件是否是有名管道,如果是,则返回 true。 | [ -p $file ] 返回 false。 |
| -u file | 检测文件是否设置了 SUID 位,如果是,则返回 true。 | [ -u $file ] 返回 false。 |
| -r file | 检测文件是否可读,如果是,则返回 true。 | [ -r $file ] 返回 true。 |
| -w file | 检测文件是否可写,如果是,则返回 true。 | [ -w $file ] 返回 true。 |
| -x file | 检测文件是否可执行,如果是,则返回 true。 | [ -x $file ] 返回 true。 |
| -s file | 检测文件是否为空(文件大小是否大于0),不为空返回 true。 | [ -s $file ] 返回 true。 |
| -e file | 检测文件(包括目录)是否存在,如果是,则返回 true。 | [ -e $file ] 返回 true。其他检查符: |
其他检查符:
- -S: 判断某文件是否 socket。
- -L: 检测文件是否存在并且是一个符号链接。
实例
变量 file 表示文件 /var/www/runoob/test.sh,它的大小为 100 字节,具有 rwx 权限。下面的代码,将检测该文件的各种属性:
1 | |
执行脚本,输出结果如下所示:
1 | |
Shell printf 命令
printf 命令模仿 C 程序库(library)里的 printf() 程序。
printf 由 POSIX 标准所定义,因此使用 printf 的脚本比使用 echo 移植性好。
printf 使用引用文本或空格分隔的参数,外面可以在 printf 中使用格式化字符串,还可以制定字符串的宽度、左右对齐方式等。默认 printf 不会像 echo 自动添加换行符,我们可以手动添加 \n。
printf 命令的语法:
1 | |
参数说明:
- format-string: 为格式控制字符串
- arguments: 为参数列表。
实例如下:
1 | |
接下来,我来用一个脚本来体现printf的强大功能:
1 | |
执行脚本,输出结果如下所示:
1 | |
%s %c %d %f都是格式替代符
%-10s 指一个宽度为10个字符(-表示左对齐,没有则表示右对齐),任何字符都会被显示在10个字符宽的字符内,如果不足则自动以空格填充,超过也会将内容全部显示出来。
%-4.2f 指格式化为小数,其中.2指保留2位小数。
test命令
Shell中的 test 命令用于检查某个条件是否成立,它可以进行数值、字符和文件三个方面的测试。
数值测试
| 参数 | 说明 |
|---|---|
| -eq | 等于则为真 |
| -ne | 不等于则为真 |
| -gt | 大于则为真 |
| -ge | 大于等于则为真 |
| -lt | 小于则为真 |
| -le | 小于等于则为真 |
实例
1 | |
输出结果:
1 | |
代码中的 [] 执行基本的算数运算,如:
实例
1 | |
结果为:
1 | |
字符串测试
| 参数 | 说明 |
|---|---|
| = | 等于则为真 |
| != | 不相等则为真 |
| -z 字符串 | 字符串的长度为零则为真 |
| -n 字符串 | 字符串的长度不为零则为真 |
实例
1 | |
输出结果:
1 | |
文件测试
| 参数 | 说明 |
| -e 文件名 |如果文件存在则为真|
| -r 文件名 | 如果文件存在且可读则为真 |
| -w 文件名 | 如果文件存在且可写则为真 |
| -x 文件名 | 如果文件存在且可执行则为真|
|-s 文件名 | 如果文件存在且至少有一个字符则为真|
| -d 文件名 | 如果文件存在且为目录则为真 |
| -f 文件名 | 如果文件存在且为普通文件则为真 |
| -c 文件名 | 如果文件存在且为字符型特殊文件则为真 |
| -b 文件名 | 如果文件存在且为块特殊文件则为真 |
实例
1 | |
输出结果:
1 | |
另外,Shell 还提供了与( -a )、或( -o )、非( ! )三个逻辑操作符用于将测试条件连接起来,其优先级为: ! 最高, -a 次之, -o 最低。例如:
实例
1 | |
输出结果:
1 | |
参考链接
test命令用于查看文件是否存在、权限等信息,可以进行数值,字符,文件三方面的测试。
Shell 流程控制
if else
if 语句语法格式:
1 | |
写成一行(适用于终端命令提示符):
1 | |
末尾的fi就是if倒过来拼写,后面还会遇到类似的。
if else 语法格式:
1 | |
if else-if else 语法格式:
1 | |
以下实例判断两个变量是否相等:
1 | |
输出结果:
1 | |
if else语句经常与test命令结合使用,如下所示:
1 | |
输出结果:
1 | |
for 循环
for循环一般格式为:
1 | |
写成一行:
1 | |
上面格式对于习惯其他语言 for 循环的朋友来说可能有点别扭。下面格式的 for 循环与 C 中的相似,但并不完全相同。
1 | |
通常情况下 shell 变量调用需要加 $,但是 for 的 (()) 中不需要,下面来看一个例子:
1 | |
执行结果:
1 | |
当变量值在列表里,for循环即执行一次所有命令,使用变量名获取列表中的当前取值(注意这里的区别,这里的变量变成了列表中的值)。命令可为任何有效的shell命令和语句。in列表可以包含替换、字符串和文件名。
in列表是可选的,如果不用它,for循环使用命令行的位置参数。
例如,顺序输出当前列表中的数字:
1 | |
输出结果:
1 | |
顺序输出字符串中的字符:
1 | |
输出结果:
1 | |
while 语句
while循环用于不断执行一系列命令,也用于从输入文件中读取数据;命令通常为测试条件。其格式为:
1 | |
以下是一个基本的while循环,测试条件是:如果int小于等于5,那么条件返回真。int从0开始,每次循环处理时,int加1。运行上述脚本,返回数字1到5,然后终止。
1 | |
运行脚本,输出:
1 | |
以上实例使用了 Bash let 命令,它用于执行一个或多个表达式,变量计算中不需要加上 $ 来表示变量,具体可查阅:Bash let 命令。
无限循环
无限循环语法格式:
1 | |
或者
1 | |
或者
1 | |
until 循环
until 循环执行一系列命令直至条件为 true 时停止。
until 循环与 while 循环在处理方式上刚好相反。
一般 while 循环优于 until 循环,但在某些时候—也只是极少数情况下,until 循环更加有用。
until 语法格式:
1 | |
condition 一般为条件表达式,如果返回值为 false,则继续执行循环体内的语句,否则跳出循环。
以下实例我们使用 until 命令来输出 0 ~ 9 的数字:
1 | |
运行结果:
1 | |
case
case … esac 与其他语言中的 switch … case 语句类似,是一种多分枝选择结构,每个 case 分支用右圆括号开始,用两个分号 ;; 表示 break,即执行结束,跳出整个 case … esac 语句,esac(就是 case 反过来)作为结束标记。case语句格式如下:
1 | |
case工作方式如上所示。取值后面必须为单词in,每一模式必须以右括号结束。取值可以为变量或常数。匹配发现取值符合某一模式后,其间所有命令开始执行直至 ;;。
取值将检测匹配的每一个模式。一旦模式匹配,则执行完匹配模式相应命令后不再继续其他模式。如果无一匹配模式,使用星号 * 捕获该值,再执行后面的命令。
下面的脚本提示输入1到4,与每一种模式进行匹配:
1 | |
输入不同的内容,会有不同的结果,例如:
1 | |
跳出循环
在循环过程中,有时候需要在未达到循环结束条件时强制跳出循环,Shell使用两个命令来实现该功能:break和continue。
break命令
break命令允许跳出所有循环(终止执行后面的所有循环)。
下面的例子中,脚本进入死循环直至用户输入数字大于5。要跳出这个循环,返回到shell提示符下,需要使用break命令。
1 | |
执行以上代码,输出结果为:
1 | |
continue
continue命令与break命令类似,只有一点差别,它不会跳出所有循环,仅仅跳出当前循环。
对上面的例子进行修改:
1 | |
运行代码发现,当输入大于5的数字时,该例中的循环不会结束,语句 echo “游戏结束” 永远不会被执行。
Shell函数
linux shell 可以用户定义函数,然后在shell脚本中可以随便调用。
shell中函数的定义格式如下:
1 | |
说明:
- 1、可以带function fun() 定义,也可以直接fun() 定义,不带任何参数。
- 2、参数返回,可以显示加:return 返回,如果不加,将以最后一条命令运行结果,作为返回值。 return后跟数值n(0-255
下面的例子定义了一个函数并进行调用:
1 | |
输出结果:
1 | |
下面定义一个带有return语句的函数:
1 | |
输出类似下面:
1 | |
函数返回值在调用该函数后通过 $? 来获得。
注意:所有函数在使用前必须定义。这意味着必须将函数放在脚本开始部分,直至shell解释器首次发现它时,才可以使用。调用函数仅使用其函数名即可。
函数参数
在Shell中,调用函数时可以向其传递参数。在函数体内部,通过 $n 的形式来获取参数的值,例如,$1表示第一个参数,$2表示第二个参数…
带参数的函数示例:
1 | |
输出结果:
1 | |
注意,$10 不能获取第十个参数,获取第十个参数需要${10}。当n>=10时,需要使用${n}来获取参数。
另外,还有几个特殊字符用来处理参数:
| 参数处理 | 说明 |
|---|---|
| $# | 传递到脚本或函数的参数个数 |
| $* | 以一个单字符串显示所有向脚本传递的参数 |
| $$ | 脚本运行的当前进程ID号 |
| $! | 后台运行的最后一个进程的ID号 |
| $@ | 与$*相同,但是使用时加引号,并在引号中返回每个参数。 |
| $- | 显示Shell使用的当前选项,与set命令功能相同。 |
| $? | 显示最后命令的退出状态。0表示没有错误,其他任何值表明有错误。 |
裸机开发篇
一、开发环境搭建
VIM编辑器
Linux系统都会自带vi编辑器,但是vi编辑器太难用了!所以建议大家安装vim编辑器,安装命令:sudo apt-get install vim
NFS
sudo apt-get install nfs-kernel-server rpcbind
新建 linux->nfs 文件夹
sudo vi /etc/exports
文件后追加/home/用户名/linux/nfs *(rw,sync,no_root_squash)sudo /etc/init.d/nfs-kernel-server restart 重启服务
SSH
sudo apt-get install openssh-server 开启服务
配置文件为/etc/ssh/sshd_config,使用默认配置即可。
vscode
图标都在目录/usr/share/applications 中,找到 Visual Studio Code 的图标,点击鼠标右键,选择复制到->桌面
插件:
- C/C++,这个肯定是必须的。
- C/C++ Snippets,即 C/C++重用代码块
- C/C++ Advanced Lint,即 C/C++静态检测 。
- Code Runner,即代码运行。
- Include AutoComplete,即自动头文件包含。
- GBKtoUTF8,将 GBK 转换为 UTF8。
- ARM,即支持 ARM 汇编语法高亮显示。
- compareit,比较插件,可以用于比较两个文件的差异。
- DeviceTree,设备树语法插件。
- TabNine,一款 AI 自动补全插件,强烈推荐,谁用谁知道!
FTP 服务(文件互传)
这里的互传不是使用 VirtualBox 的扩展功能,而是借用 FTP 服务,这样,我们就可以远程互传文件。
开启Ubuntu下的FTP服务
安装FTP服务:
1 | |
安装完成以后使用如下VI命令打开/etc/vsftpd.conf:
1 | |
找到如下两行:
1 | |
确保上面两行前面没有“#”,有的话就取消掉,完成以后如图所示:

修改修改完vsftpd.conf以后保存退出,使用如下命令重启FTP服务:
1 | |
Windows 下 FTP 安装
ip地址
这里是一个大坑,为了避免问题,需要有限解决该问题。
我们先在Ubuntu的命令行输入 ifconfig 查询虚拟机当前的地址:
期间可能会提示没有 ifconfig ,如下,根据提示输入指令 sudo apt install net-tools 安装即可
1 | |
1 | |
第三行的 192.168.1.9 就是我们的网络地址了。你的可能跟会和我的不同,后面会解决该问题。
我们接着打开 Windows的命令行输出 ipconfig 查询电脑主机网络地址:
1 | |
以太网适配器 以太网:项中的 IPv4 地址:192.168.1.7 就是我们的主机地址了。可以看到和我们的虚拟主机地址只有最后一位不一样的,如果你的虚拟机不知最后一位不一样,如:10.0.2.15。那就说明网络设置有错误,我们需要修改 VirtualBox 软件的网络配置。
- Ubuntu 关键,进入 VirtualBox的网络配置界面:
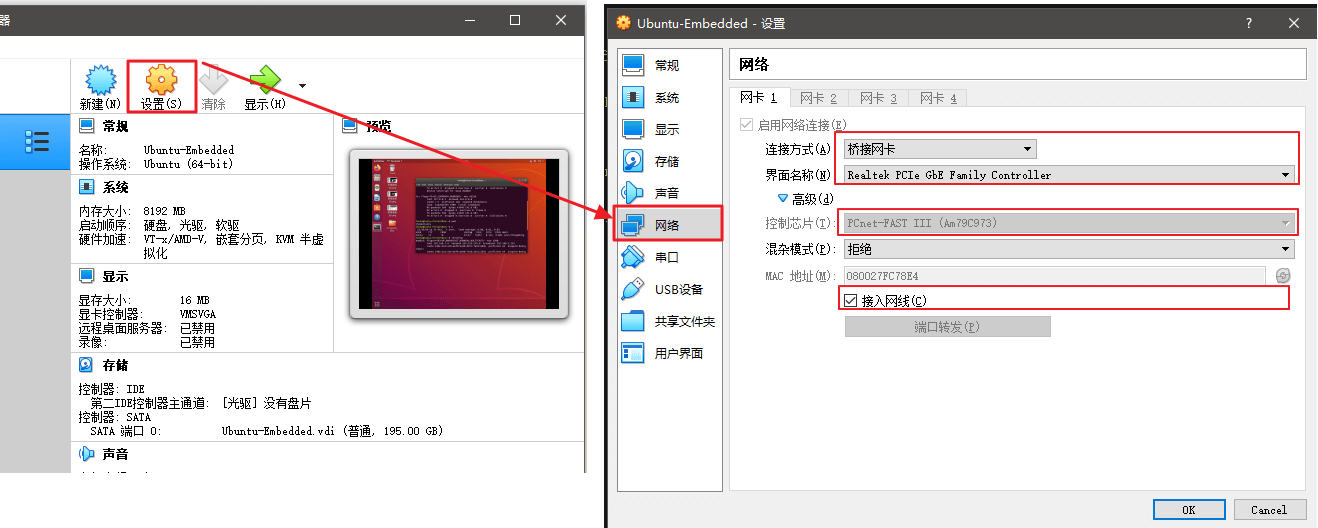
按如下要求设置
- 连接方式 选择 桥接网卡
- 界面名称 选择 (需要根据现在的上网方式对应选择,当前是无线联网就选无线网卡,有线选有线网卡)
- 高级-控制芯片 一般是选择 PCnet-FAST III,如果你的有多个,可以尝试不同配置(如果不能上网的话)
- 高级-混杂模式 拒绝
- 高级-接入网线 √
重启 ubuntu,再重新查看IP地址,确保虚拟机和主机的IP地址只有最后一位不同即可(仅主机(Host-Only)网络模式下,有两位不同)。为了保险起见,我们可以在windows命令行中 ping 一下虚拟机地址。
1 | |
可以看到网络能够ping通(虚拟机有回复)。
此时我们就可以将虚拟机地址点入上面的设置中了。
指定ip地址
虚拟机的 ip 地址是随机分配的,每次开机时可能会不一样,这样每次我们都需要重新设置 Ip 地址,我们可以通过指定ip地址,来保持一致。
- 首先要先查看 Windows 的ip地址
上面已经查过了:192.168.1.7 - 修改最后一位(不超过254),并Windows 下 ping 一下该地址,保证 ping 不同,也就是没用到该地址。
1
2
3
4
5
6
7
8C:\Users\23714>ping 192.168.1.254
正在 Ping 192.168.1.254 具有 32 字节的数据:
来自 192.168.1.7 的回复: 无法访问目标主机。
来自 192.168.1.8 的回复: 无法访问目标主机。
192.168.1.254 的 Ping 统计信息:
数据包: 已发送 = 2,已接收 = 2,丢失 = 0 (0% 丢失), - 进入Ubuntu,找到设置 -> 网络,Wired 选项中点击设置图标,再选中 IPV4,按如下配置
- 如果有两个网卡,例如启用了网卡2:主机(Host-Only)网络模式,这里会有两个网络,需要区分一下(只修改IP地址能ping通的那个网络)
- Adress: 上一步修改的ip地址
- Netmask:windows 下查询的的
以太网适配器 以太网:下的子网掩码 - Gateway:
以太网适配器 以太网:默认网关 - DNS 一般是和网关类似,再最后一位是1
- 右上角 Apply 保存。重启Ubuntu,再次查看IP地址,即可看到已经修改过来了。
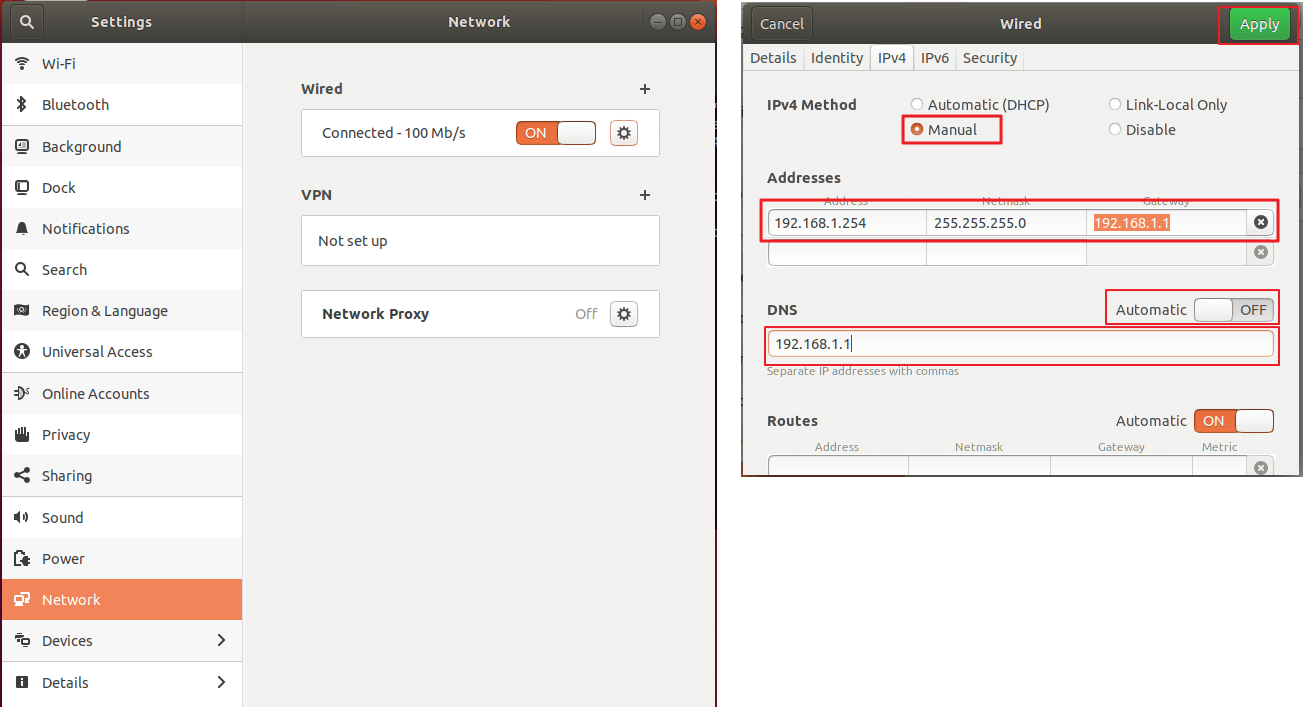
FTP安装
下载地址:FileZilla官网
下载后,安装一路默认即可,可更改安装路径。
打开站点管理器,点击:文件->站点管理器,或者直接点击左上角图标
打开以后,按下图所示设置:
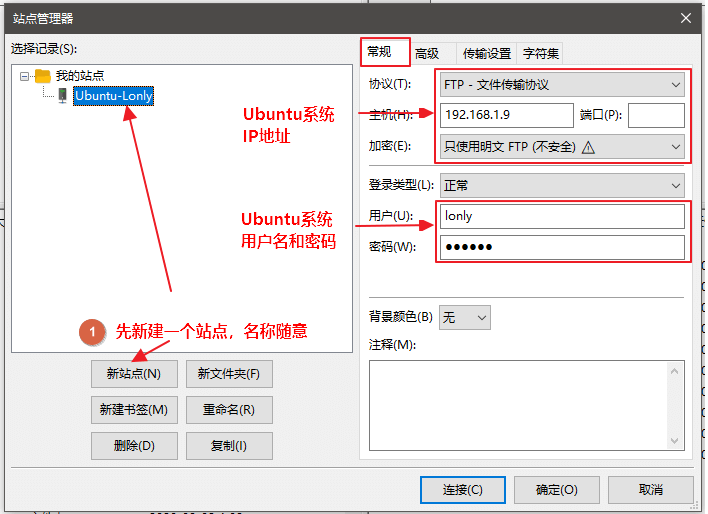
其中用户名就是当前登录的用户,注意不是系统登录界面显示的那个。我们可以使用命令查看:
1 | |
pwd或w命令都可以,可以看到当前用户名是lonly.
