嵌入式面试-知识点复习
本文最后更新于:2023年2月22日 晚上
编程 语言
汇编
C/C++
字节内存
32位机中,
char: 1个字节
short: 2个字节
int: 4个字节
long: 4个字节
float:4个字节
double:4个字节
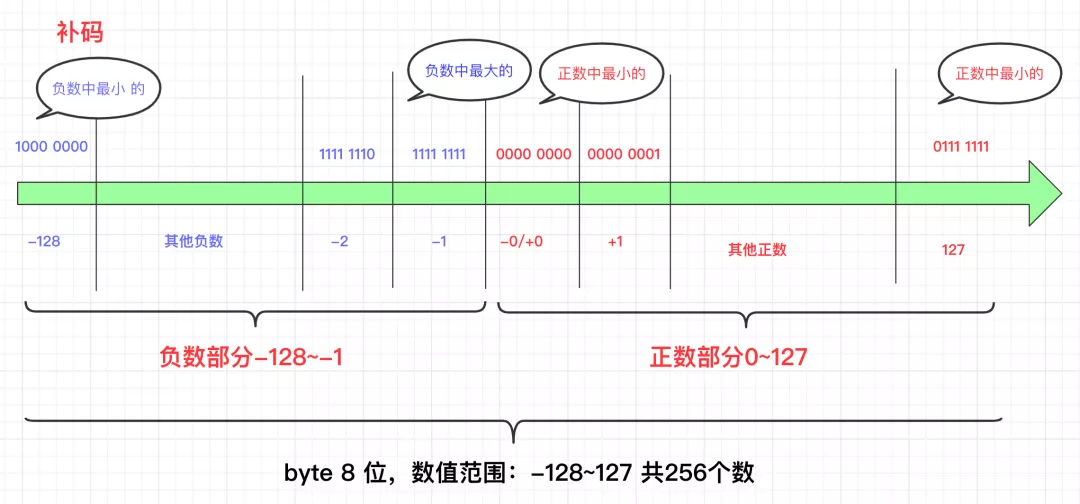
机器数和真值
1、机器数
一个数在计算机中的二进制表示形式, 叫做这个数的机器数。最高位存放符号, 正数为0, 负数为1.
比如,十进制中的数 +3 ,计算机字长为8位,转换成二进制就是00000011。如果是 -3 ,就是 10000011 。那么,这里的 00000011 和 10000011 就是机器数。
2、真值
带 ‘+’ 、’-‘号的数值。带符号位的机器数对应的真正数值称为机器数的真值。
例:0000 0001的真值 = +000 0001 = +1,1000 0001的真值 = –000 0001 = –1
原码、反码、补码
原码就是机器数,最高位表示符号位,其他位存放该数的二进制的绝对值。
1 | |
反码
- 正数的反码是其本身
- 负数的反码是在其原码的基础上, 符号位不变,其余各个位取反.
1
2[+1] = [00000001]原 = [00000001]反
[-1] = [10000001]原 = [11111110]反
补码
- 正数的补码就是其本身
- 负数的补码是在其原码的基础上, 符号位不变, 其余各位取反, 最后+1. (即在反码的基础上+1)
1
2
3[+1] = [00000001]原 = [00000001]反 = [00000001]补
[-1] = [10000001]原 = [11111110]反 = [11111111]补
因为机器使用补码(只有加法而没有减法,即没有正负号的概念)
1 | |
volatile
参考资料:如何使用 C 语言中的 volatile 关键字?
由于访问寄存器要比访问内存单元快的多,编译器在存取变量时,为提高存取速度,编译器优化有时会先把变量读取到一个寄存器中;以后再取变量值时就直接从寄存器中取值。但在很多情况下会读取到脏数据,严重影响程序的运行效果。
volatile 关键字的正确用法
任何时候, 只要这个变量的值可能在不确定的时刻被修改, 那么它都应该被声明为 volatile. 什么是 “不确定的时刻” 呢, 其实总共不过是只有三种情况:
- 存储器映射的硬件寄存器(Memory-mapped peripheral registers)
- 被 ISR 修改的全局变量
- 多线程编程中, 被多个 task 共同访问或修改的全局变量
问题:一个参数既可以是const还可以是volatile吗?
可以的,例如只读的状态寄存器。它是volatile因为它可能被意想不到地改变。它是const因为程序不应该试图去修改它。
问题:一个指针可以是volatile 吗?
可以,当一个中服务子程序修改一个指向buffer的指针时。
问题:下面的函数有什么错误?