密码就是开机的登录密码了
连接成功后,会看到如下界面,左边是 Windows 系统的目录文件,右边是Ubuntu 系统的目录文件。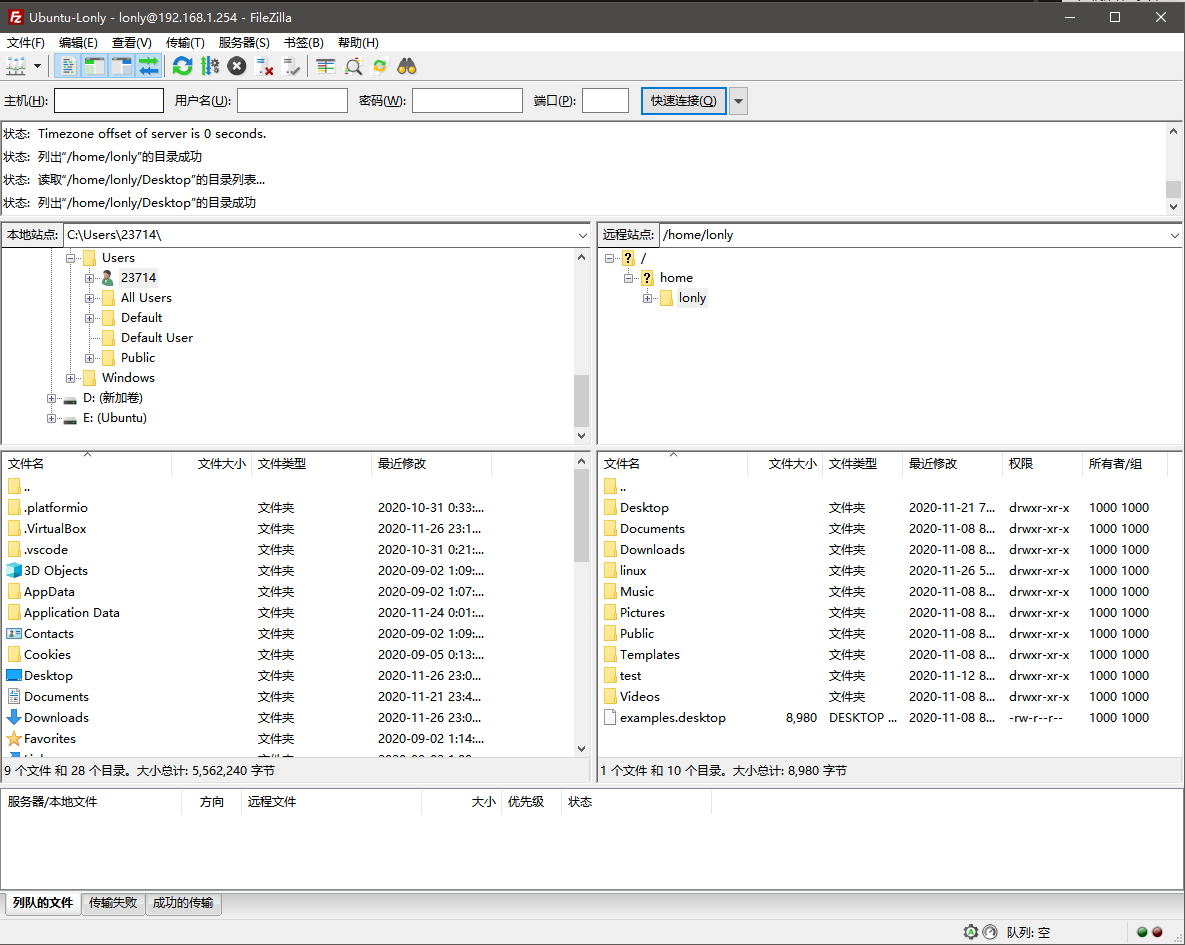
但是Ubuntu 文件目录下的中文目录都是乱码的,这是因为编码方式没有选对,先断开连接,点击:
服务器(S)->断开连接,然后打开站点管理器,选中要设置的站点“Ubuntu”,选择“字符集”,
设置所示: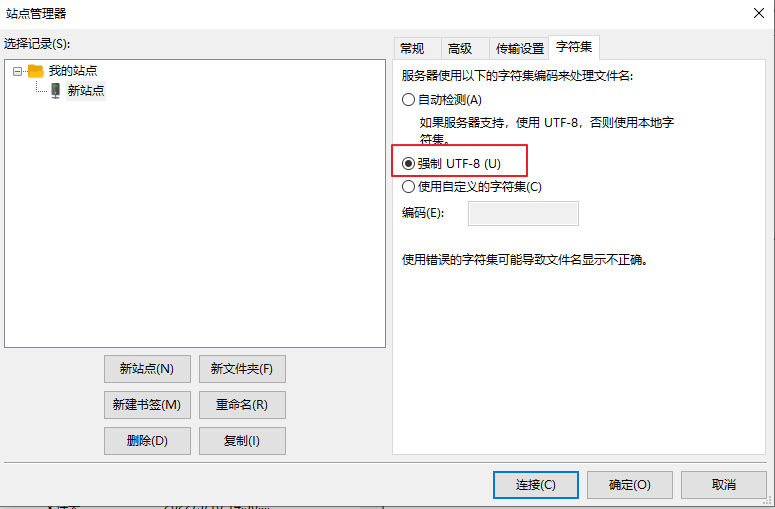
参考链接:
- VirtualBox虚拟机网络设置(四种方式)
- VirtualBox 网络模式总结
- VirtualBox虚拟机网络搭建NAT、桥接、Host-Only、Internal等(centos7)
- Windows下VirtualBox虚拟机互ping+外网配置
NFS和SSH服务开启
NFS服务开启
后面进行Linux驱动开发的时候需要NFS启动,因此要先安装并开启Ubuntu中的NFS服务,使用如下命令安装NFS服务:
1 | |
等待安装完成,安装完成以后在用户根目录下创建一个名为“linux”的文件夹,以后所有的东西都放到这个“linux”文件夹里面,在“linux”文件夹里面新建一个名为“nfs”的文件夹
1 | |
创建的nfs文件夹供nfs服务器使用,以后我们可以在开发板上通过网络文件系统来访问nfs文件夹,要先配置nfs,使用如下命令打开nfs配置文件 exports:
1 | |
打开/etc/exports以后在后面添加如下所示内容:
1 | |
添加完成以后的/etc/exports如下所示:
1 | |
重启NFS服务,使用命令如下:
1 | |
SSH服务开启开启
Ubuntu的SSH服务以后我们就可以在Windwos下使用终端软件登陆到Ubuntu,比如使用SecureCRT,Ubuntu下使用如下命令开启SSH服务:
1 | |
上述命令安装ssh服务,ssh的配置文件为/etc/ssh/sshd_config,使用默认配置即可。
交叉编译器安装
下载地址如下:https://www.linaro.org/
从官方很难找到编译器下载地址,建议使用一下链接直接进入下载界面
Linaro GCC 编译器:https://releases.linaro.org/components/toolchain/binaries/
经测试,这里不能安装最新版本,会导致后面uboot编译出问题(正常程序的编译没问题),会导致在uboot中无法使用 dhcp 和ping 命令。所以不要使用最新版!不要使用最新!不要使用最新!请下载和正点原子教程同样的版本 4.9.4-2017.01
下载地址: https://releases.linaro.org/components/toolchain/binaries/4.9-2017.01/arm-linux-gnueabihf/
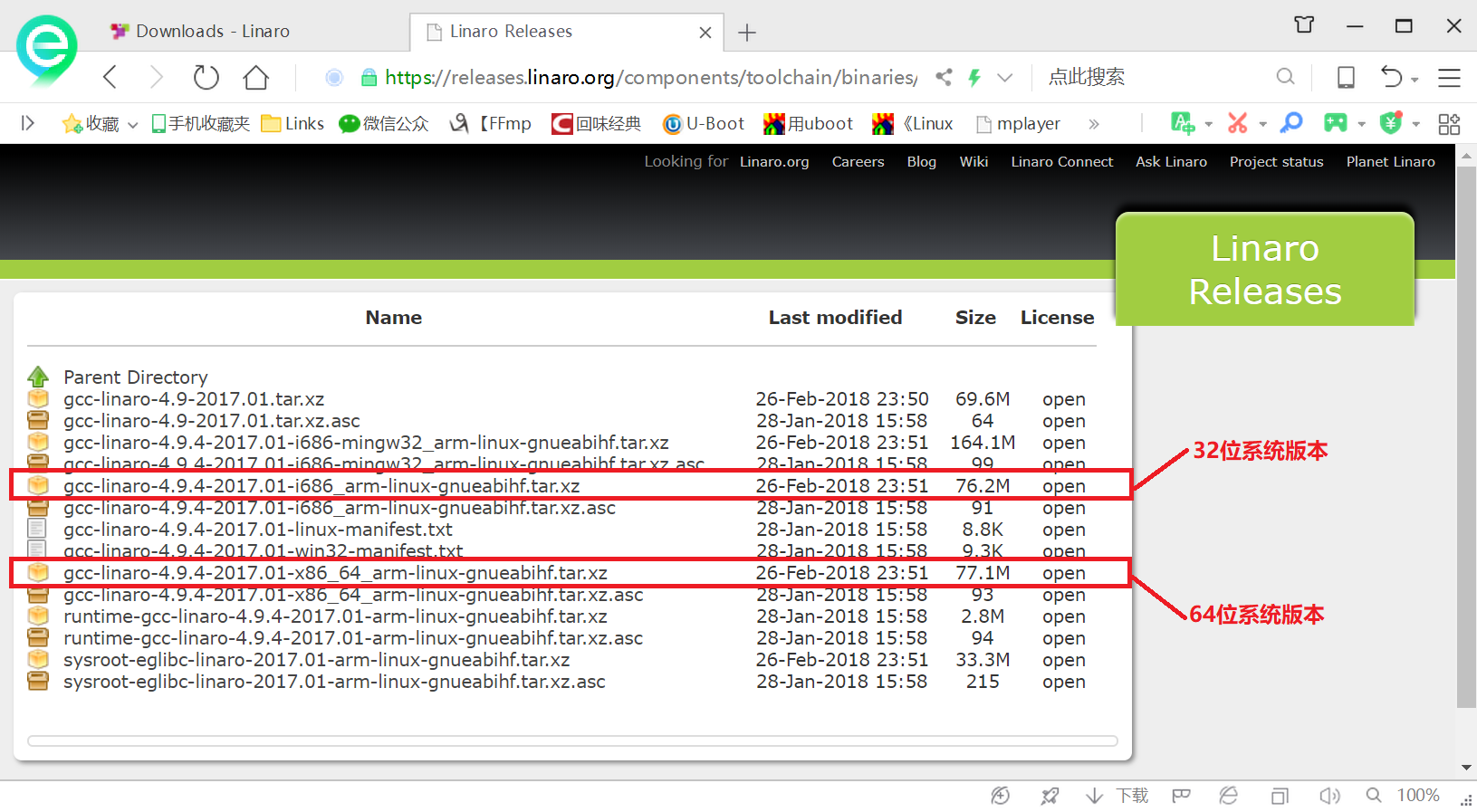
参考资料:
进入下面的下载界面,其中有很多种交叉编译器,我们只需要关注红框中部分,一个是针对32位系统的,第二个是针对64位系统的。大家根据自己所使用的Ubuntu系统类型选择合适的版本,我安装的Ubuntu16.04是64位系统,因此我要
使用 gcc-linaro-7.5.0-2019.12-x86_64_arm-linux-gnueabihf.tar.xz。
创建一个“tool”的文件夹: linux/tool,存放开发工具(这里只是存放,安装在别的位置)。使用前面已经安装好的FileZilla将交叉编译器拷贝到Ubuntu中刚刚新建的“tool”文件夹中。
在Ubuntu中创建目录:sudo mkdir /usr/local/arm。存放编译器
进入tool目录,将交叉编译器下载文件(不要解压、不要解压)复制到arm目录中sudo cp gcc-linaro-7.5.0-2019.12-x86_64_arm-linux-gnueabihf.tar.xz /usr/local/arm/ -f
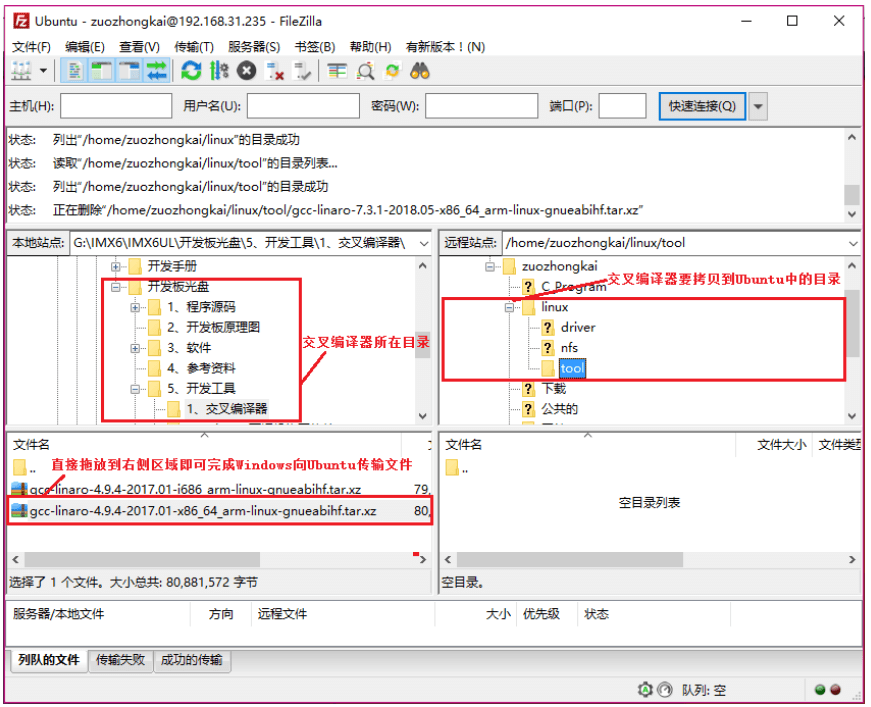
这里一定要保证压缩文件名是.xz 结尾,否则后面uboot编译时会出错,下图第第二个文件就是错的
进入arm目录,解压:sudo tar -vxf gcc-linaro-7.5.0-2019.12-x86_64_arm-linux-gnueabihf.tar.xz
修改环境变量,sudo vi /etc/profile
最后面输入如下所示内容:export PATH=$PATH:/usr/local/arm/gcc-linaro-7.5.0-2019.12-x86_64_arm-linux-gnueabihf/bin
添加完成以后的/etc/profile如下图所示
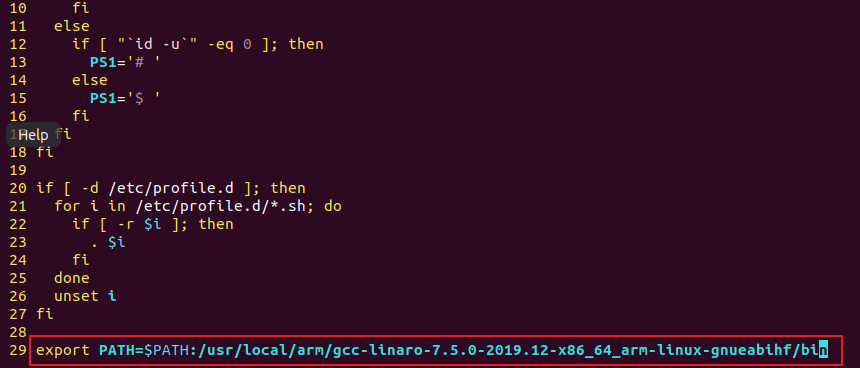
修改好以后就保存退出,重启Ubuntu系统,交叉编译工具链(编译器)就安装成功了。
安装相关库:sudo apt-get install lsb-core lib32stdc++6
验证:arm-linux-gnueabihf-gcc -v
如果交叉编译器安装正确的话就会显示版本号,如下图所示: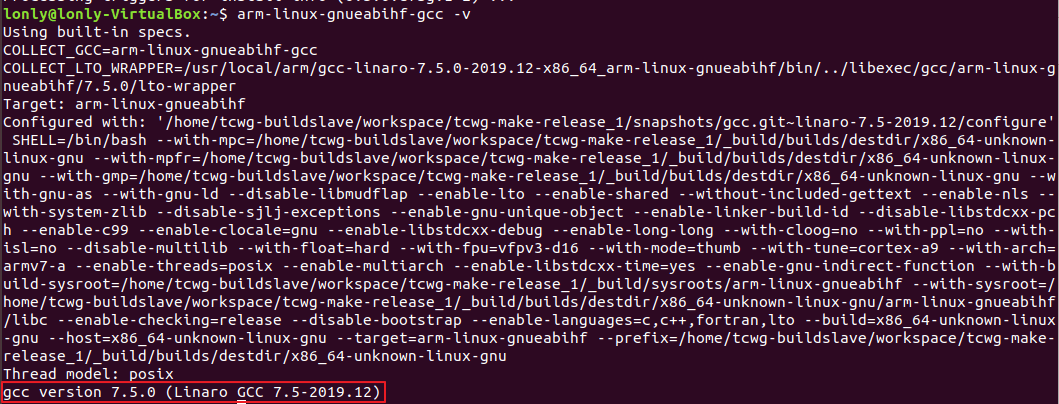
注意,以下内容一定要有,特别是COLLECT_LTO_WRAPPER这一行。这一行没有的话,裸机编译可能没错,但是后面的uboot移植编译就会出错
编译第一个裸机例程“1_leds”试试,在前面创建的linux文件夹下创建driver/board_driver文件夹,用来存放裸机例程
将第一个裸机例程“1_leds”拷贝到board_driver中,然后执行make命令进行编译,
1 | |
可以看到例程“1_leds”编译成功了,编译生成了led.o和led.bin这两个文件,使用如下命令查看led.o文件信息:
1 | |
可以看到led.o是32位LSB 的ELF格式文件,目标机架构为ARM,说明我们的交叉编译器工作正常
VisualStudioCode软件的安装和使用
VSCode是微软出的一款编辑器,但是免费的。VSCode有Windows、Linux和macOS三个版本的,是一个跨平台的编辑器。VSCode下载地址是:https://code.visualstudio.com/
本教程需要Windows和Linux这两个版本,所以下载这两个即可
windows版本安装
默认安装即可。
Linux版本安装
在Ubuntu主要是阅读代码,不要用于编写代码等用途(请培养 VIM 的使用习惯 )
直接在应用商店搜索下载安装即可,速度可能比较慢,但不要退出,否则重装很麻烦。
VisualStudio Code插件的安装
VSCode支持多种语言,比如C/C++、Python、C#等等,本教程我们主要用来编写C/C++程序的,所以需要安装C/C++的扩展包,扩展包安装很简单,如图所示: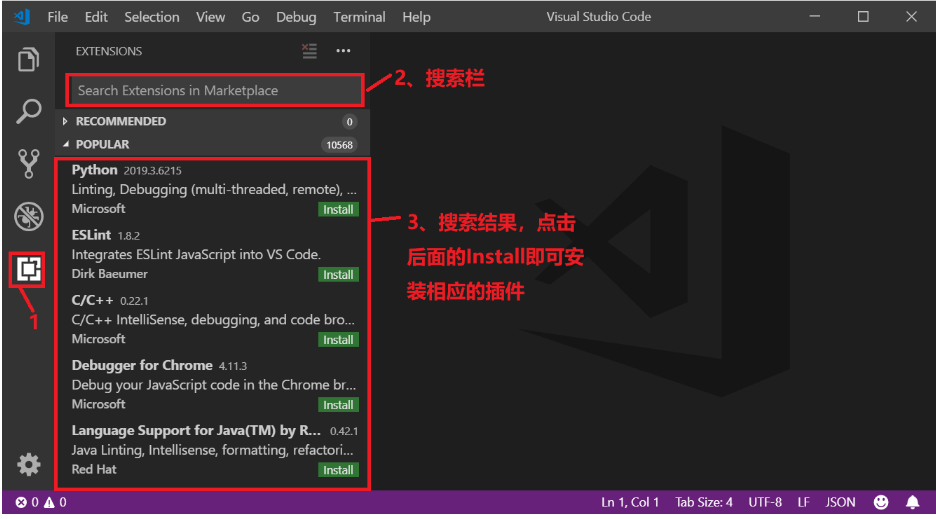
我们需要按照的插件有下面几个:
- C/C++,这个肯定是必须的。
- C/C++ Snippets,即C/C++重用代码块。
- C/C++ Advanced Lint,即C/C++静态检测。
- CodeRunner,即代码运行。
- IncludeAutoComplete,即自动头文件包含。
- Rainbow Brackets,彩虹花括号,有助于阅读代码。可选
- OneDarkPro,VSCode的主题。可选
- GBKtoUTF8,将GBK转换为UTF8
- ARM,即支持ARM汇编语法高亮显示
- Chinese(Simplified),即中文环境。可选
- vscode-icons,VSCode图标插件,主要是资源管理器下各个文件夹的图标。可选
- compareit,比较插件,可以用于比较两个文件的差异。
- DeviceTree,设备树语法插件。
- TabNine,一款AI自动补全插件,强烈推荐,谁用谁知道!
VisualStudioCode新建工程
新建一个文件夹用于存放工程,比如我新建了文件夹目录为E:\VScode_Program\1_test,路径尽量不要有中文和空格。
然后打开VSCode,点击文件->打开文件夹…,选刚刚创建的“1_test”文件夹,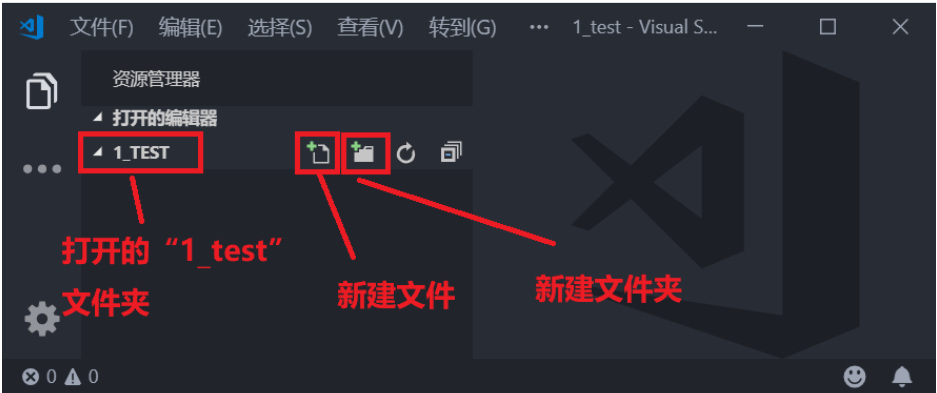
可以看出此时的文件夹“1_TEST”是空的,点击文件->将工作区另存为…,打开工作区命名对话框,输入要保存的工作区路径和工作区名字,如图所示: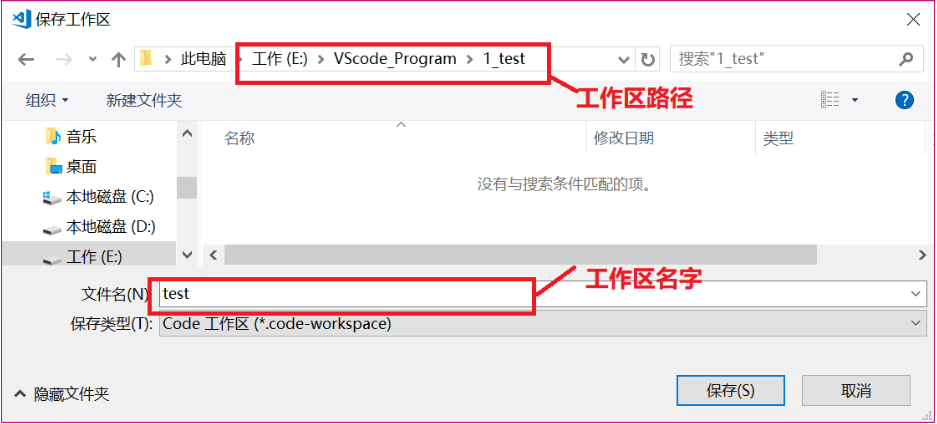
工作区保存成功以后,点击“新建文件”按钮创建main.c和main.h这两个文件,创建成功以后VSCode如图所示: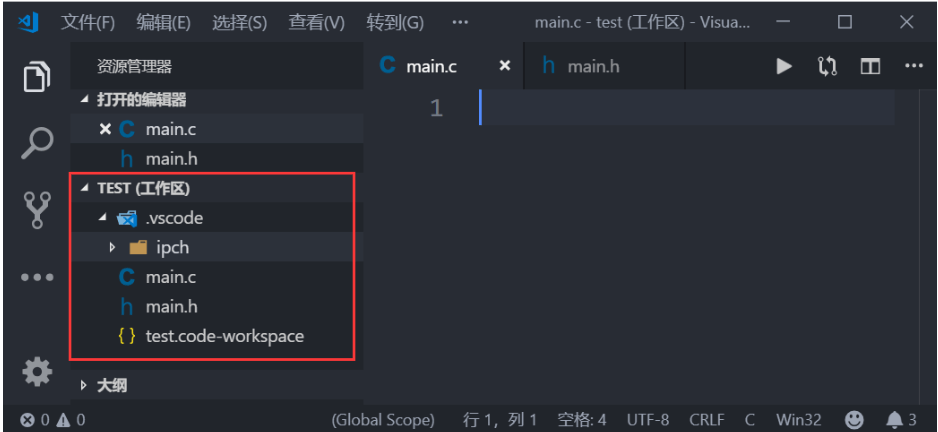
之后就可以编写代码了。
CH340串口驱动安装
我们一般在Windwos下通过串口来调试程序,或者使用串口作为终端,I.MX6U-ALPHA开发板使用CH340这个芯片实现了USB转串口功能,。先通过USB线将开发板的串口和电脑连接起来起来
一定要先将开发板与电脑连接,否则驱动会安装失败。

点击 “安装”按钮开始安装驱动,等待驱动安装完成。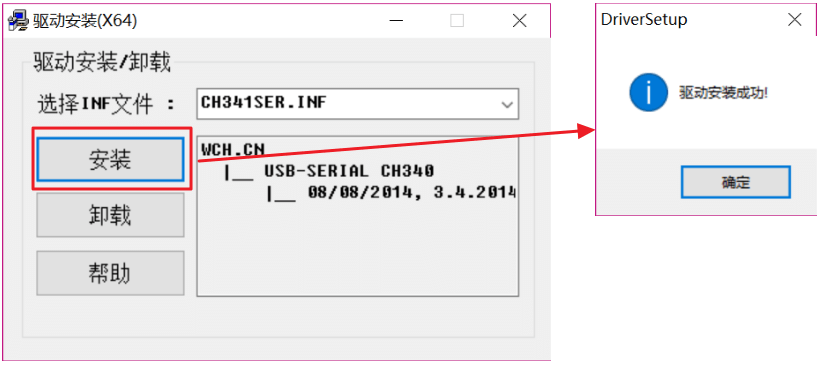
进入设备管理器 -> 端口,可以看到有“USB-SERIAL CH340”字样的端口设备就说明CH340驱动成功了。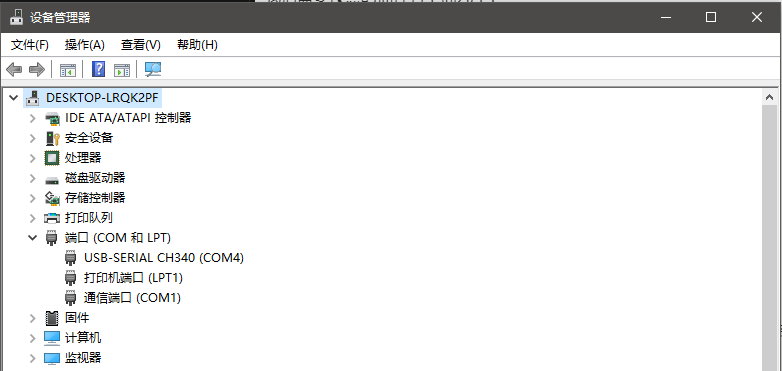
Putty软件的安装和使用
Putty软件是用来作为SSH或者串口终端的,虽然Putty没有SecureCRT功能强大,但是Putty用来作为嵌入式Linux的串口终端是绰绰有余。Putty在官网下载即可,下载地址为:Download PuTTY。下载界面如图所示
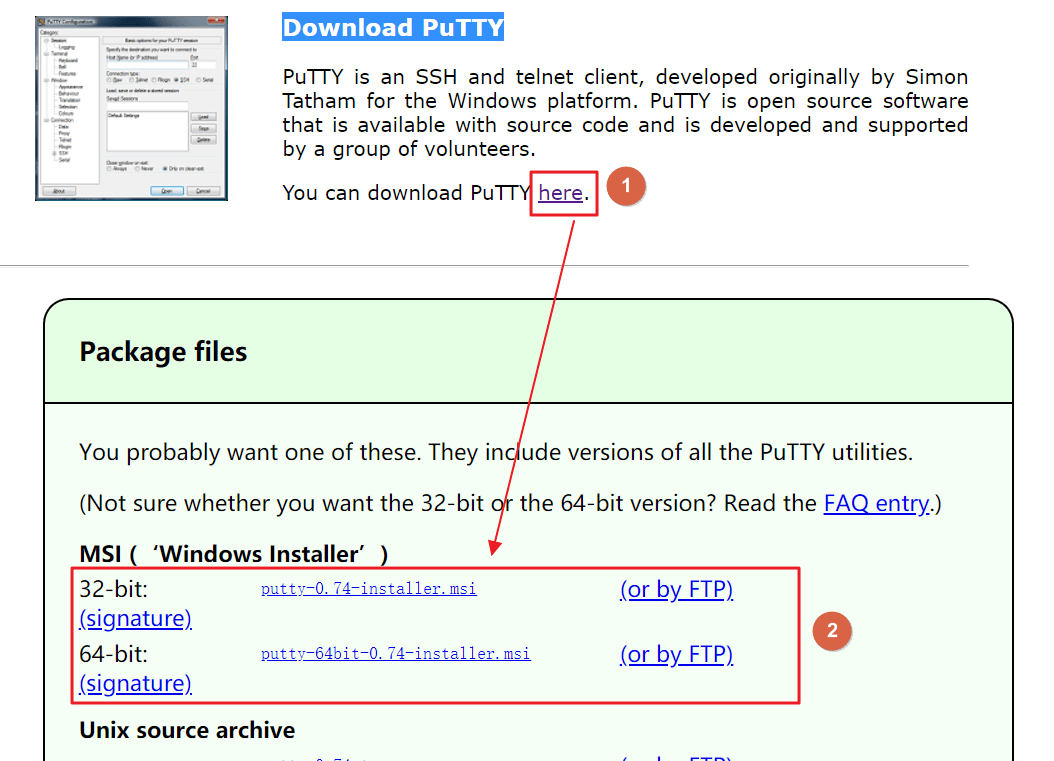
根据自己电脑下载 32位或64位版本,双击开始安装,安装一路默认即可,可自行更改安装路径。
Putty软件使用
使用USB线将开发板串口和电脑连接起来,打开Putty软件,打开以后是配置界面。
我们要用到串口功能,所以在左侧选择“Serial”,然后在右侧配置串口,配置完成以后如下左半图所示;还需要设置“Session”,设置如下右半图所示。
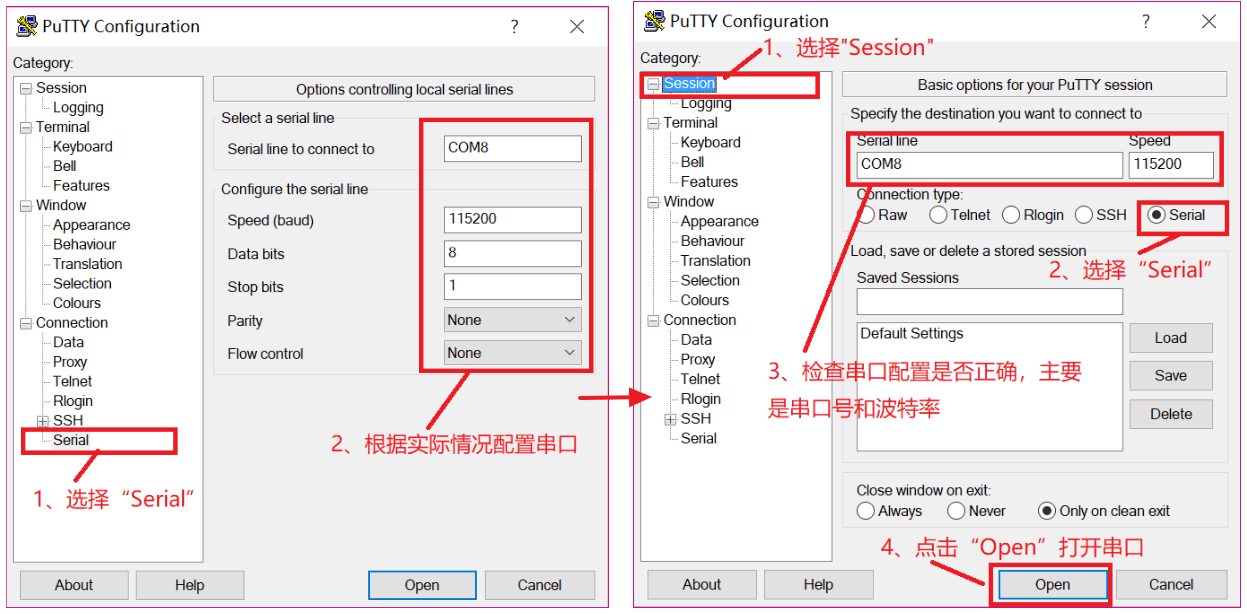
设置好以后,点击“Open”打开串口。此时重启开发板,如果开发板里面烧写了Linux系统的话,Putty就会显示Linux启动过程的信息,并且作为开发板的终端,如图所示: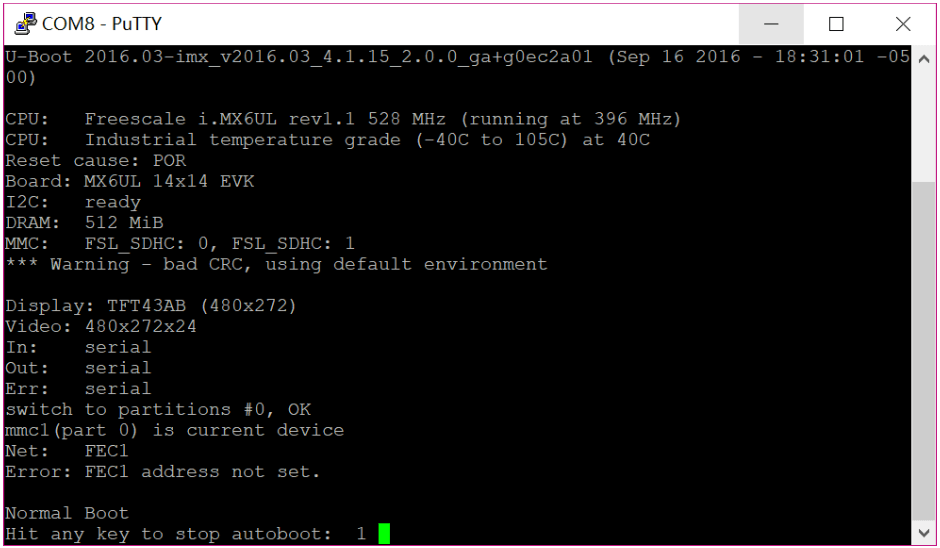
另外还有一款类似的但功能更加强大的软件:MobaXterm。但我们开发时仅作为串口终端,所以 Putty 已完全满足需求。
MobaXterm 软件安装和使用
https://mobaxterm.mobatek.net
点击菜单栏中的“Sessions->New session”按钮,打开新建会话窗口
串口设置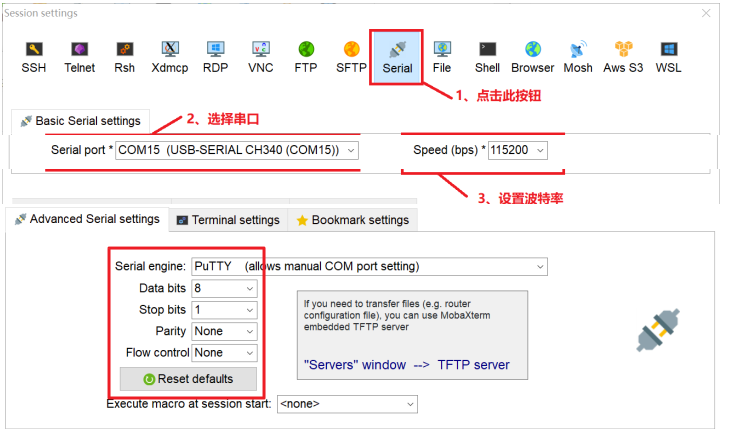
Cortex-A7 MPCore架构
Cortex-A处理器运行模型
STM32只有两种运行模式,特权模式和非特权模式,但是Cortex-A就有9种运行模式。
以前的ARM处理器有7中运行模型:User、FIQ、IRQ、Supervisor(SVC)、Abort、Undef和System,其中User是非特权模式,其余6中都是特权模式。但新的Cortex-A7处理器有9种处理模式,如表所示: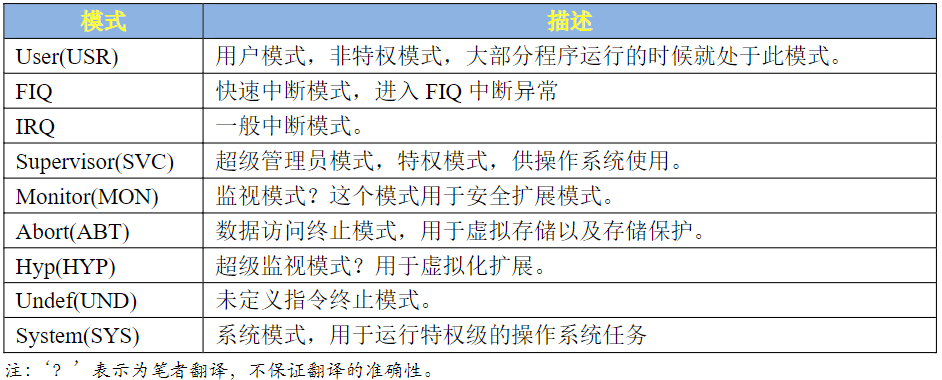
- 在表中,除了User(USR)用户模式以外,其它8种运行模式都是特权模式。
- 这几个运行模式可以通过软件进行任意切换,也可以通过中断或者异常来进行切换。
- 大多数的程序都运行在用户模式,用户模式下是不能访问系统所有资源的,有些资源是受限的,要想访问这些受限的资源就必须进行模式切换。
- 用户模式是不能直接进行切换的,需要借助异常来完成模式切换,当要切换模式的时候,应用程序可以产生异常,在异常的处理过程中完成处理器模式切换。
当中断或者异常发生以后,处理器就会进入到相应的异常模式种,每一种模式都有一组寄存器供异常处理程序使用,这样的目的是为了保证在进入异常模式以后,用户模式下的寄存器不会被破坏。
Cortex-A寄存器组
ARM架构提供了16个32位的通用寄存器(R0~R15)供软件使用
- R0~R14 可以用作通用的数据存储,
- R15是程序计数器PC,用来保存将要执行的指令
还提供了程序状态寄存器
- 当前程序状态寄存器CPSR
- 备份程序状态寄存器SPSR,SPSR寄存器就是CPSR寄存器的备份。
这18个寄存器如图所示: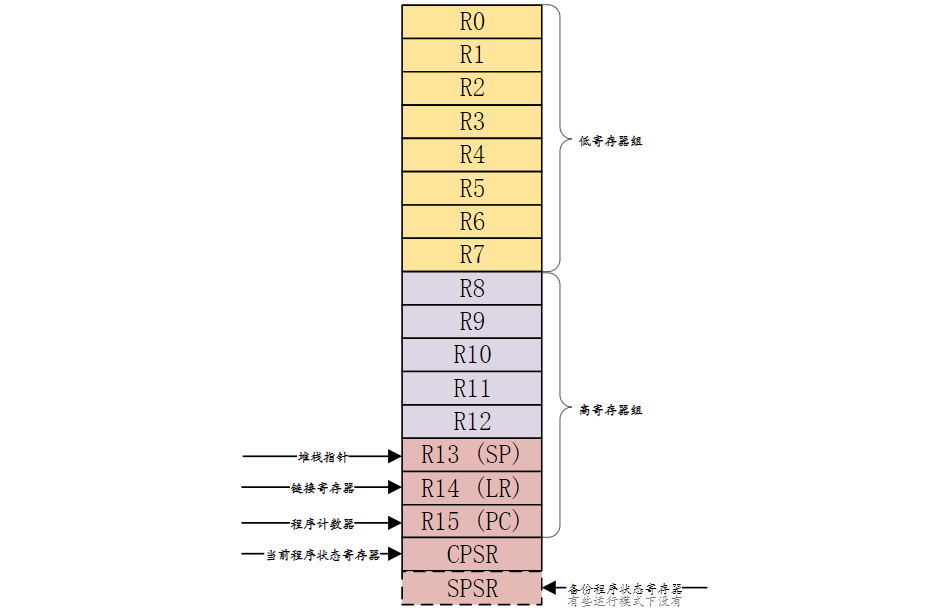
Cortex-A7有9种运行模式
- 每一种运行模式都有一组与之对应的寄存器组。
- 每一种模式可见的寄存器包括15个通用寄存器(R0~R14),一两个程序状态寄存器和一个程序计数器PC。
在这些寄存器中,有些是所有模式所共用的同一个物理寄存器,有一些是各模式自己所独立拥有的,各个模式所拥有的寄存器如图所示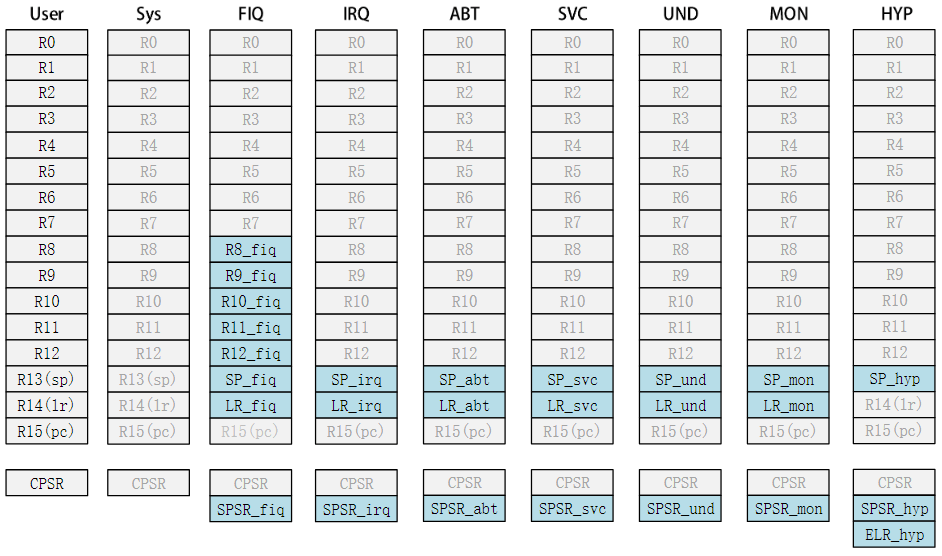
- 图中浅色字体的是与User模式所共有的寄存器
- 蓝绿色背景的是各个模式所独有的寄存器
可以看出,在所有的模式中
- 低寄存器组(R0~R7)是共享同一组物理寄存器的,只是一些高寄存器组在不同的模式有自己独有的寄存器
- 只有一个 R15 程序计数器(PC)
- 比如FIQ模式下R8~R14是独立的物理寄存器。假如某个程序在FIQ模式下访问R13寄存器,那它实际访问的是寄存器R13_fiq,
- 如果程序处于SVC模式下访问R13寄存器,那它实际访问的是寄存器R13_svc。
总结一下,Cortex-A内核寄存器组成如下:
- 34个通用寄存器,包括R15程序计数器(PC),这些寄存器都是32位的。
- 8个状态寄存器,包括CPSR和SPSR。
- Hyp模式下独有一个ELR_Hyp寄存器。
通用寄存器
请配合上图阅读该小节文字,R0~R15就是通用寄存器,通用寄存器可以分为以下三类:
- 未备份寄存器,即R0~R7。
- 备份寄存器,即R8~R14。
- 程序计数器PC,即R15。
分别来看一下这三类寄存器
1、未备份寄存器
R0~R7。所有的运行模式共享这8个寄存器,在不同的模式下,这8个寄存器中的数据就会被破坏。所以这8个寄存器并没有被用作特殊用途。
2、备份寄存器
R8R12。快速中断模式下(FIQ)独有 **Rx_irq(x=812)** 物理寄存器,其他模式下共享 Rx(8~12) 物理寄存器。
FIQ模式要求快速执行!因为FIQ模式下的R8~R12是独立的,因此中断处理程序可以不用执行保存和恢复中断现场的指令,从而加速中断的执行过程。
R13。一共有8个不同物理寄存器,其中一个是用户模式(User)和系统模式(Sys)共用的,剩下的7个分别对应7种不同的模式。
R13也叫做SP,用来做为栈指针。基本上每种模式都有一个自己的R13物理寄存器,应用程序会初始化R13,使其指向该模式专用的栈地址,这就是常说的初始化SP指针。
R14。一共有7个物理寄存器,其中一个是用户模式(User)、系统模式(Sys)和超级监视模式(Hyp)所共有的,剩下的6个分别对应6种不同的模式。R14也称为连接寄存器(LR),LR寄存器在ARM中主要用作如下两种用途:
- 每种模式使用R14(LR)来存放当前子程序的返回地址,如果使用BL(汇编代码)或者BLX(汇编代码)来调用子函数的话, R14(LR)被设置成该子函数的返回地址,在子函数中,将R14(LR)中的值赋给R15(PC)即可完成子函数返回,比如在子程序中可以使用如下代码:或者可以在子函数的入口出将LR入栈:
1
MOV PC, LR @寄存器LR中的值赋值给PC,实现跳转在子函数的最后面出栈即可:1
PUSH {LR}@将LR寄存器压栈1
POP {PC}@将上面压栈的LR寄存器数据出栈给PC寄存器,严格意义上来讲应该是将@LR-4赋给PC,因为3级流水线,这里只是演示代码。 - 当异常发生以后,该异常模式对应的R14寄存器被设置成该异常模式将要返回的地址,R14也可以当作普通寄存器使用
3、程序计数器R15
R15。也叫做PC,R15保存着当前执行的指令地址值加8个字节,这是因为ARM的流水线机制导致的。ARM处理器3级流水线:
取指->译码->执行
这三级流水线循环执行,比如当前正在执行第一条指令的同时也对第二条指令进行译码,第三条指令也同时被取出存放在R15(PC)中。我们喜欢以当前正在执行的指令作为参考点,也就是以第一条指令为参考点,那么R15(PC)中存放的就是第三条指令,换句话说就是R15(PC)总是指向当前正在执行的指令地址再加上2条指令的地址。对于32位的ARM处理器,每条指令是4个字节,所以:
1 | |
程序状态寄存器
所有的处理器模式都共用一个CPSR物理寄存器,因此CPSR可以在任何模式下被访问。该寄存器包含了条件标志位、中断禁止位、当前处理器模式标志等一些状态位以及一些控制位。所有的处理器模式都共用一个CPSR必然会导致冲突,为此,除了User和Sys这两个模式以外,其他7个模式每个都配备了一个专用的物理状态寄存器,叫做SPSR(备份程序状态寄存器),当特定的异常中断发生时,SPSR寄存器用来保存当前程序状态寄存器(CPSR)的值,当异常退出以后可以用SPSR中保存的值来恢复CPSR。
因为User和Sys这两个模式不是异常模式,所以并没有配备SPSR,因此不能在User和Sys模式下访问SPSR,会导致不可预知的结果。由于SPSR是CPSR的备份,因此SPSR和CPSR的寄存器结构相同,如图所示:

N(bit31): 当两个补码表示的有符号整数运算的时候,N=1表示运算对的结果为负数,N=0表示结果为正数。
Z(bit30): Z=1表示运算结果为零,Z=0表示运算结果不为零,对于CMP指令,Z=1表示进行比较的两个数大小相等。
C(bit29): 在加法指令中,当结果产生了进位,则C=1,表示无符号数运算发生上溢,其它情况下C=0。在减法指令中,当运算中发生借位,则C=0,表示无符号数运算发生下溢,其它情况下C=1。对于包含移位操作的非加/减法运算指令,C中包含最后一次溢出的位的数值,对于其它非加/减运算指令,C位的值通常不受影响。
V(bit28): 对于加/减法运算指令,当操作数和运算结果表示为二进制的补码表示的带符号数时,V=1表示符号位溢出,通常其他位不影响V位。
Q(bit27): 仅ARM v5TE_J架构支持,表示饱和状态,Q=1表示累积饱和,Q=0表示累积不饱和。
**IT[1:0](bit26:25)**: 和IT[7:2](bit15:bit10)一起组成IT[7:0],作为IF-THEN指令执行状态。
J(bit24): 仅ARM_v5TE-J架构支持,J=1表示处于Jazelle状态,此位通常和T(bit5)位一起表示当前所使用的指令集,如表所示:
| J | T | 描述 |