1 | |
该程序的目的是用来返指针ptr指向值的平方,但是,由于ptr指向一个volatile型参数,编译器将产生类似下面的代码:
1 | |
由于*ptr的值可能被意想不到地该变,因此a和b可能是不同的。结果,这段代码可能返不是你所期望的平方值!正确的代码如下:
1 | |
inline函数
在C语言中,如果一些函数被频繁调用,不断地有函数入栈,即函数栈,会造成栈空间或栈内存的大量消耗。为了解决这个问题,特别的引入了inline修饰符,表示为内联函数。
大多数的机器上,调用函数都要做很多工作:调用前要先保存寄存器,并在返回时恢复,复制实参,程序还必须转向一个新位置执行。C++中支持内联函数,其目的是为了提高函数的执行效率,用关键字 inline 放在函数定义(注意是定义而非声明)的前面即可将函数指定为内联函数,内联函数通常就是将它在程序中的每个调用点上“内联地”展开。
内联是以代码膨胀(复制)为代价,仅仅省去了函数调用的开销,从而提高函数的执行效率
error
1 | |
#ifndef #define #endif 作用和用法
主要目的是防止頭文件的重複包含和編譯.h文件,如下:
#ifndef XX_H
#define XX_H
…
#endif
给定一个整型变量a,写两段代码,第一个设置a的bit 3,第二个清除a 的bit 3。在以上两个操作中,要保持其它位不变。
1 | |
评价下面的代码片断:
1 | |
对于一个int型不是16位的处理器为说,上面的代码是不正确的。应编写如下:
unsigned int compzero = ~0;
对于一个频繁使用的短小函数,在C语言中应用什么实现,在C++中应用什么实现?
c用宏定义,c++用inline
纯虚函数如何定义?使用时应注意什么?
`virtual void f()=0;`
是接口,子类必须要实现
sizeof() 和 strlen()区别
- sizeof() 是一个运算符,而 strlen() 是一个函数。
- sizeof() 计算的是变量或类型所占用的内存字节数,而 strlen() 计算的是字符串中字符的个数。
- sizeof() 可以用于任何类型的数据,而 strlen() 只能用于以空字符 ‘\0’ 结尾的字符串。
- sizeof() 计算字符串的长度,包含末尾的 ‘\0’,strlen() 计算字符串的长度,不包含字符串末尾的 ‘\0’。
1 | |
static的用法(定义和用途)
1)用static修饰局部变量:使其变为静态存储方式(静态数据区),那么这个局部变量在函数执行完成之后不会被释放,而是继续保留在内存中。
2)用static修饰全局变量:使其只在本文件内部有效,而其他文件不可连接或引用该变量。
3)用static修饰函数:对函数的连接方式产生影响,使得函数只在本文件内部有效,对其他文件是不可见的(这一点在大工程中很重要很重要,避免很多麻烦,很常见)。这样的函数又叫作静态函数。使用静态函数的好处是,不用担心与其他文件的同名函数产生干扰,另外也是对函数本身的一种保护机制。
const的用法(定义和用途)
const主要用来修饰变量、函数形参和类成员函数:
1)用const修饰常量:定义时就初始化,以后不能更改。
2)用const修饰形参:func(const int a){};该形参在函数里不能改变
3)用const修饰类成员函数:该函数对成员变量只能进行只读操作,就是const类成员函数是不能修改成员变量的数值的。
下面的声明都是什么意思?
前两个的作用是一样,a是一个常整型数。
第三个意味着a是一个指向常整型数的指针(也就是,整型数是不可修改的,但指针可以)。
第四个意思a是一个指向整型数的常指针(也就是说,指针指向的整型数是可以修改的,但指针是不可修改的)。
最后一个意味着a是一个指向常整型数的常指针(也就是说,指针指向的整型数是不可修改的,同时指针也是不可修改的)。
1 | |
const常量和#define的区别(编译阶段、安全性、内存占用等)
用#define max 100 ; 定义的常量是没有类型的(不进行类型安全检查,可能会产生意想不到的错误),所给出的是一个立即数,编译器只是把所定义的常量值与所定义的常量的名字联系起来,define所定义的宏变量在预处理阶段的时候进行替换,在程序中使用到该常量的地方都要进行拷贝替换;
用const int max = 255 ; 定义的常量有类型(编译时会进行类型检查)名字,存放在内存的静态区域中,在编译时确定其值。在程序运行过程中const变量只有一个拷贝,而#define所定义的宏变量却有多个拷贝,所以宏定义在程序运行过程中所消耗的内存要比const变量的大得多
经典的sizeof(struct)和sizeof(union)内存对齐
结构体内所有数据成员各自内存对齐后,结构体本身还要进行一次内存对齐,保证整个结构体占用内存大小是结构体内最大数据成员的最小整数倍;