|---|---|---|
| 0 | 0 | ARM |
| 0 | 1 | Thumb |
| 1 | 1 | ThumbEE |
| 1 | 0 | Jazelle |
GE[3:0](bit19:16): SIMD指令有效,大于或等于。
IT[7:2](bit15:10): 参考IT[1:0]。
E(bit9): 大小端控制位,E=1表示大端模式,E=0表示小端模式。
**A(bit8)**: 禁止异步中断位,A=1表示禁止异步中断。
I(bit7): I=1禁止IRQ,I=0使能IRQ。
F(bit6): F=1禁止FIQ,F=0使能FIQ。
T(bit5): 控制指令执行状态,表明本指令是ARM指令还是Thumb指令,通常和J(bit24)一起表明指令类型,参考J(bit24)位。
**M[4:0]**: 处理器模式控制位,含义如表所示:
| M[4:0] | 处理器模式 |
|---|---|
| 10000 | User模式 |
| 10001 | FIQ模式 |
| 10010 | IRQ模式 |
| 10011 | Supervisor(SVC)模式 |
| 10110 | Monitor(MON)模式 |
| 10111 | Abort(ABT)模式 |
| 11010 | Hyp(HYP)模式 |
| 11011 | Undef(UND)模式 |
| 11111 | System(SYS)模式 |
ARM汇编基础
我们在进行嵌入式Linux开发的时候是绝对要掌握基本的ARM汇编,因为Cortex-A芯片一上电SP指针还没初始化,C环境还没准备好,所以肯定不能运行C代码,必须先用汇编语言设置好C环境,比如初始化DDR、设置SP指针等等,当汇编把C环境设置好了以后才可以运行C代码。所以Cortex-A一开始肯定是汇编代码,其实STM32也一样的,一开始也是汇编,以STM32F103为例,启动文件startup_stm32f10x_hd.s就是汇编文件,只是这个文件ST已经写好了,我们根本不用去修改,所以大部分学习者都没有深入的去研究。汇编的知识很庞大,本章我们只讲解最常用的一些指令,满足我们后续学习即可。
GNU汇编语法
我们要编写的是ARM汇编,编译使用的GCC交叉编译器,所以我们的汇编代码要符合GNU语法。
GNU汇编语法适用于所有的架构,并不是ARM独享的,GNU汇编由一系列的语句组成,每行一条语句,每条语句有三个可选部分,如下:
1 | |
- label 即标号,表示地址位置,有些指令前面可能会有标号,这样就可以通过这个标号得到指令的地址,标号也可以用来表示数据地址。注意label后面的“:”,任何以“:”结尾的标识符都会被识别为一个标号。
- instruction 即指令,也就是汇编指令或伪指令。@符号,表示后面的是注释,就跟C语言里面的“/*”和“*/”一样,其实在GNU汇编文件中我们也可以使用“/*”和“*/”来注释。
- comment 就是注释内容。
代码举例:
1 | |
上面代码中“add:”就是标号,“MOVS R0, #0X12” 就是指令,最后的 “@设置R0=0X12” 就是注释。
label 可以理解为函数名,可以通过该标号找到后面的程序,是系统直接跳转过来
注意!ARM中的指令、伪指令、伪操作、寄存器名等可以全部使用大写,也可以全部使用小写,但是不能大小写混用。
用户可以使用 .section 伪操作来定义一个段,汇编系统预定义了一些段名:
- .text 表示代码段。
- .data 初始化的数据段。
- .bss 未初始化的数据段。
- .rodata 只读数据段。
我们当然可以自己使用.section来定义一个段,每个段以段名开始,以下一段名或者文件结尾结束,比如:
1 | |
汇编程序的默认入口标号是 _start,不过我们也可以在链接脚本中使用 ENTRY 来指明其它的入口点,下面的代码就是使用 _start 作为入口标号:
1 | |
上面代码中 .global 是伪操作(和上面的都属于伪操作,这里时定义变量,上面的是定义段),表示_start是一个全局标号,类似C语言里面的全局变量一样,常见的伪操作有:
- .byte 定义单字节数据 ,比如.byte 0x12。
- .short 定义双字节数据,比如.short0x1234。
- .long 定义一个4字节数据,比如.long 0x12345678。
- .equ 赋值语句,格式为:.equ 变量名,表达式,比如.equ num, 0x12,表示num=0x12。
- .align 数据字节对齐,比如:.align 4表示4字节对齐。
- .end 表示源文件结束。
- .global 定义一个全局符号,格式为:.global symbol,比如:.global_start。
GNU汇编同样也支持函数,函数格式如下:
1 | |
GNU汇编函数返回语句不是必须的,如下代码就是用汇编写的Cortex-A7中断服务函数:
1 | |
上述代码中定义了三个汇编函数:Undefined_Handler、SVC_Handler和PrefAbort_Handler。
以函数Undefined_Handler为例我们来看一下汇编函数组成,“Undefined_Handler”就是函数名,“ldr r0, =Undefined_Handler”是函数体,“bx r0”是函数返回语句,“bx”指令是返回指令,函数返回语句不是必须的。
Cortex-A7常用汇编指令
处理器内部数据传输指令
使用处理器做的最多事情就是在处理器内部来回的传递数据,常见的操作有:
- 将数据从一个寄存器传递到另外一个寄存器。
- 将数据从一个寄存器传递到特殊寄存器,如CPSR和SPSR寄存器。
- 将立即数传递到寄存器。
数据传输常用的指令有三个:MOV、MRS和MSR,这三个指令的用法如表所示:
这三条指令只能在寄存器之间移动数据
| 指令 | 目的 | 源 | 描述 |
|---|---|---|---|
| MOV | Rx | Ry | Ry数据复制到Rx |
| MRS | Rx | xPSR | 特殊寄存器xPSR数据复制到Rx |
| MSR | xPSR | Rx | Rx数据复制到特殊寄存器xPSR |
MOV指令
MOV指令用于将数据从一个寄存器拷贝到另外一个寄存器,或者将一个立即数传递到寄存器里面,使用示例如下:
1 | |
MRS指令
MRS指令用于将特殊寄存器(如CPSR和SPSR)中的数据传递给通用寄存器,要读取特殊寄存器的数据只能使用MRS指令!使用示例如下:
1 | |
MSR指令
MSR指令和MRS刚好相反,MSR指令用来将普通寄存器的数据传递给特殊寄存器,也就是写特殊寄存器,写特殊寄存器只能使用MSR,使用示例如下:
1 | |
存储器访问指令
上述的 MOV、MRS、MSR 是无法直接访问 ARM存储器的,比如 RAM (运存)中的数据,I.MX6UL中的存储器(数据地址)就是 RAM 类型的,我们用汇编来配置 I.MX6UL 的时候需要借助存储器访问指令。一般先将要配置的值写入到Rx(x=0~12)寄存器中,然后借助存储器访问指令将Rx中的数据写入到I.MX6UL存储器中。读取I.MX6UL存储器也是一样的,只是过程相反。常用的存储器访问指令有两种:LDR和STR,用法如表所示:
所有运算处理都是发生通用寄存器(一般是R0~R14)的之中。所有存储器空间(如C语言变量的本质就是一个存储器空间上的几个BYTE)的值的处理,都是要传送到通用寄存器来完成。因此代码中大量需要LDR,STR指令来传送值
| 指令 | 描述 |
|---|---|
| LDR Rd, [Rn , #offset] | 从存储器Rn+offset的位置读取数据存放到Rd中。 |
| STR Rd, [Rn, #offset] | 将Rd中的数据写入到存储器中的Rn+offset位置。 |
1、LDR指令
L表示LOAD,LOAD的含义应该理解为:Load from memory into register。
LDR主要用于从存储加载数据到寄存器Rx中,LDR也可以将一个立即数加载到寄存器Rx中,LDR加载立即数的时候要使用“=”,而不是“#”。
在嵌入式开发中,LDR最常用的就是读取CPU的寄存器值,比如I.MX6UL有个寄存器GPIO1_GDIR,其地址为0X0209C004,我们现在要读取这个寄存器中的数据,示例代码如下:
1 | |
上述代码就是读取寄存器GPIO1_GDIR中的值,读取到的寄存器值保存在R1寄存器中,上面代码中offset是0,也就是没有用到offset。
2、STR指令
S表示STORE,STORE的含义应该理解为:Store from a register into memory。
LDR是从存储器读取数据,STR就是将数据写入到存储器中,同样以I.MX6UL寄存器GPIO1_GDIR为例,现在我们要配置寄存器GPIO1_GDIR的值为0X2000002,示例代码如下:示例代码7.2.2.2
1 | |
LDR和STR都是按照字进行读取和写入的,也就是操作的32位数据,如果要按照字节、半字进行操作的话可以在指令“LDR”后面加上B或H,比如按字节操作的指令就是LDRB和STRB,按半字操作的指令就是LDRH和STRH。
压栈和出栈指令
我们通常会在A函数中调用B函数,当B函数执行完以后再回到A函数继续执行。要想在跳回A函数以后代码能够接着正常运行,那就必须在跳到B函数之前将当前处理器状态保存起来(就是保存R0R15这些寄存器值),当B函数执行完成以后再用前面保存的寄存器值恢复R0R15即可。
保存R0-R15寄存器的操作就叫做现场保护,恢复R0~R15寄存器的操作就叫做恢复现场。在进行现场保护的时候需要进行压栈(入栈)操作,恢复现场就要进行出栈操作。压栈的指令为PUSH,出栈的指令为POP,PUSH和POP是一种多存储和多加载指令,即可以一次操作多个寄存器数据,他们利用当前的栈指针SP来生成地址,PUSH和POP的用法如表所示:
| 指令 | 描述 |
|---|---|
| PUSH <reglist> | 将寄存器列表存入栈中 |
| POP <reg list> | 从栈中恢复寄存器列表 |
假如我们现在要将R0~R3和R12这5个寄存器压栈,当前的SP指针指向0X80000000,处理器的堆栈是向下增长的,使用的汇编代码如下:
1 | |
压栈完成以后的堆栈如图所示: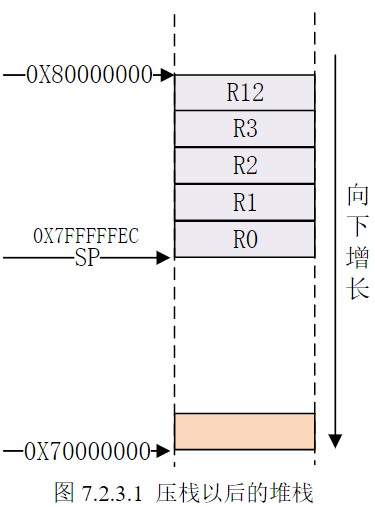
图7.2.3.1就是对R0~R3,R12进行压栈以后的堆栈示意图,此时的SP指向了0X7FFFFFEC,假如我们现在要再将LR进行压栈,汇编代码如下:
1 | |
对LR进行压栈完成以后的堆栈模型如图7.2.3.2所示: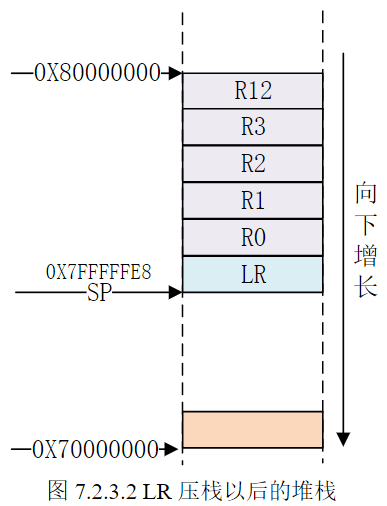
图7.2.3.2就是分两步对R0~R3,R2和LR进行压栈以后的堆栈模型,如果我们要出栈的话就是使用如下代码:
1 | |
出栈的就是从栈顶,也就是SP当前执行的位置开始,地址依次减小来提取堆栈中的数据到要恢复的寄存器列表中(先入后出)。PUSH和POP的另外一种写法是“STMFD SP!”和“LDMFD SP!”,因此上面的汇编代码可以改为:
1 | |
STMFD可以分为两部分:STM和FD,同理,LDMFD也可以分为LDM和FD。看到STM和LDM有没有觉得似曾相识,前面我们讲了LDR和STR,这两个是数据加载和存储指令,但是每次只能读写存储器中的一个数据。STM和LDM就是多存储和多加载,可以连续的读写存储器中的多个连续数据。
FD是FullDescending的缩写,即满递减的意思。根据ATPCS规则,ARM使用的FD类型的堆栈,SP指向最后一个入栈的数值,堆栈是由高地址向下增长的,也就是前面说的向下增长的堆栈,因此最常用的指令就是STMFD和LDMFD。STM和LDM的指令寄存器列表中编号小的对应低地址,编号高的对应高地址。
LDMFD SP!,{R0~R3,R12}:把sp指向的3个连续地址段(应该是3*4=12字节)中数据拷贝到 r0,r1,r2 这3个寄存器中去了(因为 r0,r1,r2 都是32位,所以数据要分别存储 )。
跳转指令
有多种跳转操作,比如:
- 直接使用跳转指令B、BL、BX等。
- 直接向PC寄存器里面写入数据。
上述两种方法都可以完成跳转操作,但是一般常用的还是B、BL或BX,用法如表
| 指令 | 描述 |
|---|---|
| B<label> | 跳转到label,如果跳转范围超过了+/-2KB,可以使用32位版本的跳转指令 B.W \<label>,这样可以得到较大范围的跳转 |
| BX<Rm> | 间接跳转,跳转到存放于Rm中的地址处,并且切换指令集 |
| BL <label> | 跳转到标号地址,并将返回地址保存在LR中 |
| BLX<Rm> | 结合BX和BL的特点,跳转到Rm指定的地址,并将返回地址保存在LR中,切换指令集 |
1、B指令
有去无回。这是最简单的跳转指令,B指令会将PC寄存器的值设置为跳转目标地址,一旦执行B指令,ARM处理器就会立即跳转到指定的目标地址。如果要调用的函数不会再返回到原来的执行处,那就可以用B指令,如下示例:
1 | |
上述代码只是初始化了SP指针,有些处理器还需要做其他的初始化,比如初始化DDR等等。因为跳转到C文件以后再也不会回到汇编了,所以在第4行使用了B指令来完成跳转。
2、BL指令
BL指令相比B指令,在跳转之前会在寄存器LR(R14)中保存当前PC寄存器值,所以可以通过将LR寄存器中的值重新加载到PC中来继续从跳转之前的代码处运行,这是子程序调用的一个基本但常用的手段。常用在中断处理中。示例代码如下:
1 | |
上述代码中第5行就是执行C语言版的中断处理函数,当处理完成以后是需要返回来继续执行下面的程序,所以使用了BL指令。
算术运算指令
汇编中也可以进行算术运算,比如加减乘除,常用的运算指令用法如表所示: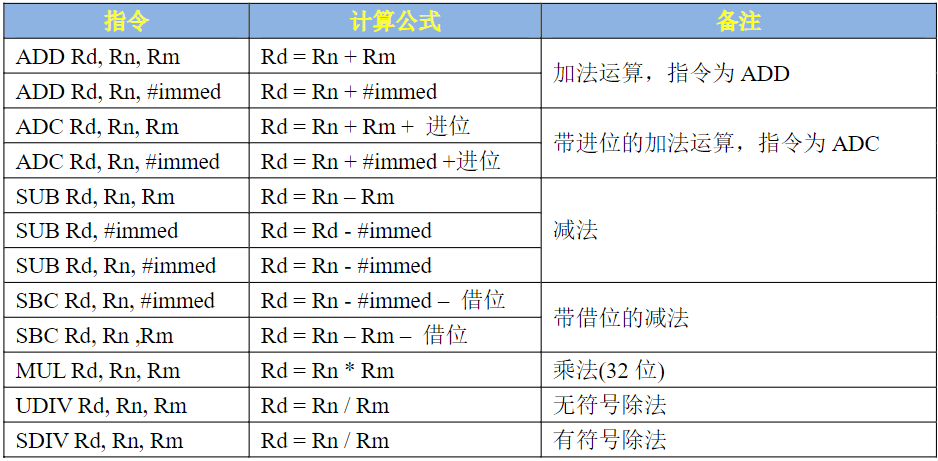
在嵌入式开发中最常会用的就是加减指令,乘除基本用不到。
逻辑运算指令
我们用C语言进行CPU寄存器配置的时候常常需要用到逻辑运算符号,比如“&”、“|”等逻辑运算符。使用汇编语言的时候也可以使用逻辑运算指令,常用的运算指令用法如表所示: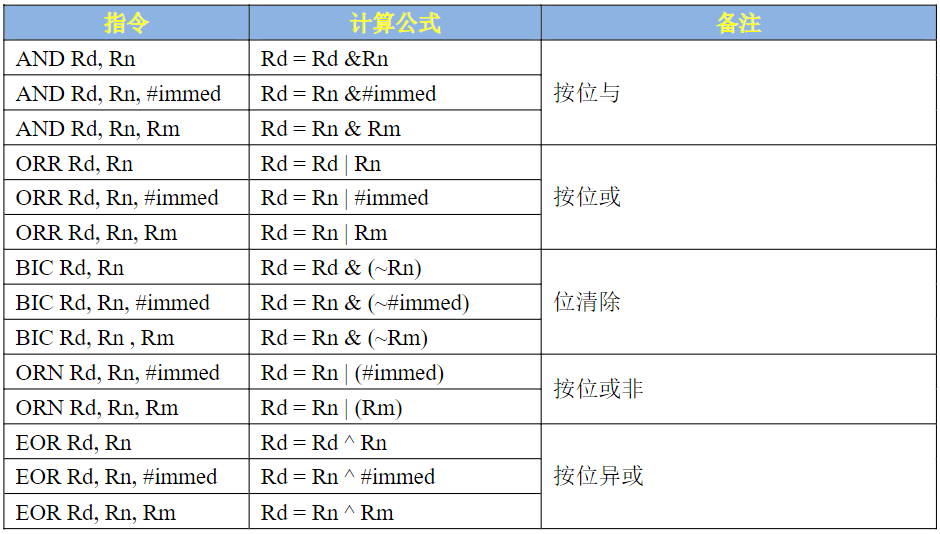
逻辑运算指令都很好理解,后面时候汇编配置I.MX6UL的外设寄存器的时候可能会用到,ARM汇编就讲解到这里,
本节主要讲解了一些最常用的指令。要想详细的学习ARM的所有指令请参考
参考文档
- ARM® Cortex™-A Series Programmer’s Guide Version: 4.0
- ARM ArchitectureReference Manual ARMv7-A and ARMv7-R edition.pdf
汇编LED灯实验
I.MX6U GPIO详解
STM32的GPIO初始化步骤:
- 使能指定GPIO的时钟。
- 初始化GPIO,比如输出功能、上拉、速度等等。
- STM32有的IO可以作为其它外设引脚,也就是IO复用,如果要将IO作为其它外设引脚使用的话就需要设置IO的复用功能。
- 最后设置GPIO输出高电平或者低电平。
要将I.MX6U的IO作为GPIO使用,我们需要一下几步:
- 使能GPIO对应的时钟。
- 设置寄存器IOMUXC_SW_MUX_CTL_PAD_XX_XX,设置IO的复用功能,使其复用为GPIO功能。
- 设置寄存器IOMUXC_SW_PAD_CTL_PAD_XX_XX,设置IO的上下拉、速度等等。
- 配置GPIO,设置输入/输出、是否使用中断、默认输出电平等。
I.MX6U IO命名
打开I.MX6UL参考手册的第30章“Chapter32: IOMUX Controller(IOMUXC)”
根据 IO 功能命名,GPIO只有GPIO1_IO00~GPIO_IO09,其他为复用IO。
I.MX6U 的 GPIO 一共有 5 组:GPIO1、GPIO2、GPIO3、GPIO4 和 GPIO5,其中 GPIO1 有 32 个 IO,GPIO2 有 22 个 IO,GPIO3 有 29 个 IO、GPIO4 有 29 个 IO,GPIO5最少,只有 12 个 IO,这样一共有 124 个 GPIO。
I.MX6U IO复用
看每个IO能复用什么外设的话可以直接查阅《IMX6UL参考手册》的第4章“Chapter4ExternalSignalsandPinMultiplexing”。
如果我们要编写代码,设置某个IO的复用功能的话就需要查阅第30章“Chapter32: IOMUX Controller(IOMUXC)”。
I.MX6U IO配置
前面说过,配置 IO 需要两种寄存器。
- SW_MUX_CTL_PAD_*负责设置管脚使用什么复用功能,
- SW_PAD_CTL_PAD_*用来设置管脚的属性,比如在输出时什么属性,输入时什么属性。
GPIO功能图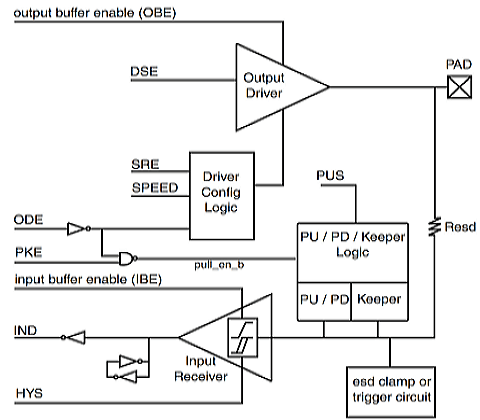
我们对照着图来详细看一下寄存器各个位的含义:
- HYS(bit16):对应图中HYS,用来使能迟滞比较器,当IO作为输入功能的时候有效,用于设置输入接收器的施密特触发器是否使能。如果需要对输入波形进行整形的话可以使能此位。此位为0的时候禁止迟滞比较器,为1的时候使能迟滞比较器。
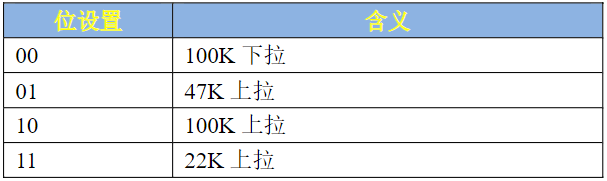
- PUS(bit15:14):对应图中的PUS,用来设置上下拉电阻的,一共有四种选项可以选择,如表所示
- PUE(bit13):图中没有给出来,当IO作为输入的时候,这个位用来设置IO使用上下拉还是状态保持器。当为0的时候使用状态保持器,当为1的时候使用上下拉。状态保持器在IO作为输入的时候才有用,顾名思义,就是当外部电路断电以后此IO口可以保持住以前的状态。
- PKE(bit12):对应图中的PKE,此为用来使能或者禁止上下拉/状态保持器功能,为0时禁止上下拉/状态保持器,为1时使能上下拉和状态保持器。
- ODE(bit11):对应图中的ODE,当IO作为输出的时候,此位用来禁止或者使能开路输出,此位为0的时候禁止开路输出,当此位为1的时候就使能开路输出功能。
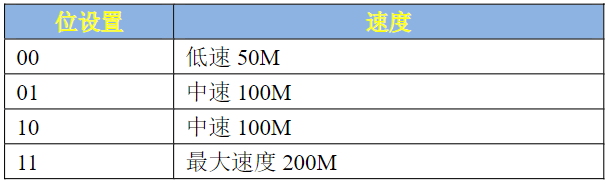
- SPEED(bit7:6):对应图中的SPEED,当IO用作输出的时候,此位用来设置IO速度,设置如表所示:
- DSE(bit5:3):对应图中的DSE,当IO用作输出的时候用来设置IO的驱动能力,总共有8个可选选项,如表所示:

- SRE(bit0):对应图中的SRE,设置压摆率,当此位为0的时候是低压摆率,当为1的时候是高压摆率。这里的压摆率就是IO电平跳变所需要的时间,比如从0到1需要多少时间,时间越小波形就越陡,说明压摆率越高;反之,时间越多波形就越缓,压摆率就越低。如果你的产品要过EMC的话那就可以使用小的压摆率,因为波形缓和,如果你当前所使用的IO做高速通信的话就可以使用高压摆率。
I.MX6U GPIO配置
IOMUXC_SW_MUX_CTL_PAD_XX_XX和IOMUXC_SW_PAD_CTL_PAD_XX_XX这两种寄存器都是配置IO的,注意是IO!不是GPIO,GPIO是一个IO众多复用功能中的一种。
关于I.MX6U的GPIO请参考《IMX6UL参考手册》的第28章“Chapter 28 General Purpose Input/Ouput(GPIO)”,GPIO结构如图所示: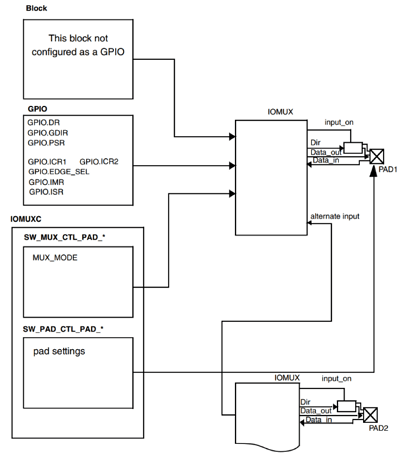
左下角 的IOMUXC框图里SW_MUX_CTL_PAD_*和SW_PAD_CTL_PAD_*两种寄存器,用来设置IO的复用功能和IO属性配置。左上角部分的GPIO框图就是当IO用作GPIO的时候需要设置的寄存器,一共有八个:DR、GDIR、PSR、ICR1、ICR2、EDGE_SEL、IMR和ISR。
DR数据寄存器
- 此寄存器是32位的,每个位都对应一个GPIO。
- 当GPIO被配置为输出功能以后,此寄存器设置相应的IO输出高低电平
- 当GPIO被配置为输入模式以后,此寄存器就保存着对应IO的电平值。
DR方向寄存器
- GDIR寄存器也是32位的,同样的,每个IO对应一个位,
- 此寄存器用来设置某个IO的工作方向,是输入还是输出。
- 输入为0,输出为1。
PSR状态寄存器
- 同样的PSR寄存器也是一个GPIO对应一个位,
- 读取相应的位即可获取对应的GPIO的状态,也就是GPIO的高低电平值。
- 功能和输入状态下的DR寄存器一样。
ICR1和ICR2中断控制寄存器
- ICR1用于IO0~15的配置,ICR2用于IO16~31的配置。
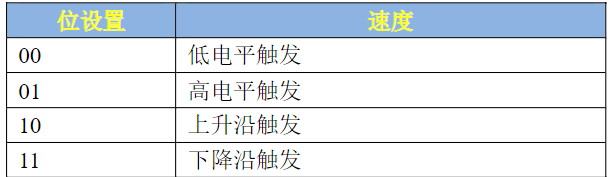
- ICR寄存器中一个GPIO用两个位,这两个位用来配置中断的触发方式,如表所示:
IMR中断屏蔽寄存器
- 一个GPIO对应一个位,
- 控制GPIO的中断禁止和使能,使能设为1;禁止中断,就设为0。
ISR中断状态寄存器
- 一个GPIO对应一个位
- 只要某个GPIO的中断发生,那么ISR中相应的位就会被置1。
- 处理完中断以后,必须清除中断标志位,清除方法就是向ISR中相应的位写1,也就是写1清零。
EDGE_SEL边沿选择寄存器
- E设置边沿中断,这个寄存器会覆盖ICR1和ICR2的设置,同样是一个GPIO对应一个位。
- 如果相应的位被置1,那么就相当与设置了对应的GPIO是上升沿和下降沿(双边沿)触发
I.MX6U GPIO时钟使能
I.MX6UL 参考手册的第 18 章“Chapter 18: Clock Controller Module(CCM)”
我们只看一下CCM里面的外设时钟使能寄存器。CMM 有 CCM_CCGR0~CCM_CCGR6 这 7 个寄存器,这 7 个寄存器控制着 I.MX6U 的所有外设时钟开关
以CCM_CCGR0为例:
- CCM_CCGR0 是个 32 位寄存器,其中每 2 位控制一个外设的时钟,比如 bit31:30 控制着-GPIO2 的外设时钟,两个位就有 4 种操作方式。

为了方便开发,本教程后面所有的例程将 I.MX6U 的所有外设时钟都打开了
硬件原理图
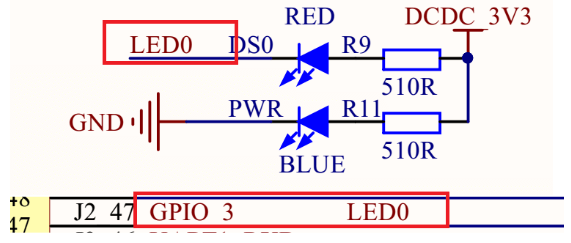
LED0接到了GPIO_3上,GPIO_3就是GPIO1_IO03
实验程序编写
所有的裸机实验我们都在Ubuntu下完成,使用VSCode编辑器!