- 使用32位编译,int占4, char 占1, unsigned short 占2,char* 占4,函数指针占4个,由于是32位编译是4字节对齐,所以该结构体占16个字节。(说明:按几字节对齐,是根据结构体的最长类型决定的,这里是int是最长的字节,所以按4字节对齐);
1
2
3
4
5
6
7
8struct CAT_s
{
int ld;
char Color;
unsigned short Age;
char *Name;
void(*Jump)(void);
}Garfield;
如程序中有#pragma pack(n)预编译指令,则所有成员对齐以n字节为准(即偏移量是n的整数倍),不再考虑当前类型以及最大结构体内类型。
1 | |
1.找到占用字节最多的成员;
2.union的字节数必须是占用字节最多的成员的字节的倍数,而且需要能够容纳其他的成员
- 本例中long,占用8个字节,int k[5]中都是int类型,仍然是占用4个字节的,然后union的字节数必须是占用字节最多的成员的字节的倍数,而且需要能够容纳其他的成员,为了要容纳k(20个字节),就必须要保证是8的倍数的同时还要大于20个字节,所以是24个字节。
1 | |
位域:
- 位段声明和结构体类似
- 位段的成员必须是int、unsigned int、signed int
3 .位段的成员名后边有一个冒号和一个数字
- 无位域名,只用来作填充或调整位置。是不能使用的
1
2
3
4
5
6
7struct bs
{
unsigned a:4
unsigned :0 /*空域*/
unsigned b:4 /*从下一单元开始存放*/
unsigned c:4
};
m和n一起,刚好占用一个字节内存,后是short两个个字节,加起来就3个字节,然后联合体占了四个字节,总共7个字节了,最后int h占了四个字节,就是11个字节了,由结构体字节是最大类型的整数倍,所以是12字节
那么多余的一个字节是放在什么位置呢,答案是short的前面,也就是m和n其实是占了两个字节的
结构体内的成员的首地址相对于结构体首地址的偏移量是其类型大小的整数倍,比如说short型成员相对于结构体的首地址的地址偏移量应该是2的倍数。
1 | |
大小端
大端格式:即低地址存高位数据
小端格式:即低地址存低位数据
- STM32是小端系统
- 常见的CPU PowerPC、IBM是大端模式,x86是小端模式。ARM既可以工作在大端模式,也可以工作在小端模式,一般ARM都默认是小端模式。一般通讯协议都采用的是大端模式。
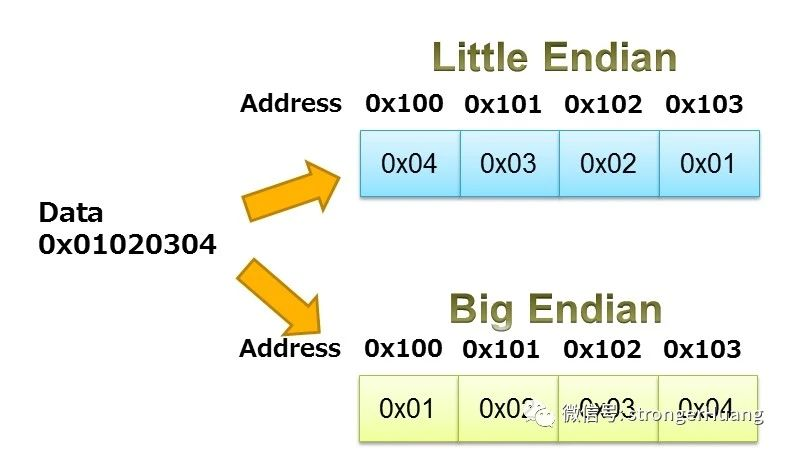
判断系统大小端
1 | |
new和malloc
1)malloc和free是c++/c语言的库函数,需要头文件支持stdlib.h;new和delete是C++的关键字,不需要头文件,需要编译器支持;
2)使用new操作符申请内存分配时,无需指定内存块的大小,编译器会根据类型信息自行计算。而malloc则需要显式地支持所需内存的大小。
3)new操作符内存分配成功时,返回的是对象类型的指针,类型严格与对象匹配,无需进行类型转换,故new是符合类型安全性的操作符。而malloc内存分配成功则是返回void,需要通过强制类型转换将void指针转换成我们需要的类型。
4)new内存分配失败时,会抛出bad_alloc异常。malloc分配内存失败时返回NULL。
extern”C” 的作用
我们可以在C++中使用C的已编译好的函数模块,这时候就需要用到extern”C”。也就是extern“C” 都是在c++文件里添加的。
extern在链接阶段起作用(四大阶段:预处理–编译–汇编–链接)。
用变量a给出下面的定义
a) 一个整型数;
b)一个指向整型数的指针;
c)一个指向指针的指针,它指向的指针是指向一个整型数;
d)一个有10个整型的数组;
e)一个有10个指针的数组,该指针是指向一个整型数;
f)一个指向有10个整型数数组的指针;
g)一个指向函数的指针,该函数有一个整型参数并返回一个整型数;
h)一个有10个指针的数组,该指针指向一个函数,该函数有一个整型参数并返回一个整型数
答案:
1 | |
链表
一个程序从开始运行到结束的完整过程(四个过程)
预处理(Pre-Processing)、编译(Compiling)、汇编(Assembling)、链接(Linking)
什么是堆,栈,内存泄漏和内存溢出?
栈由系统操作,程序员不可以操作。
所以内存泄漏是指堆内存的泄漏。堆内存是指程序从堆中分配的,大小任意的(内存块的大小可以在程序运行期决定),使用完后必须显式释放的内存。应用程序一般使用malloc,new等函数从堆中分配到一块内存,使用完后,程序必须负责相应的调用free或delete释放该内存块,否则,这块内存就不能被再次使用。
内存溢出:你要求分配的内存超出了系统能给你的,系统不能满足需求,于是产生溢出。
内存越界:向系统申请了一块内存,而在使用内存时,超出了申请的范围(常见的有使用特定大小数组时发生内存越界)
函数指针
int (*s[10])(int) 表示的是什么啊?