在 linux/driver/board_driver 文件夹下新建本次的工程文件夹 1_led,并在这个目录下新建一个名为“led.s”的汇编文件和一个名为“.vscode”的目录,创建好以后“1_led” 如下所示
1 | |
.vscode文件夹里面存放VSCode的工程文件,led.s就是我们新建的汇编文件,我们稍后会在led.s这个文件中编写汇编程序。使用VSCode打开1_leds这个文件夹,在led.s中输入如下代码:
1 | |
编译下载验证
创建Makefile文件
1 | |
输入如下内容:
1 | |
编写执行 make 完成编译
运行地址 <--->链接地址:他们两个是等价的,只是两种不同的说法。
加载地址 <--->存储地址:他们两个是等价的,也是两种不同的说法。
运行地址:程序在SRAM、SDRAM中执行时的地址。就是执行这条指令时,PC应该等于这个地址,换句话说,PC等于这个地址时,这条指令应该保存在这个地址内。
加载地址:程序保存在Nand flash中的地址。
位置无关码:B、BL、MOV都是位置位置无关码。
位置有关码:LDR PC,=LABEL等类似的代码都是位置有关码。
代码烧写
将正点原子的软件“imxdownload”,拷贝到工程根目录下,也就是和led.bin处于同一个文件夹下
1 | |
给该软件赋予执行权限
1 | |
使用imxdownload向SD卡烧写led.bin文件,命令格式如下:
1 | |
实例:
1 | |
最后会生成一个 load.imx 文件。这个文件就是软件imxdownload根据NXP官方启动方式介绍的内容,在led.bin文件前面添加了一些数据头以后生成的。最终烧写到SD卡里面的就是这个load.imx文件,而非led.bin。
烧写速度是201KB/s。注意这个烧写速度,如果这个烧写速度在几百KB/s以下那么就是正常烧写。如果这个烧写速度大于几十MB/s、甚至几百MB/s那么肯定是烧写失败了!
解决方法就是重新插拔SD卡,但一般出现这种情况,重新插拔SD卡基本没啥用,只有重启Ubuntu,原因不清楚。
最后设置拨码开关为SD卡启动。设置好以后按一下开发板的复位键,如果代码运行正常的话LED0就会被点亮。为了验证,可以把SD卡拔了再重启,会发现led是熄灭的。说明sd卡起作用了,即程序执行了。
I.MX6U启动方式详解
STM32 也有 boot 选择,一般我们的程序是直接下载到内部flash的,然后stm32从flash中读取程序运行。
而I.MX6U是没有flash的,它需要外挂存储器,开发版挂载的就是 DDR3 外部存储器,代码最终会存储到其中,然后运行。
DDR 是掉电不保存的,我们的基本都是通过sd拷贝到DDR中运行的
NAND 是掉电保存的
启动方式选择
| BOOT_MODE[1:0] | BOOT类型 |
|---|---|
| 00 | 从FUSE启动 |
| 01 | 串行下载 |
| 10 | 内部BOOT模式 |
| 11 | 保留 |
我们一般用到的只有第二和第三种BOOT方式。
串行下载
串行下载的意思就是可以通过USB或者UART将代码下载到板子上的外置存储设备中,我们可以使用OTG1这个USB口向开发板上的SD/EMMC、NAND等存储设备下载代码。这个下载是需要用到NXP提供的一个软件,一般用来最终量产的时候将代码烧写到外置存储设备中的,我们后面讲解如何使用。
内部BOOT模式
在此模式下,芯片会执行内部的bootROM代码,这段boot ROM代码会进行硬件初始化(一部分外设),然后从boot设备(就是存放代码的设备、比如SD/EMMC、NAND)中将代码拷贝出来复制到指定的RAM中,一般是DDR。
然后我们还需要指定从什么样的 boot 复制代码。通过开发版上的拨码开关选择,具体原理这里不复制赘述。
实际开始时是不需要拨码开关设置的,我们一般都是硬件电路设计直接默认选择一种启动方式(NAND),省去硬件设计
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 启动设备 |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | x | x | x | x | x | x | 串行下载,可以通过USB烧写镜像文件。 |
| 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | SD卡启动。 |
| 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | EMMC启动。 |
| 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | NAND FLASH启动 |
SD卡启动实际是执行SD卡中存放的 bootROM 代码初始化设备,然后运行从SD卡复制到DDR中的实际程序代码。也就是我们最终运行的程序时存放在DDR中的,SD卡只负责初始化配置和暂时存放代码(代码 = bootROM + 运行代码 )
总结一下,我们编译出来的.bin文件不能直接烧写到SD卡中,需要在.bin文件前面加上IVT、BootData和DCD这三个数据块( bootROM)。这三个数据块是有指定格式的,我们必须按照格式填写,然后将其放到.bin文件前面,最终合成的才是可以直接烧写到SD卡中的文件。
C语言版LED灯
我们有两部分文件要做:
- 汇编文件:汇编文件只是用来完成C语言环境搭建。(初始化DDR、设置堆栈指针SP等等)
- C语言文件:C语言文件就是完成我们的业务层代码的,其实就是我们实际例程要完成的功能。
以STM32F103为例,其启动文件startup_stm32f10x_hd.s这个汇编文件就是完成C语言环境搭建的,当然还有一些其他的处理,比如中断向量表等等。当startup_stm32f10x_hd.s把C语言环境初始化完成以后就会进入C语言环境。
实验程序编写
新建VScode工程,工程名字为“ledc”,新建三个文件:start.S、main.c和main.h。其中start.S是汇编文件,main.c和main.h是C语言相关文件。
在前面创建的start.s中输入如下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13 .global _start
_start:
/* 进入 SVC 模式 */
MRS R0, CPSR
BIC R0, R0, #0x1f /* 将R0 的低五位清零,也就是 cpsr 的 M0-4 */
ORR R0, R0, #0x13 /* 或0x13 使用 SVC 模式 */
MSR CPSR, R0 /* 将R0 写入到 cpsr 中 */
LDR SP, =0x80200000 /* 设置栈指针 */
B main /* 跳转到main函数 */
这里我们设置处理器运行在SVC模式下。处理器模式的设置是通过修改CPSR(程序状态)寄存器来中M4:0设置处理器运行模式的。如果要将处理器设置为SVC模式,那么M[4:0]就要等于0X13。 这里先使用MRS读取寄存器值经过修改再再使用指令MSR将修改后的R0重新写入到CPSR中。
为什么是 SVC 模式
先简单的来分析一下那7种模式:
中止abt和未定义und模式
首先可以排除的是,中止abt和未定义und模式,那都是不太正常的模式,此处程序是正常运行的,所以不应该设置CPU为其中任何一种模式,所以可以排除。快中断fiq和中断irq模式
其次,对于快中断fiq和中断irq来说,此处uboot初始化的时候,也还没啥中断要处理和能够处理,而且即使是注册了终端服务程序后,能够处理中断,那么这两种模式,也是自动切换过去的,所以,此处也不应该设置为其中任何一种模式。用户usr模式
虽然从理论上来说,可以设置CPU为用户usr模式,但是由于此模式无法直接访问很多的硬件资源,而uboot初始化,就必须要去访问这类资源,所以此处可以排除,不能设置为用户usr模式。系统sys模式 vs 管理svc模式
首先,sys模式和usr模式相比,所用的寄存器组,都是一样的,但是增加了一些访问一些在usr模式下不能访问的资源。而svc模式本身就属于特权模式,本身就可以访问那些受控资源,而且,比sys模式还多了些自己模式下的影子寄存器,所以,相对sys模式来说,可以访问资源的能力相同,但是拥有更多的硬件资源。
所以,从理论上来说,虽然可以设置为sys和svc模式的任一种,但是从uboot方面考虑,其要做的事情是初始化系统相关硬件资源,需要获取尽量多的权限,以方便操作硬件,初始化硬件。
从uboot的目的是初始化硬件的角度来说,设置为svc模式,更有利于其工作。
因此,此处将CPU设置为SVC模式。另外这里设置为 sys 模式,也是可以正常运行的。但不保证后面的例程也可以。
SP指针=0X80200000,因为I.MX6U-ALPHA开发板 上 的DDR3地址范围 是0X800000000XA0000000(512MB)或者0X800000000X90000000(256MB),不管是512MB版本还是256MB版本的,其DDR3起始地址都是0X80000000。由于Cortex-A7的堆栈是向下增长的,所以将SP指针设置为0X80200000,因此SVC模式的栈大小0X80200000-0X80000000=0X200000=2MB,2MB的栈空间已经很大了,如果做裸机开发的话绰绰有余。
这里需要将 start.S 和 后面的main.c 看成同一个文件,main 其实就是指代用C写称的main函数,这里.c文件再编译时会转为main函数,并且我们通过 Makefile 使得 start.S 文件在 main.c 文件之前,并合并成一个
.o文件,这样在.o文件中 srat.S 中的内容排在 main.c 内容前面,则系统会先运行 start.S 的内容,然后通过B main跳转到main函数,继续执行。
在main.h里面输入代码:
1 | |
在main.c里面输入如下所示代码
1 | |
编译下载验证
1 | |
上述的MakefileMakefile要复杂一点了,里面用到了Makefile变量和自动变量。
第1行定义了一个变量objs,objs包含着要生成ledc.bin所需的材料:start.o和main.o,这里要注意start.o一定要放到最前面!因为在后面链接的时候start.o要在最前面,因为start.o是最先要执行的文件!
第3行就是默认目标,目的是生成最终的可执行文件ledc.bin,ledc.bin依赖start.o和main.o如果当前工程没有start.o和main.o的时候就会找到相应的规则去生成start.o和main.o。比如start.o是start.s文件编译生成的,因此会执行第8行的规则。
第4行是使用arm-linux-gnueabihf-ld进行链接,链接起始地址是0X87800000,但是这一行用到了自动变量“$^”,“$^”的意思是所有依赖文件的集合,在这里就是objs这个变量的值:start.o和main.o。链接的时候start.o要链接到最前面,因为第一行代码就是start.o里面的,因此这一行就相当于:
1 | |
第5行使用arm-linux-gnueabihf-objcopy来将ledc.elf文件转为ledc.bin,本行也用到了自动变量“$@”,“$@”的意思是目标集合,在这里就是“ledc.bin”,那么本行就相当于:
1 | |
第6行使用arm-linux-gnueabihf-objdump来反汇编,生成ledc.dis文件。
第8~15行就是针对不同的文件类型将其编译成对应的.o文件,其实就是汇编.s(.S)和.c文件,比如start.s就会使用第8行的规则来生成对应的start.o文件。
编译完成以后可以使用软件imxdownload将其下载到SD卡中,命令如下:
1 | |
链接脚本
在上面的Makefile中我们链接代码的时候使用如下语句:
1 | |
上面语句中我们是通过“-Ttext”来指定链接地址是0X87800000的,这样的话所有的文件都会链接到以0X87800000为起始地址的区域。但是有时候我们很多文件需要链接到指定的区域,或者叫做段里面,比如在Linux里面初始化函数就会放到init段里面。因此我们需要能够自定义一些段,这些段的起始地址我们可以自由指定,同样的我们也可以指定一个文件或者函数应该存放到哪个段里面去。要完成这个功能我们就需要使用到链接脚本,用于描述文件应该如何被链接在一起形成最终的可执行文件。
其主要目的是描述输入文件中的段如何被映射到输出文件中,并且控制输出文件中的内存排布。比如我们编译生成的文件一般都包含text段、data段等等。链接脚本的语法很简单,就是编写一系列的命令,这些命令组成了链接脚本,每个命令是一个带有参数的关键字或者一个对符号的赋值,可以使用分号分隔命令。像文件名之类的字符串可以直接键入,也可以使用通配符“*”。最简单的链接脚本可以只包含一个命令“SECTIONS”,我们可以在这一个“SECTIONS”里面来描述输出文件的内存布局。我们一般编译出来的代码都包含在text、data、bss和rodata这四个段内,假设现在的代码要被链接到0X10000000这个地址,数据要被链接到0X30000000这个地方,下面就是完成此功能的最简单的链接脚本:
1 | |
第1行我们先写了一个关键字“SECTIONS”,后面跟了一个大括号,这个大括号和第7行的大括号是一对,这是必须的。看起来就跟C语言里面的函数一样。
第2行对一个特殊符号“.”进行赋值,“.”在链接脚本里面叫做定位计数器,默认的定位计数器为0。我们要求代码链接到以0X10000000为起始地址的地方,因此这一行给“.”赋值0X10000000,表示以0X10000000开始,后面的文件或者段都会以0X10000000为起始地址开始链接。
第3行的“.text”是段名,后面的冒号是语法要求,冒号后面的大括号里面可以填上要链接到“.text”这个段里面的所有文件,“*(.text)”中的“*”是通配符,表示所有输入文件的.text段都放到“.text”中。
第4行,我们的要求是数据放到0X30000000开始的地方,所以我们需要重新设置定位计数器“.”,将其改为0X30000000。
第5行跟第3行一样,定义了一个名为“.data”的段,然后所有文件的“.data”段都放到这里面。ALIGN(4)表示4字节对齐。也就是说段“.data”的起始地址要能被4整除,一般常见的都是ALIGN(4)或者ALIGN(8),也就是4字节或者8字节对齐。
第6行定义了一个“.bss”段,所有文件中的“.bss”数据都会被放到这个里面,“.bss”数据就是那些定义了但是没有被初始化的变量。
我们接下来就按照这个基本的语法格式来编写我们本试验的链接脚本,我们本试验的链接脚本要求如下:
- 链接起始地址为0X87800000
- start.o要被链接到最开始的地方,因为start.o里面包含这第一个要执行的命令。
根据要求,在Makefile同目录下新建一个名为“imx6ul.lds”的文件,然后在此文件里面输入如下所示代码:
1 | |
第2行设置定位计数器为0X87800000。
第5行设置链接到开始位置的文件为start.o,因为start.o里面包含着第一个要执行的指令,所以一定要链接到最开始的地方。
第6行是main.o这个文件,其实可以不用写出来,因为main.o的位置就无所谓了,可以由编译器自行决定链接位置。
在第11、13行有“__bss_start”和“__bss_end”符号,对这两个符号进行赋值,其值为定位符“.”,这两个符号用来保存.bss段的起始地址和结束地址。前面说了.bss段是定义了但是没有被初始化的变量,我们需要手动对.bss段的变量清零的,因此我们需要知道.bss段的起始和结束地址,这样我们直接对这段内存赋0即可完成清零。通过第11、13行代码,.bss段的起始地址和结束地址就保存在了“__bss_start”和“__bss_end”中,我们就可以直接在汇编或者C文件里面使用这两个符号。
修改Makefile
将Makefile中的如下一行代码:
1 | |
改为:
1 | |
其实就是将-T后面的0X87800000改为imx6ul.lds,表示使用imx6ul.lds这个链接脚本文件。修改完成以后使用新的Makefile和链接脚本文件重新编译工程,编译成功以后就可以烧写到SD卡中验证了。
arm-linux-gcc/ld/objcopy/objdump参数总结
arm-linux-gcc -wall -O2 -c -o $@ $<
- -o 只激活预处理,编译,和汇编,也就是他只把程序做成obj文件
- -Wall 指定产生全部的警告信息
- -O2 编译器对程序提供的编译优化选项,在编译的时候使用该选项,可以使生成的执行文件的执行效率提高
- -c 表示只要求编译器进行编译,而不要进行链接,生成以源文件的文件名命名但把其后缀由 .c 或 .cc 变成 .o 的目标文件
- -S 只激活预处理和编译,就是指把文件编译成为汇编代码
arm-linux-ld
直接指定代码段,数据段,BSS段的起始地址
- -Ttest startaddr
- -Tdata startaddr
- -Tbss startaddr
示例:Arm-linux-ld –Ttext 0x0000000 –g led.o –o led_elf
使用连接脚本设置地址:Arm-linux-ld –Ttimer.lds –o timer_elf $^
其中timer.lds 为连接脚本,完整的连接脚本格式:
1 | |
arm-linux-objcopy
被用来复制一个目标文件的内容到另一个文件中,可用于不同源文件的之间的格式转换
示例:Arm-linux-objcopy –o binary –S elf_file bin_file
常用的选项:
- input-file , outflie
- 输入和输出文件,如果没有outfile,则输出文件名为输入文件名
- 2.-l bfdname或—input-target=bfdname
- 用来指明源文件的格式,bfdname是BFD库中描述的标准格式名,如果没指明,则arm-linux-objcopy自己分析
- 3.-O bfdname 输出的格式
- 4.-F bfdname 同时指明源文件,目的文件的格式
- 5.-R sectionname 从输出文件中删除掉所有名为sectionname的段
- 6.-S 不从源文件中复制重定位信息和符号信息到目标文件中
- 7.-g 不从源文件中复制调试符号到目标文件中
arm-linux-objdump
查看目标文件(.o文件)和库文件(.a文件)信息。
示例:arm-linux-objdump -D -m arm led_elf > led.dis
相关参数
- -D 显示文件中所有汇编信息
- -m machine
指定反汇编目标文件时使用的架构,当待反汇编文件本身没有描述架构信息的时候(比如S-records),这个选项很有用。可以用-i选项列出这里能够指定的架构.这里例子中指定反汇编得到的目标文件使用ARM架构。
- -b bfdname 指定目标码格式
- -disassemble或者-d 反汇编可执行段
- -dissassemble-all或者-D 反汇编所有段
- -EB,-EL指定字节序
- -file-headers或者-f 显示文件的整体头部摘要信息
- -section-headers,–headers或者-h 显示目标文件中各个段的头部摘要信息
- -info 或者-I 显示支持的目标文件格式和CPU架构
- -section=name或者-j name显示指定section 的信息
- -architecture=machine或者-m machine 指定反汇编目标文件时使用的架构
参考链接
Uboot中start.S源码的指令级的详尽解析
arm-linux-gcc/ld/objcopy/objdump参数总结
模仿STM32驱动开发格式实验
创建VSCode工程,工作区名字为“ledc_stm32”,新建三个文件:start.S、main.c和imx6ul.h。其中start.S是汇编文件,start.S文件的内容和第十章的start.S一样,直接复制过来就可以。main.c 和imx6ul.h是C文件。
1 | |
在编写寄存器组结构体的时候注意寄存器的地址是否连续,有些外设的寄存器地址可能不是连续的,会有一些保留地址,因此我们需要在结构体中留出这些保留的寄存器。
比如CCM的CCGR6寄存器地址为0X020C4080,而寄存器CMEOR的地址为0X020C4088。按照地址顺序递增的原理,寄存器CMEOR的地址应该是0X020C4084,但是实际上CMEOR的地址是0X020C4088,相当于中间跳过了0X020C4088-0X020C4080=8个字节,如果寄存器地址连续的话应该只差4个字节(32位),但是现在差了8个字节,所以需要在寄存器CCGR6和CMEOR直接加入一个保留寄存器,这个就是“示例代码”中第47行RESERVED_3[1]的来源。如果不添加保留为来占位的话就会导致寄存器地址错位!
main.c文件中输入如下所示内容:
1 | |
main.c中7个函数,这7个函数的含义和前面的main.c文件一样,只是函数体写法变了,寄存器的访问采用imx6ul.h中定义的外设指针。比如第27行设置GPIO1_IO03的复用功能就可以通过“IOMUX_SW_MUX->GPIO1_IO03”来给寄存SW_MUX_CTL_PAD_GPIO1_IO03赋值。
官方SDK移植实验
在上一章中,我们参考ST官方给STM32编写的stm32f10x.h来自行编写I.MX6U的寄存器定义文件。自己编写这些寄存器定义不仅费时费力,没有任何意义,而且很容易写错,幸好NXP官方为I.MX6ULL编写了SDK包,在SDK包里面NXP已经编写好了寄存器定义文件,所以我们可以直接移植SDK包里面的文件来用。虽然NXP是为I.MX6ULL编写的SDK包,但是I.MX6UL也是可以使用的!
I.MX6ULL官方SDK包简介
NXP针对I.MX6ULL编写了一个SDK包,这个SDK包就类似于STM32的STD库或者HAL库,这个SDK包提供了Windows和Linux两种版本,分别针对主机系统是Windows和Linux。因为我们是在Windows下来编写代码的,因此我们使用的是Windows版本的。Windows版本SDK里面的例程提供了IAR版本。
不是所有的半导体厂商都会为Cortex-A架构的芯片编写裸机SDK包,我使用过那么多的Cotex-A系列芯片,也就发现了NXP给I.MX6ULL编写了裸机SDK包。而且去NXP官网看一下,会发现只有I.MX6ULL这一款Cotex-A内核的芯片有裸机SDK包,NXP的其它Cotex-A芯片都没有。说明在NXP的定位里面,I.MX6ULL就是一个Cotex-A内核的高端单片机,定位类似ST的STM32H7。
使用Cortex-A内核芯片的时候不要想着有类似STM32库一样的东西,I.MX6ULL是一个特例,基本所有的Cortex-A内核的芯片都不会提供裸机SDK包。
I.MX6ULL的SDK包在NXP官网下载,下载界面如图所示
双击SDK_2.2_MCIM6ULL_RFP_Win.exe安装SDK包,安装的时候需要记住安装位置
我们重点是需要SDK包里面与寄存器定义相关的文件,一共需要如下三个文件:
- fsl_common.h:位置为SDK_2.2_MCIM6ULL\devices\MCIMX6Y2\drivers\fsl_common.h。
- fsl_iomuxc.h:位置为SDK_2.2_MCIM6ULL\devices\MCIMX6Y2\drivers\fsl_iomuxc.h。
- MCIMX6Y2.h:位置为SDK_2.2_MCIM6ULL\devices\MCIMX6Y2\MCIMX6YH2.h。
整个SDK包我们就需要上面这三个文件,把这三个文件准备好,我们后面移植要用。
实验程序编写
SDK文件移植
使用VSCode新建工程,将fsl_common.h、fsl_iomuxc.h和MCIMX6Y2.h这三个文件拷贝到工程中,这三个文件直接编译的话肯定会出错的!需要对其做删减,因为这三个文件里面的代码都比较大,所以就不详细列出这三个文件删减以后的内容了。直接使用原子删减好的文件。
cc.h 文件
新建一个名为cc.h的头文件,cc.h里面存放一些SDK库文件需要使用到的数据类型,在cc.h里面输入如下代码:
1 | |
在cc.h文件中我们定义了很多的数据类型,因为有些第三方库会用到这些变量类型。其实就是有些第三方库包括这个 SDK 使用的数据类型名大多时简写,需要重新定义一下。
编写实验代码
start.S 和上文一样,直接复制。
main.c 如下:
1 | |
这里仅在 led_init(void)中使用了两个 SDK 函数
- IOMUXC_SetPinMux
- IOMUXC_SetPinConfig
其 中 函 数IOMUXC_SetPinMux是 用 来 设 置IO复 用 功 能 的 , 最 终 肯 定 设 置 的 是 寄 存 器“IOMUXC_SW_MUX_CTL_PAD_XX”。
函数IOMUXC_SetPinConfig设置的是IO的上下拉、速度等的,也就是寄存器“IOMUXC_SW_PAD_CTL_PAD_XX”,所以上面两个函数其实就是上一章中的:
1 | |
其余部分则是使用的 SDK 内部寄存器定义,替代前面我们自己写的寄存器定义。
编译下载验证
Makefile文件内容如下:
1 | |
Makefile文件是在前面的Makefile上修改的,只是使用到了变量替代一些文本,更懒了。。。效果实际是一样的。链接脚本imx6ul.lds的内容和前面一样,直接使用。
BSP工程管理实验
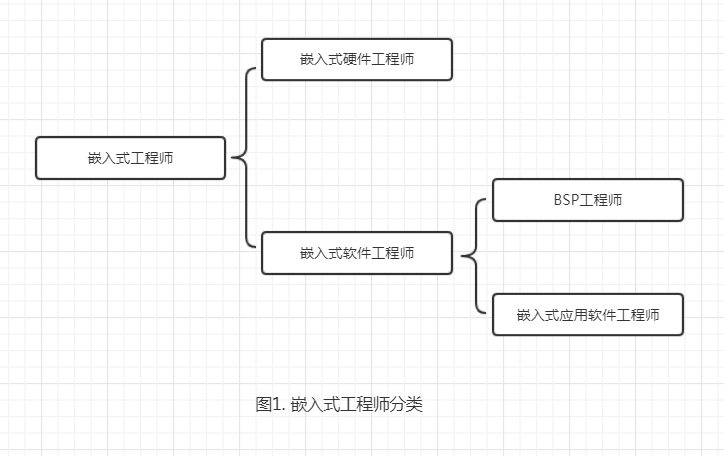
嵌入式硬件工程师主要职责是负责设计嵌入式系统的硬件原理图,使用相应的工具画出PCB图,后期配合嵌入式软件工程师调试系统。
嵌入式软件工程师从系统软件上又可以分为两种:
- BSP工程师
- 嵌入式应用软件工程师。
嵌入式应用软件工程师主要是负责编写基于嵌入式系统的应用软件。类似于基于windows上的QQ, word。
BSP工程师,顾名思义就是负责板级支持包的开发、调试和维护工作。那么什么是板级支持包呢?前面我们讲过,嵌入式硬件工程师负责设计硬件,画出PCB图,工厂会根据PCB图生产出对应的电路板。一个嵌入式系统光有电路板是不够的,还要有对应的软件支持,软件开发的前提是首先使板子正常稳定的工作,然后再在其上编写对应的应用软件以实现其特有的功能。其中使板子正常稳定的工作的代码就属于板级支持包。 那么BSP工程师的具体工作有哪些呢?
对于不跑操作系统的设备来讲,其功能相对简单一点,使用的主控芯片一般也比较简单,比如风靡一时的51系列单片机、stm系列的单片机。对于这些简单系统来讲,它对软件开发人员要求相对比较低,当然也就没有我前面所说的分工那么详细,有时候甚至从画板、点亮、开发都是由一个人来完成的。对于跑操作系统来讲的设备,就不一样了。一般来讲,跑操作系统的设备其软件开发分三个阶段:
点亮板子
第一批板子出厂时是不包含任何软件的。BSP工程师需要结合硬件原理图修改从芯片厂商拿到的参考代码,调试板子,使板子上的操作系统能够正常稳定工作,从而提供一个稳定的开发调试环境,这个过程叫做点亮板子,行话叫做Bringup。这属于BSP工程师最具有价值含量的工作之一,因为它对BSP工程师所掌握的知识的广度和深度都有一定要求。其中会涉及到计算机原理、操作系统,处理器架构等,还包括硬件方面的一些知识。综合起来其最核心的工作就是对内核的移植、裁剪。使能板子上所有设备
上个阶段中,板子的CPU和基本的器件已经能正常工作,这个阶段中将使能所有的外设,并为后面要开发的应用程序提供对应的软件控制接口。这个过程的实质是对应的操作系统下驱动开发的过程,需要掌握硬件工作的原理,操作系统的相关知识。为板子开发应用程序
如前文所述,嵌入式系统是一个具有专一功能的系统,其上所有的硬件,软件都应该为这一功能服务。第二个阶段结束的时候,板子上所有的设备都已经可以正常使用了。这个阶段的任务就是开发应用程序来实现某种特定的功能,应用程序中会使用第二阶段提供的软件接口控制板子上的设备来完成这一功能。
上述前两个阶段属于BSP开发的内容,第三个阶段属于嵌入式应用软件开发的过程。综上所述,BSP工程师主要应该具备的能力主要有:
- 掌握计算机原理方面的知识;
- 掌握操作系统的相关知识,深入研究某种操作系统,目前来讲,研究linux操作系统应该是大部分人的选择;
- 精湛的C语言功底和一定的C++/汇编的知识。
- 掌握一定的硬件和电路原理方面的知识;
- 熟悉常见的接口协议,如I2C, SPI, UART, USB等。
我的理解:BSP 其实就是底层驱动开发,写些程序能够控制芯片以及外设、并准备发操作系统运行环境,然后留出 API 接口供后面的软件开发人员使用。而软件开发人员是不需要关心底层硬件的。简单来世就是链接硬件和软件的桥梁。所以就需要既懂硬件(驱动开发)也懂软件(API接口)。
标题的 BSP 工程管理,其实就是将所有编写的底层驱动程序归类整理到一个文件夹,对程序分功能管理。不至于混乱。
新建名为“5_ledc_bsp”的文件夹,在里面新建bsp、imx6ul、obj和project这4个文件夹
- bsp用来存放驱动文件
- imx6ul用来存放跟芯片有关的文件,比如NXP官方的SDK库文件;
- obj用来存放编译生成的.o文件;
- project存放start.S和main.c文件,也就是应用文件;
将cc.h、fsl_common.h、fsl_iomuxc.h和MCIMX6Y2.h这四个文件拷贝到文件夹imx6ul中;
将start.S和main.c这两个文件拷贝到文件夹project中。
我们前面的实验中所有的驱动相关的函数都写到了main.c文件中,比如函数clk_enable、led_init和delay,这三个函数可以分为三类:
- 时钟驱动、
- LED驱动
- 延时驱动。
因此我们可以在bsp文件夹下创建三个子文件夹:clk、delay和led,分别用来存放时钟驱动文件、延时驱动文件和LED驱动文件,这样main.c函数就会清爽很多,程序功能模块清晰。工程文件夹都创建好了,接下来就是将时钟驱动、LED驱动和延时驱动相关的函数从main.c中提取出来做成一个独立的驱动文件。
实验程序编写
新建文件imx6ul.h,然后保存到文件夹imx6ul中,就是引用了一些头文件,以后我们就可以在其他文件中需要引用imx6ul.h就可以了。
编写led驱动代码
编写时钟驱动代码
编写延时驱动代码
修改main.c文件
编写Makefile和链接脚本
1 | |
该Makefile代码是一个通用Makefile,我们以后所有的裸机例程都使用这个Makefile。使用时候只要将所需要编译的源文件所在的目录添加到Makefile中即可。
我们接下来详细分析一下Makefile源码:
- 第1~7行定义了一些变量,除了第2行以外其它的都是跟编译器有关的,如果使用其它编译器的话只需要修改第1行即可。
- 第2行的变量TARGET目标名字,不同的例程肯定名字不一一样。
- 第9行的变量INCDIRS包含整个工程的.h头文件目录,文件中的所有头文件目录都要添加到变量INCDIRS中。比如本例程中包含.h头文件的目录有imx6ul、bsp/clk、bsp/delay和bsp/led,所以就需要在变量INCDIRS中添加这些目录,即: 符号“\”,相当于“换行符”,表示本行和下一行属于同一行,一般一行写不下的时候就用符号“\”来换行。
1
INCDIRS := imx6ul bsp/clk bsp/led bsp/delay
在后面的裸机例程中我们会根据实际情况来在变量INCDIRS中添加头文件目录。 - 第14行是变量SRCDIRS,和变量INCDIRS一样,只是SRCDIRS包含的是整个工程的所有.c和.S文件目录。比如本例程包含有.c和.S的目录有bsp/clk、bsp/delay、bsp/led和project,即:同样的,后面的裸机例程中我们也要根据实际情况在变量SRCDIRS中添加相应的文件目录。
1
SRCDIRS := projectbsp/clk bsp/led bsp/delay - 第19行的变量INCLUDE是用到了函数patsubst,通过函数patsubst给变量INCDIRS添加一个“-I”,即: 加“-I”的目的是因为Makefile语法要求指明头文件目录的时候需要加上“-I”。
1
INCLUDE := -I imx6ul -I bsp/clk -I bsp/led -I bsp/delay - 第21行变量SFILES保存工程中所有的.s汇编文件(包含绝对路径),变量SRCDIRS已经存放了工程中所有的.c和.S文件,所以我们只需要从里面挑出所有的.S汇编文件即可,这里借助了函数foreach和函数wildcard,最终SFILES如下:
1
SFILES := project/start.S - 第22行变量CFILES和变量SFILES一样,只是CFILES保存工程中所有的.c文件(包含绝对路径),最终CFILES如下:
1
CFILES = project/main.c bsp/clk/bsp_clk.c bsp/led/bsp_led.c bsp/delay/bsp_delay.c - 第24和25行的变量SFILENDIR和CFILENDIR包含所有的.S汇编文件和.c文件,相比变量SFILES和CFILES,SFILENDIR和CFILNDIR只是文件名,不包含文件的绝对路径。使用函数notdir将SFILES和CFILES中的路径去掉即可,SFILENDIR和CFILENDIR如下:
1
2SFILENDIR = start.S
CFILENDIR = main.c bsp_clk.c bsp_led.c bsp_delay.c - 第27和28行的变量SOBJS和COBJS是.S和.c文件编译以后对应的.o文件目录,默认所有的文件编译出来的.o文件和源文件在同一个目录中,这里我们将所有的.o文件都放到obj文件夹下,SOBJS和COBJS内容如下:
1
2SOBJS = obj/start.o
COBJS = obj/main.o obj/bsp_clk.o obj/bsp_led.o obj/bsp_delay.o - 第29行变量OBJS是变量SOBJS和COBJS的集合,如下:
1
OBJS = obj/start.o obj/main.o obj/bsp_clk.o obj/bsp_led.o obj/bsp_delay.o - 第31行的VPATH是指定搜索目录的,这里指定的搜素目录就是变量SRCDIRS所保存的目录,这样当编译的时候所需的.S和.c文件就会在SRCDIRS中指定的目录中查找。
- 第33行指定了一个伪目标clean,伪目标前面讲解Makefile的时候已经讲解过了。
- 第35~47行就很熟悉了,
的Makefile文件内容重点工作是找到要编译哪些文件?编译的.o文件存放到哪里?使用到的编译命令和前面实验使用的一样,其实Makefile的重点工作就是解决“从哪里来到哪里去的”问题,也就是找到要编译的源文件、编译结果存放到哪里?真正的编译命令很简洁。
链接脚本imx6ul.lds的内容基本和上一章一样,主要是start.o文件路径不同,且删除了main.o 路径
1 | |
编译下载
这里下载遇到了问题,sd卡插入,能够识别,使用命令下载也正常。但是接到板子,程序并不能读取运行。尝试了弹出sd卡再下载,都不行。最后重启了 Ubuntu 问题解决了。
其实这个问题在第一个例程下载时有说过。
蜂鸣器实验
硬件原理分析
当SNVS_TAMPER1输出低电平的时候Q1导通,相当于蜂鸣器的正极连接到DCDC_3V3,蜂鸣器形成一个通路,因此蜂鸣器会鸣叫。同理,当SNVS_TAMPER1输出高电平的时候Q2不导通,那么蜂鸣器就没有形成一个通路,因此蜂鸣器也就不会鸣叫。
试验程序编写
新建文件夹“6_beep”,然后将上一章试验中的所有内容拷贝到刚刚新建的“6_beep”里面。
新建VSCode工程,工程创建完成以后在bsp文件夹下新建名为“beep”的文件夹,蜂鸣器驱动文件都放到“beep”文件夹里面。新建bsp_beep.h
1 | |
新建文件bsp_beep.c
1 | |