答案:int(s[10])(int) 函数指针数组,每个指针指向一个int func(int param)的函数。s[10]表明一个指针数组,数组长度为10,右边的(int),()为声明函数,int表明函数参数为int型。前面的int表明函数返回值为int型
程序编写
嵌入式系统中经常要用到无限循环,你怎么用C编写死循环。
答案:while(1){}或者for(;;)
写一个“标准”宏,这个宏输入两个参数并返回较小的一个。
答案:.#defineMin(X, Y) ((X)>(Y)?(Y):(X)) //结尾没有‘;
问答查错
7、请问以下代码有什么问题:
int main() { chara; char *str=&a; strcpy(str,”hello”); printf(str); return 0; }
答案:没有为str分配内存空间,将会发生异常问题出在将一个字符串复制进一个字符变量指针所指地址。虽然可以正确输出结果,但因为越界进行内在读写而导致程序崩溃。
8、char* s=”AAA”; printf(“%s”,s); s[0]=’B’; printf(“%s”,s);有什么错?
答案:”AAA”是字符串常量。s是指针,指向这个字符串常量,所以声明s的时候就有问题。 cosnt char*s=”AAA”; 然后又因为是常量,所以对是s[0]的赋值操作是不合法的。
交换两个变量的值,不使用第三个变量。即a=3,b=5,交换之后a=5,b=3;
答案:有两种解法, 一种用算术算法, 一种用^(异或)
a = a + b;
b = a – b;
a = a – b;
or
a = a^b;// 只能对int,char..
b = a^b;
a = a^b;
or
a^= b ^= a;
已知一个数组table,用一个宏定义,求出数据的元素个数
答案:#defineNTBL #define NTBL (sizeof(table)/sizeof(table[0]))
static全局变量与普通的全局变量有什么区别?static局部变量和普通局部变量有什么区别?static函数与普通函数有什么区别?
答案:
- 全局变量(外部变量)的说明之前再冠以static 就构成了静态的全局变量。全局变量本身就是静态存储方式,静态全局变量当然也是静态存储方式。这两者在存储方式上并无不同。这两者的区别虽在于非静态全局变量的作用域是整个源程序, 当一个源程序由多个源文件组成时,非静态的全局变量在各个源文件中都是有效的。而静态全局变量则限制了其作用域,即只在定义该变量的源文件内有效, 在同一源程序的其它源文件中不能使用它。由于静态全局变量的作用域局限于一个源文件内,只能为该源文件内的函数公用,因此可以避免在其它源文件中引起错误。
- 从以上分析可以看出,把局部变量改变为静态变量后是改变了它的存储方式即改变了它的生存期。把全局变量改变为静态变量后是改变了它的作用域,限制了它的使用范围。
- static函数与普通函数作用域不同。仅在本文件。只在当前源文件中使用的函数应该说明为内部函数(static),内部函数应该在当前源文件中说明和定义。对于可在当前源文件以外使用的函数,应该在一个头文件中说明,要使用这些函数的源文件要包含这个头文件
- static全局变量与普通的全局变量有什么区别:static全局变量只初使化一次,防止在其他文件单元中被引用;
- static局部变量和普通局部变量有什么区别:static局部变量只被初始化一次,下一次依据上一次结果值;
- static函数与普通函数有什么区别:static函数在内存中只有一份,普通函数在每个被调用中维持一份拷贝
程序的局部变量存在于()中,全局变量存在于()中,动态申请数据存在于()中。
答案:栈;静态区;堆
队列和栈有什么区别?
答案:队列先进先出,栈后进先出÷
版本控制
计算机基础
计算机组成原理
操作系统
计算机网络
数据结构
计算机体系结构
数据库()
编译原理
硬件
硬件基础
画图
ARM
单片机
一、MCU对比
问题一:STM32F1和F4的区别?
- 内核不同:F1是Cortex-M3内核,F4是Cortex-M4内核;
- 主频不同:F1主频72MHz,F4主频168MHz;
- 浮点运算:F1无浮点运算单位,F4有;
- 功能性能:F4外设比F1丰富且功能更强大,比如GPIO翻转速率、上下拉电阻配置、ADC精度等;
- 内存大小:F1内部SRAM最大64K,F4有192K(112+64+16)。
二、STM32 启动过程
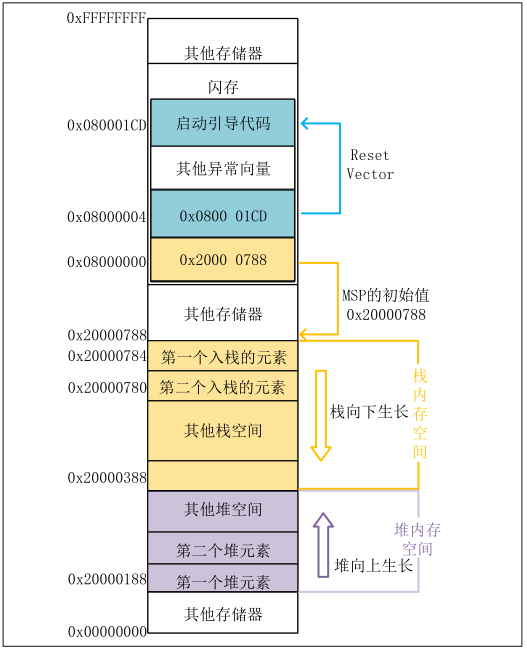
问题一:介绍以下STM32启动过程?
以F1为例
- 通过Boot引脚设定,寻找初始地址,映射MSP和PC地址
- 初始化堆栈指针 MSP = _initial_sp
- 初始化程序计数器指针 PC = Reset_Handler,第一条指令开始执行程序
- 设置堆和栈的大小
- 初始化中断向量表
- 配置外部 SRAM 作为数据存储器(可选)
- 配置系统时钟,通过调用 SystemInit 函数(可选)
- 调用 C 库中的_main 函数初始化用户堆栈,最终调用 main 函数
三、GPIO
问题一:介绍以下GPIO?
GPIO 8种工作模式(gpio_init.GPIO_Mode):
(1) GPIO_Mode_AIN 模拟输入
(2) GPIO_Mode_IN_FLOATING 浮空输入
(3) GPIO_Mode_IPD 下拉输入
(4) GPIO_Mode_IPU 上拉输入
(5) GPIO_Mode_Out_OD 开漏输出
(6) GPIO_Mode_Out_PP 推挽输出
(7) GPIO_Mode_AF_OD 复用开漏输出
(8) GPIO_Mode_AF_PP 复用推挽输出
APB2负责 AD,I/O,高级TIM,串口1。
APB1负责 DA,USB,SPI,I2C,CAN,串口2345,普通TIM,PWR
GPIO框图剖析:
四、通信
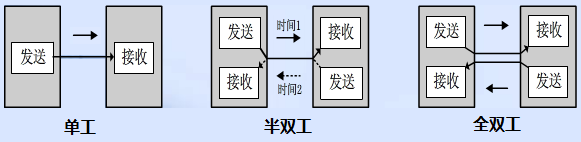
问题一:串行通信方式介绍?
- 同步通信:I2C 半双工,SPI 全双工、UART全双工同步
- 异步通信:RS485 半双工、RS232 全双工、UART全双工异步
问题二:数据同步方式
- 同步通信双方共用同一时钟信号,在总线上保持统一的时序和周期完成信息传输。
优点:可以实现高速率、大容量的数据传输,以及点对多点传输。
缺点:要求发送时钟和接收
时钟保持严格同步,收发双方时钟允许的误差较小,同时硬件复杂。 - 异步通信不需要时钟信号,而是在数据信号中加入开始位和停止位等一些同步信号,某些通信中还需要双方约定传输速率。
优点:没有时钟信号硬件简单,双方时钟可允许一定误差。
缺点:通信速率较低,只适用点对点传输。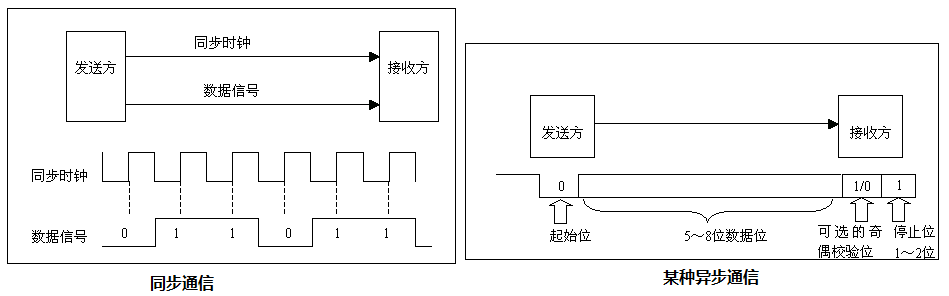
串口
串口通信中,常用的协议包括RS-232、RS-422 和 RS-485 等。
问题一:串口协议简介
- 起始位,由一个逻辑 0的数据位表示
- 停止位,可以是 0.5、1、1.5 或 2 个逻辑 1 的数据位表示
- 有效数据位,5、6、7 或 8 个位长。低位(LSB)在前,高位(MSB)在后。
- 校验位,奇校验(数据和校验中1总数为奇数),偶校验,无校验
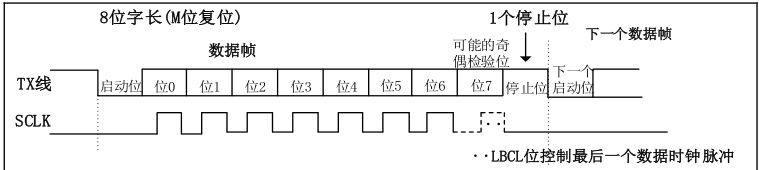
问题一:串口初始化配置?