beep.c文件一共有两个函数:beep_init和beep_switch,其中beep_init用来初始化BEEP所使用的GPIO,也就是SNVS_TAMPER1,将其复用为GPIO5_IO01,和上一章的LED灯初始化函数一样。beep_switch函数用来控制BEEP的开关,也就是设置GPIO5_IO01的高低电平。
编写Makefile和链接脚本
1 | |
- 第2行修改目标的名称为“beep”。
- 第10行在变量INCDIRS中添加蜂鸣器驱动头文件路径,也就是文件beep.h的路径。
- 第16行在变量SRCDIRS中添加蜂鸣器驱动文件路劲,也就是文件beep.c的路径。
链接脚本就使用之前的链接脚本文件imx6ul.lds即可。
按键输入实验
本试验我们用到的硬件有:
- LED灯LED0。
- 蜂鸣器。
- 1个按键KEY0。
按键KEY0的原理图如图15.2.1所示
实验程序编写
重新创建VSCode工程,工作区名字为“key”,在工程目录的bsp文件夹中创建名为“key”和“gpio”两个文件夹。按键相关的驱动文件都放到“key”文件夹中,本章试验我们对GPIO的操作编写一个函数集合,也就是编写一个GPIO驱动文件,GPIO的驱动文件放到“gpio”文件夹里面。新建bsp_gpio.c和bsp_gpio.h这两个文件,将这两个文件都保存到刚刚创建的bsp/gpio文件夹里面,然后在bsp_gpio.h文件夹里面输入如下内容:
1 | |
bsp_gpio.h中定义了一个枚举类型gpio_pin_direction_t和结构体gpio_pin_config_t,枚举类型gpio_pin_direction_t表示GPIO方向,输入或输出。结构体gpio_pin_config_t是GPIO的配置结构体,里面有GPIO的方向和默认输出电平两个成员变量。在bsp_gpio.c中输入如下所示内容:
1 | |
- base:要初始化的GPIO所属于的GPIO组,比如GPIO1_IO18就属于GPIO1组。
- pin:要初始化GPIO在组内的标号,比如GPIO1_IO18在组内的编号就是18。
- config:要初始化的GPIO配置结构体,用来指定GPIO配置为输出还是输入。
- value:要设置的值,1(高电平)或者0(低电平)。
我们以后就可以使用函数gpio_init设置指定GPIO为输入还是输出,使用函数gpio_pinread和gpio_pinwrite来读写指定的GPIO。
新建bsp_key.c和bsp_key.h这两个文件,将这两个文件都保存到刚刚创建的bsp/key文件夹里面,然后在bsp_key.h文件夹里面输入如下内容:
1 | |
在bsp_key.c中输入如下所示内容:
1 | |
bsp_key.c中一共有两个函数:key_init和key_getvalue,key_init是按键初始化函数,用来初始化按键所使用的UART1_CTS这个IO。函数key_init先设置UART1_CTS复用为GPIO1_IO18,然后配置UART1_CTS这个IO为速度为100MHz,默认22K上拉。最后调用函数gpio_init来设置GPIO1_IO18为输入功能。
最后就是main.c文件的内容了,在main.c中输入如下代码:
1 | |
编译下载验证
Makefile在之前章节的基础上修改变量TARGET为key,在变量INCDIRS和SRCDIRS中追加“bsp/gpio”和“bsp/key”,修改完成以后如下所示:
1 | |
烧写成功以后将SD卡插到开发板的SD卡槽中,然后复位开发板。如果代码运行正常的话LED0会以大约500ms周期闪烁,按下开发板上的KEY0按键,蜂鸣器打开,再按下KEY0按键,蜂鸣器关闭。
主频和时钟配置实验
系统会有时钟默认配置,所以不修改的时钟理论是不需要再单独设置,保持默认即可。但如果该时钟的上一级时钟更改了,就要看是否会影响到默认设置再做修改。
I.MX6U时钟系统详解
I.MX6U的系统主频为528MHz,有些型号可以跑到696MHz,但是默认情况下内部bootrom会将I.MX6U的主频设置为396MHz。我们在使用I.MX6U的时候肯定是要发挥它的最大性能,那么主频肯定要设置到528MHz(其它型号可以设置更高,比如696MHz),其它的外设时钟也要设置到NXP推荐的值。I.MX6U的系统时钟在《I.MX6ULL/I.MX6UL参考手册》的第10章“Chapter 10Clock and Power Management”和第18章“Chapter 18Clock Controller Module (CCM)”这两章有详细的讲解。
系统时钟来源
I.MX6U-ALPHA开发板的系统时钟来源于两部分:32.768KHz和24MHz的晶振,其中32.768KHz晶振是I.MX6U 的RTC时钟源,24MHz晶振是I.MX6U内核和其它外设的时钟源,也是我们重点要分析的。
7路PLL时钟源
I.MX6U的外设有很多,不同的外设时钟源不同,NXP将这些外设的时钟源进行了分组,一共有7组,这7组时钟源都是从24MHz晶振PLL而来的,因此也叫做7组PLL,这7组PLL结构如图所示:
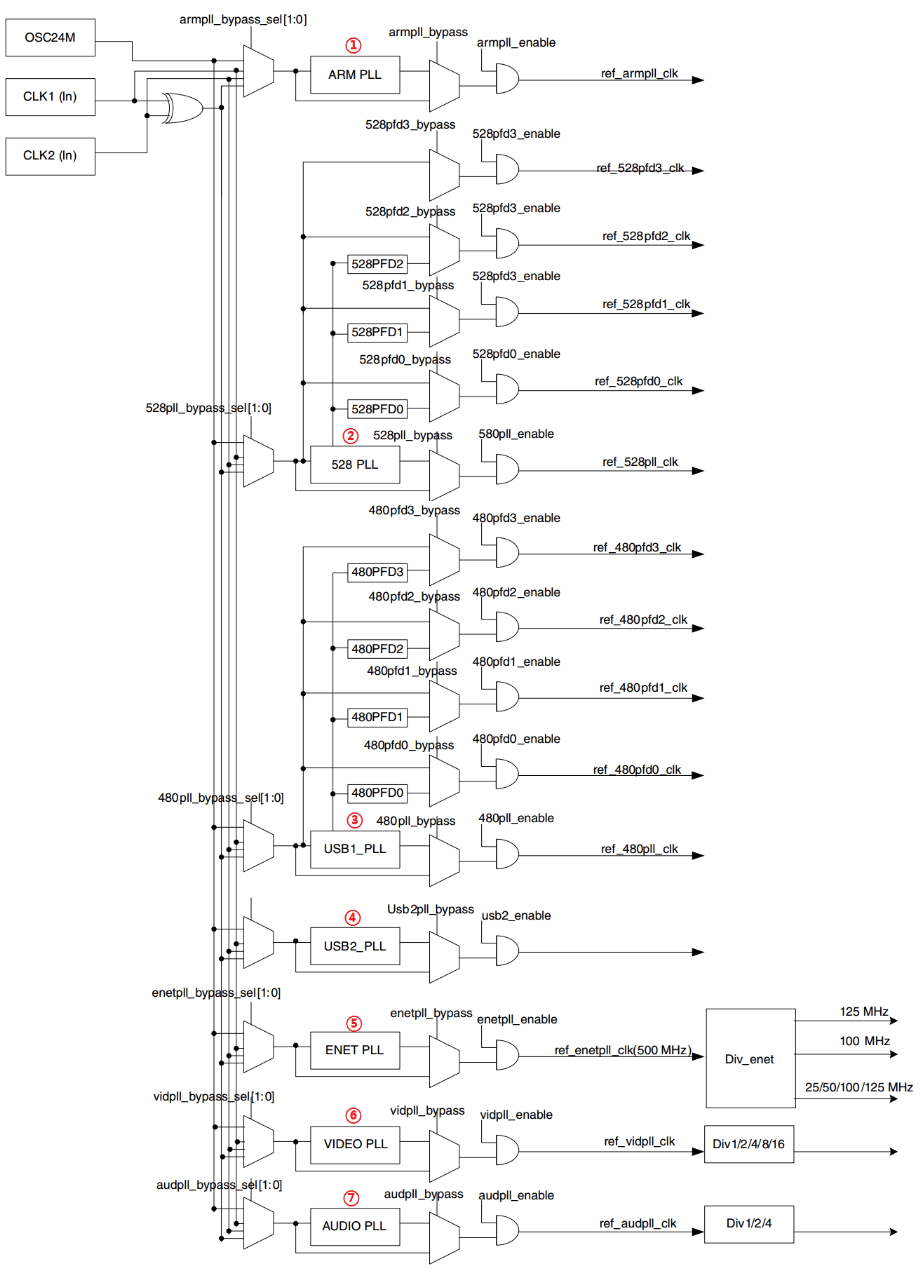
- ARM_PLL(PLL1),此路PLL是供ARM内核使用的,ARM内核时钟就是由此PLL生成的,此PLL通过编程的方式最高可倍频到1.3GHz。
- 528_PLL(PLL2),此路PLL也叫做System_PLL,此路PLL是固定的22倍频,不可编程修改。因此,此路PLL时钟=24MHz* 22 =528MHz,这也是为什么此PLL叫做528_PLL的原因。此PLL分出了4路PFD,分别为:PLL2_PFD0~PLL2_PFD3,这4路PFD和528_PLL共同作为其它很多外设的根时钟源。通常528_PLL和这4路PFD是I.MX6U内部系统总线的时钟源,比如内处理逻辑单元、DDR接口、NAND/NOR接口等等。
- USB1_PLL(PLL3),此路PLL主要用于USBPHY,此PLL也有四路PFD,为:PLL3_PFD0~PLL3_PFD3,USB1_PLL是固定的20倍频,因此USB1_PLL=24MHz *20=480MHz。USB1_PLL虽然主要用于USB1PHY,但是其和四路PFD同样也可以作为其他外设的根时钟源。
- USB2_PLL(PLL7),看名字就知道此路PLL是给USB2PHY使用的。同样的,此路PLL固定为20倍频,因此也是480MHz。
- ENET_PLL(PLL6),此路PLL固定为20+5/6倍频,因此ENET_PLL=24MHz *(20+5/6) = 500MHz。此路PLL用于生成网络所需的时钟,可以在此PLL的基础上生成25/50/100/125MHz的网络时钟。
- VIDEO_PLL(PLL5),此路PLL用于显示相关的外设,比如LCD,此路PLL的倍频可以调整,PLL的输出范围在650MHz~1300MHz。此路PLL在最终输出的时候还可以进行分频,可选1/2/4/8/16分频。
- AUDIO_PLL(PLL4),此路PLL用于音频相关的外设,此路PLL的倍频可以调整,PLL的输出范围同样也是650MHz~1300MHz,此路PLL在最终输出的时候也可以进行分频,可选1/2/4分频。
时钟树简介
《IMX6ULL参考手册》里时钟树在“Chapter 18Clock Controller Module (CCM)”的18.3小节给出了I.MX6U详细的时钟树图:
左边的CLOCK_SWITCHER就是我们上一小节讲解的那7路PLL和8路PFD,右边的SYSTEM CLOCKS就是芯片外设,中间的CLOCK ROOT GENERATOR是最复杂的!这一部分就像“月老”一样,给左边的CLOCK_SWITCHER和右边的SYSTEM CLOCKS进行牵线搭桥。外设时钟源是有多路可以选择的,CLOCK ROOT GENERATOR就负责从7路PLL和8路PFD中选择合适的时钟源给外设使用。
《IMX6ULL参考手册》里时钟树在“Chapter 18Clock Controller Module (CCM)”的18.5.1.5.1 Clock Switcher
Switcher clocks 见下图
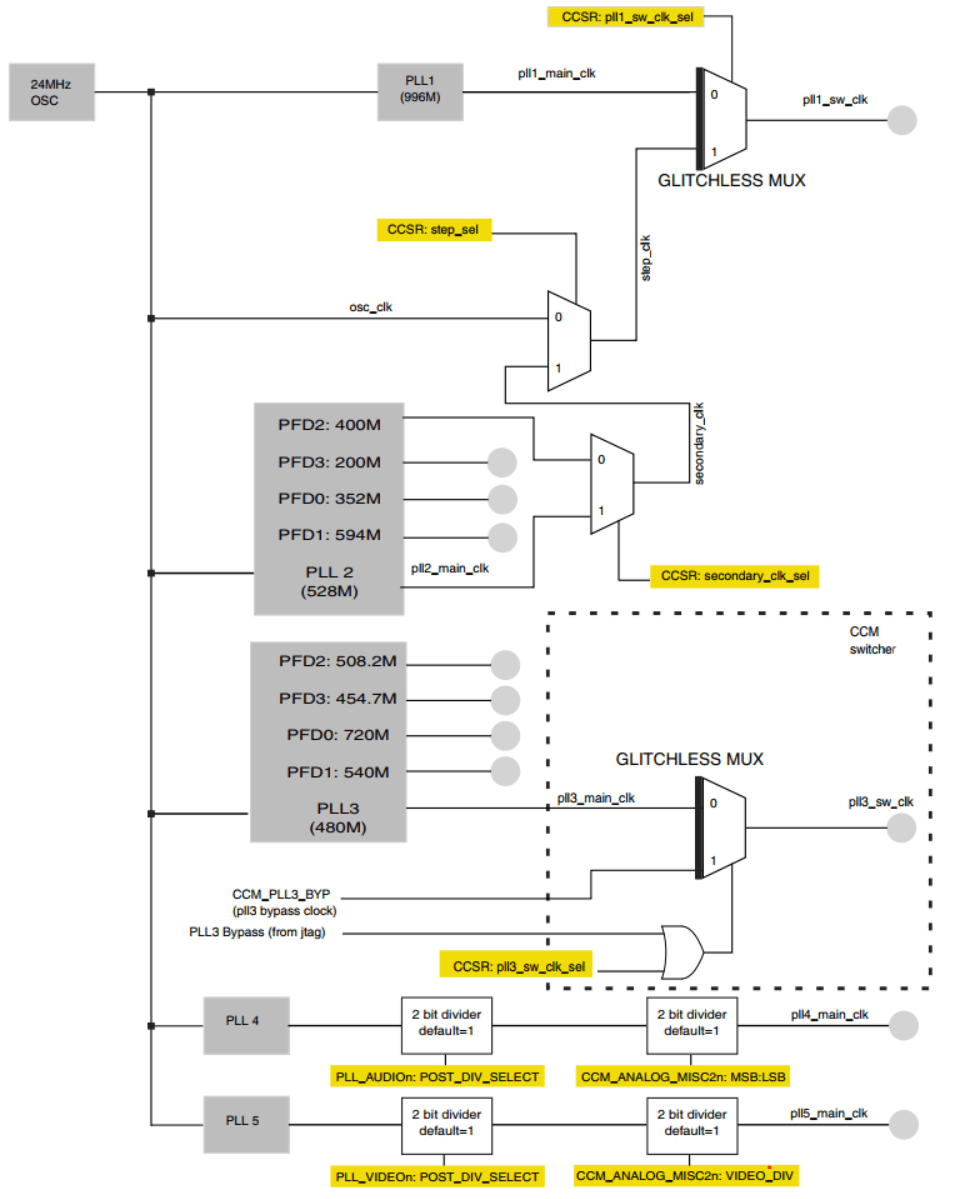
内核时钟设置
先从主频开始,我们将I.MX6U的主频设置为528MHz,ARM内核时钟如图所示:
- ① 内核时钟源来自于PLL1
- ② 通过寄存器CCM_CACRR的ARM_PODF位对PLL1进行分频,可选择1/2/4/8分频,
- ③ 大家不要被此处的2分频给骗了,此处没有进行2分频(我就被这个2分频骗了好久,主频一直配置不正确!)。
- ④ 经过第②步2分频以后的就是ARM的内核时钟,也就是I.MX6U的主频。
经过上面几步的分析可知,假如我们要设置内核主频为528MHz,那么PLL1可以设置为1056MHz,寄存器CCM_CACRR的ARM_PODF位设置为2分频即可。
同理,如果要将主频设置为696MHz,那么PLL1就可以设置为696MHz,CCM_CACRR的ARM_PODF设置为1分频即可。
修改I.MX6U主频的修改步骤如下:
- 设置寄存器CCSR的STEP_SEL位,设置step_clk的时钟源为24M的晶振。
- 设置寄存器CCSR的PLL1_SW_CLK_SEL位,设置pll1_sw_clk的时钟源为step_clk=24MHz,通过这一步我们就将I.MX6U的主频先设置为24MHz,直接来自于外部的24M晶振。
- 设置寄存器CCM_ANALOG_PLL_ARMn,将pll1_main_clk(PLL1)设置为1056MHz。
- 设置寄存器CCSR的PLL1_SW_CLK_SEL位,重新将pll1_sw_clk的时钟源切换回pll1_main_clk,切换回来以后的pll1_sw_clk就等于1056MHz。
- 最后设置寄存器CCM_CACRR的ARM_PODF为2分频,I.MX6U的内核主频就为1056/2=528MHz。
PFD时钟设置
置好主频以后我们还需要设置好其他的PLL和PFD时钟,PLL1上一小节已经设置了,PLL2、PLL3和PLL7固定为528MHz、480MHz和480MHz,PLL4~PLL6都是针对特殊外设的,用到的时候再设置。因此,接下来重点就是设置PLL2和PLL3的各自4路PFD,NXP推荐的这8路PFD频率如表所示:
AHB、IPG和PERCLK外设时钟设置
这里正点原子教程称为根时钟,但自认为叫外设时钟要好一下,概念越多容易混乱。参考时钟树知道:
- AHB:即AHB_CLK_ROOT。用于 uSDHC。
- IPG:即IPG_CLK_ROOT。用于 ADC-WDOG。貌似目前并没有用到这个外设。
- PERCLK:即PERCLK_CLK_ROOT。用于EPIT-I2C。貌似目前并没有用到这个外设。
I.MX6U外设时钟可设置范围如图所示:
图给出了大多数外设的根时钟设置范围,AHB_CLK_ROOT最高可以设置132MHz,IPG_CLK_ROOT和PERCLK_CLK_ROOT最高可以设置66MHz。
AHB_CLK_ROOT和IPG_CLK_ROOT的涉及如图所示: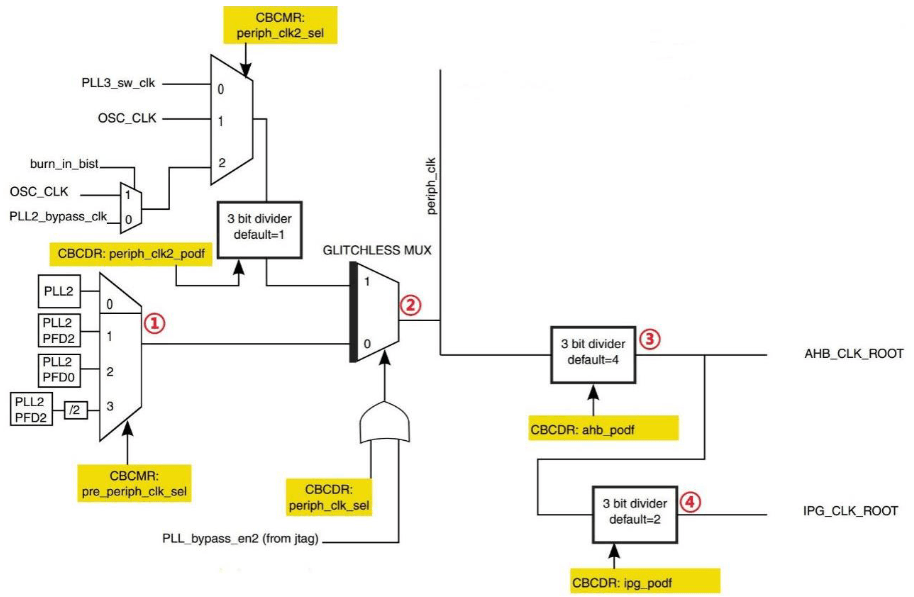
- ① 此选择器用来选择pre_periph_clk的时钟源,可以选择PLL2、PLL2_PFD2、PLL2_PFD0和PLL2_PFD2/2。寄存器CCM_CBCMR的PRE_PERIPH_CLK_SEL位决定选择哪一个,默认选择PLL2_PFD2,因此pre_periph_clk=PLL2_PFD2=396MHz。
- ② 此选择器用来选择periph_clk的时钟源,由寄存器CCM_CBCDR的PERIPH_CLK_SEL位与PLL_bypass_en2组成的或来选择。当CCM_CBCDR的PERIPH_CLK_SEL位为0的时候periph_clk=pr_periph_clk=396MHz。
- ③ 通过CBCDR的AHB_PODF位来设置AHB_CLK_ROOT的分频值,可以设置1~8分频,如果想要AHB_CLK_ROOT=132MHz的话就应该设置为3分频:396/3=132MHz。图16.1.2中虽然写的是默认4分频,但是I.MX6U的内部bootrom将其改为了3分频!
- ④ 通过CBCDR的IPG_PODF位来设置IPG_CLK_ROOT的分频值,可以设置1~4分频,IPG_CLK_ROOT时钟源是AHB_CLK_ROOT,要想IPG_CLK_ROOT=66MHz的话就应该设置2分频:132/2=66MHz。
最后要设置的就是PERCLK_CLK_ROOT时钟频率,其时钟结构图如图16.1.6.3所示:
PERCLK_CLK_ROOT来 源 有 两 种 :OSC(24MHz)和IPG_CLK_ROOT,由寄存器CCM_CSCMR1的PERCLK_CLK_SEL位来决定,如果为0的话PERCLK_CLK_ROOT的时钟源就是IPG_CLK_ROOT=66MHz。可以通过寄存器CCM_CSCMR1的PERCLK_PODF位来设置分频,如果要设置PERCLK_CLK_ROOT为66MHz的话就要设置为1分频。
在修改如下时钟选择器或者分频器的时候会引起与MMDC的握手发生:
- mmdc_podf
- periph_clk_sel
- periph2_clk_sel
- arm_podf
- ahb_podf
- 发生握手信号以后需要等待握手完成,寄存器CCM_CDHIPR中保存着握手信号是否完成,如果相应的位为1的话就表示握手没有完成,如果为0的话就表示握手完成。另外在修改arm_podf和ahb_podf的时候需要先关闭其时钟输出,等修改完成以后再打开,否则的话可能会出现在修改完成以后没有时钟输出的问题。本教程需要修改寄存器CCM_CBCDR的AHB_PODF位来设置AHB_ROOT_CLK的时钟,所以在修改之前必须先关闭AHB_ROOT_CLK的输出。但是笔者没有找到相应的寄存器,因此目前没法关闭,那也就没法设置AHB_PODF了。不过AHB_PODF内部bootrom设置为了3分频,如果pre_periph_clk的时钟源选择PLL2_PFD2的话,AHB_ROOT_CLK也是396MHz/3=132MHz。
实验程序编写
本试验在上一章试验“7_key”的基础上完成,因为本试验只配置I.MX6U的系统时钟,因此我们直接在文件“bsp_clk.c”上做修改,修改bsp_clk.c的内容如下: s