串口设置的一般步骤可以总结为如下几个步骤:
(1)串口时钟使能,GPIO时钟使能
(2)串口复位
(3)GPIO端口模式设置
(4)串口参数初始化,主要包含:波特率设置(115200)、8个数据位、1个停止位、奇偶校验位、硬件数据流控制、收发模式。
(5)开启中断并且初始化NVIC(如果需要开启中断才需要这个步骤)
(6)使能串口
(7)编写中断处理函数
问题二:USART主要特点?
(1)全双工操作(相互独立的接收数据和发送数据);
(2)同步操作时,可主机时钟同步,也可从机时钟同步;
(3)独立的高精度波特率发生器,不占用定时/计数器;
(4)支持5、6、7、8和9位数据位,1或2位停止位的串行数据桢结构;
(5)由硬件支持的奇偶校验位发生和检验;
(6)数据溢出检测;
(7)帧错误检测;
(8)包括错误起始位的检测噪声滤波器和数字低通滤波器;
(9)三个完全独立的中断,TX发送完成、TX发送数据寄存器空、RX接收完成;
(10)支持多机通信模式;
(11)支持倍速异步通信模式。
I2C
问题一:I2C简介
- 高位(MSB)在前。
- 由数据线 SDA 和时钟线 SCL 构成
- 总线上每一个器件都有一个唯一的地址识别
- 数据线 SDA 和时钟线 SCL 都是双向线路,都通过一个电流源或上拉电阻连接到正电压。
- 起始信号,SCL 为高电平时,SDA 由高到低的跳变。是一种电平跳变时序信号。
- 停止信号,SCL 为高电平时,SDA 由低到高的跳变。是一种电平跳变时序信号
- 应答信号,发送器每发送一个字节,就在时钟脉冲 9 期间释放数据线,由接收器反馈一个应答信号。低电平为有效应答位(ACK 简称应答位),表示接收器成功地接收了该字节。
有效应答的要求是从机在第 9 个时钟脉冲之前的低电平期间将 SDA 线拉低 - 数据有效性,数据在 SCL 的上升沿到来之前就需准备好。并在下降沿到来之前必须稳定。SCL高电平期间检测数据
- 空闲状态,IIC 总线的 SDA 和 SCL 两条信号线同时处于高电平时,规定为总线的空闲状态。
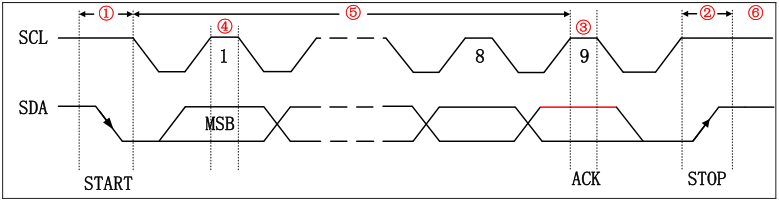
问题二:I2C配置主机模式端口该怎么配置?
软件模拟:
- GPIO 时钟
- SCL 推挽输出 SDA 开漏输出
- 编写信号函数(起始信号,停止信号,应答信号)
- 编写 IIC 的读写函数
问题三:I2C仲裁机制?
遵循“低电平优先”的原则,即谁先发送低电平谁就会掌握对总线的控制权。
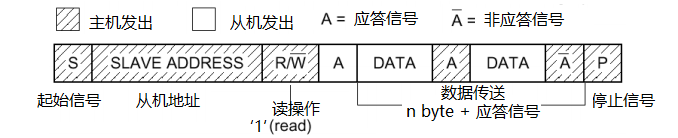
问题三:I2C基本读写过程
- 从机地址+读/写 = 8位
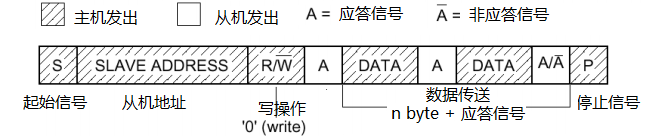
SPI
问题一:SPI需要几根线?
- MISO(Master In / Slave Out)主设备数据输入,从设备数据输出。
- MOSI(Master Out / Slave In)主设备数据输出,从设备数据输入。
- SCLK(Serial Clock)时钟信号,由主设备产生。
- CS(Chip Select)从设备片选信号,由主设备产生。。
问题二:SPI 的传输方式:
- 全双工通信,在任何时刻,主机与从机之间都可以同时进行数据的发送和接收。
- 单工通信,就是在同一时刻,只有一个传输的方向,发送或者是接收。
- 半双工通信,就是在同一时刻,只能为一个方向传输数据。
问题三:SPI通信的四种模式?
各个工作模式的不同在于 SCLK 不同, 具体工作由 CPOL,CPHA 决定。
- CPOL: (Clock Polarity),时钟极性:表示当SCLK空闲idle的时候,其电平的值是低电平0还是高电平1
- CPHA:(Clock Phase),时钟相位:对应着数据采样是在第几个边沿(edge),是第一个边沿还是第二个边沿,0对应着第一个边沿,1对应着第二个边沿。

问题三: SPI 配置步骤
- 时钟使能
- SPI 参数初始化(工作模式、数据时钟极性、时钟相位等)。
- 使能 SPI 时钟和配置相关引脚的复用功能。
- 使能 SPI
- 启动传输(数据高低位优先可选,一般高位在前)
问题三:该如何确定使用哪种模式?
看从设备的数据手册,如W25Q32JV
1 | |
232
- 全双工方式工作,需要地线、发送线和接收线三条线。
- RS232只能实现点对点的通信方式。
- RS232仅仅规定了接受端和发送端的电气特性。它没有规定或推荐任何数据协议。
- 接口信号电平高,容易损坏接口电路的芯片。逻辑“1”为-3 ~ -15V;逻辑为“0”:+3 ~ +15V,噪声裕量为2V。
- 传输速率低。最高波特率19200bps。
- 容易受到共模干扰,因此抗噪性较弱。
- 传输距离有限。只能达到大约15米。
485
问题一:485介绍
- 2 线,半双工,多点通信的类型。
- RS485 仅仅规定了接受端和发送端的电气特性。它没有规定或推荐任何数据协议。
- 用缆线两端的电压差值来表示传递信号。
- 采用平衡驱动器和差分接收器的组合,抗干扰能力强。
- 共模电压范围为-7~+12V
- 一般最大支持32个多点拓扑连接,用特制的 485 芯片,可以达到 128 个或者 256 个节点,最大的可以支持到 400 个节点。
- 传输速率高。10 米时,RS485 的数据最高传输速率可达 35Mbps,在 1200m 时,传输速度可达 100Kbps。
- 最小差分电压容限:200mV(最末端),最小1.5V差分电压输出
RS485 推荐使用在点对点网络中,比如:线型,总线型网络等,而不能是星型,环型网络。
理想情况下 RS485 需要 2 个终端匹配电阻,其阻值要求等于传输电缆的特性阻抗(一般为 120Ω)。没有特性阻抗的话,当所有的设备都静止或者没有能量的时候就会产生噪声,而且线移需要双端的电压差。没有终接电阻的话,会使得较快速的发送端产生多个数据信号的边缘,导致数据传输出错。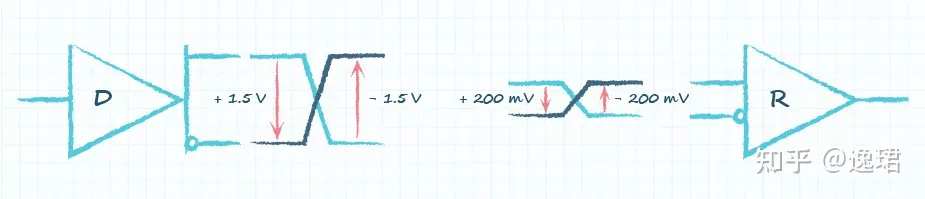
问题一:485与232比较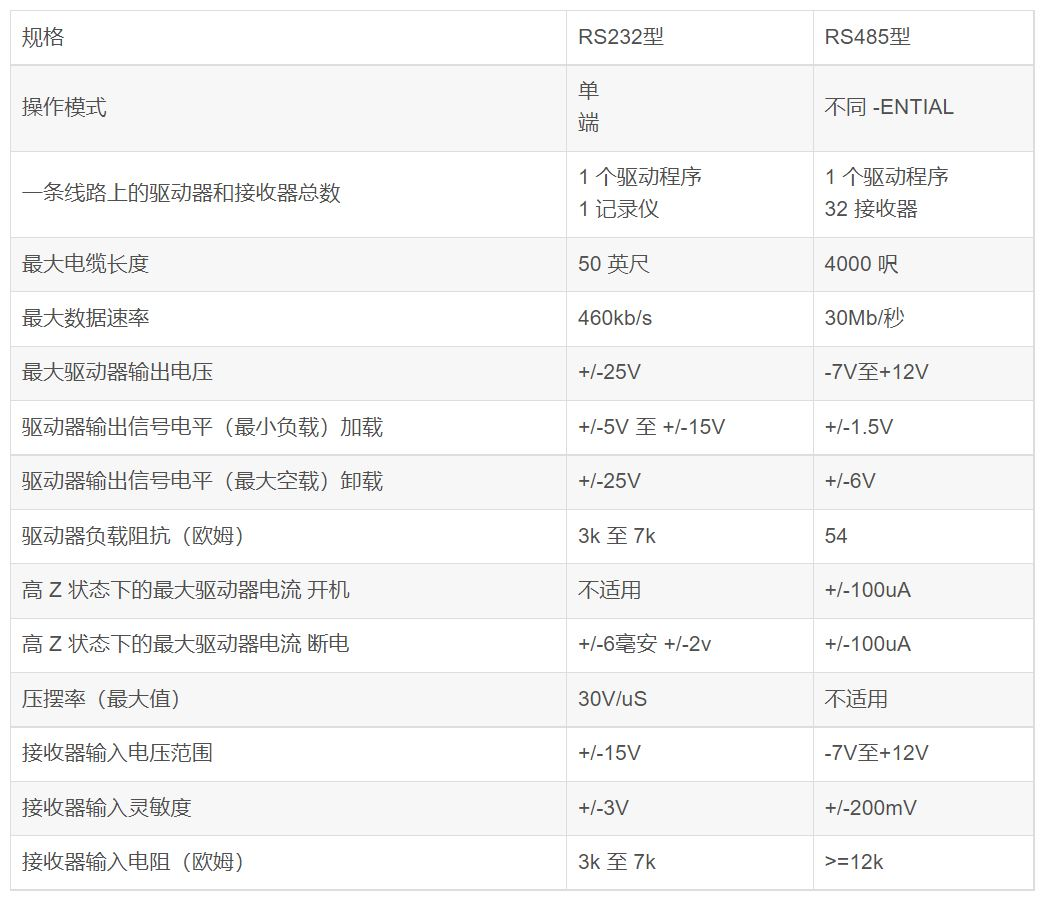
CAN
问题一:CAN总结介绍
- 半双工的
- 差分信号
- 报文的优先级,判断仲裁段 ID 信息,线与逻辑,显性电平(0)优先
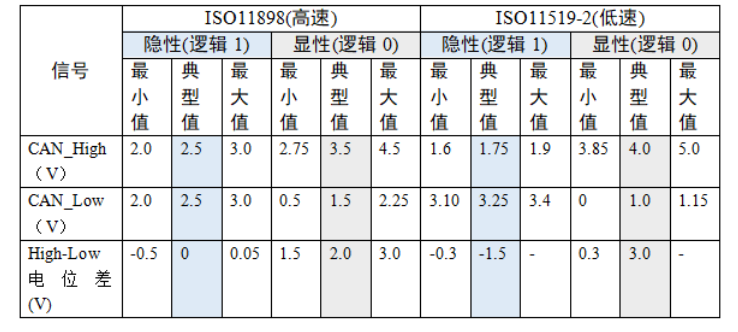
- 传输距离远(最远10Km),传输速率快(最高1MHz bps);
- 多主结构,单条总线最多可接110个节点,并可方便的扩充节点数;
- 有硬件CRC校验,受干扰概率小,数据出错率极低;
- 自动检测报文发送成功与否,可硬件自动重发,传输可靠性很高;
- 硬件报文滤波功能,只接收必要信息,减轻cpu负担,简化软件编制;
问题一:CAN 协议5 种类型
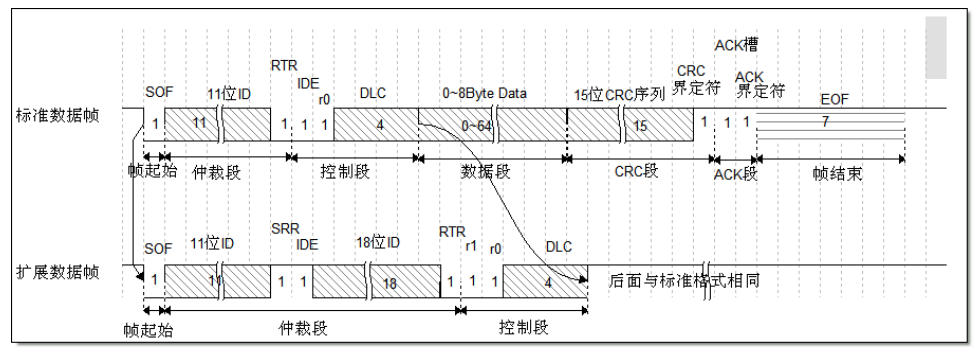
问题一:数据帧
- RTR 位 (Remote Transmission Request Bit),远程传输请求位,为显性电平时表示数据帧,隐性电平时表示遥控帧。
- IDE 位 (Identifier ExtensionBit),标识符扩展位,它是用于区分标准格式与扩展格式,显性电平时表示标准格式,隐性电平时表示扩展格式。
- SRR 位 (Substitute Remote Request Bit),只存在于扩展格式,它用于替代标准格式中的 RTR位。
- 控制段。 r1 和 r0 为保留位,默认为显性。DLC 段 (Data Length Code),译为数据长度码,它由 4 个数据位组成,用于表示本报文中的数据段含有多少个字节, DLC 段表示的数字为 0~8。
- 数据段为数据帧的核心内容,它是节点要发送的原始信息,由 0~8 个字节组成,MSB 先行。
- CRC 段,CAN 的报文包含了一段 15 位的 CRC 校验码。CRC 部分的计算一般由 CAN 控制器硬件完成,出错时的处理则由软件控制最大重发数。在 CRC 校验码之后,有一个 CRC 界定符,它为隐性位,主要作用是把 CRC 校验码与后面的 ACK段间隔起来。
- ACK 段,ACK 段包括一个 ACK 槽位,和 ACK 界定符位。类似 I2C 总线,在 ACK 槽位中,发送节点发送的是隐性位,而接收节点则在这一位中发送显性位以示应答。在 ACK 槽和帧结束之间由 ACK 界定符间隔开。
- 帧结束,EOF 段 (End Of Frame),译为帧结束,帧结束段由发送节点发送的 7 个隐性位表示结束。
问题二:CAN初始化配置步骤?
- 配置相关引脚的复用功能,使能CAN时钟
- 设置CAN工作模式及波特率等
- 设置滤波器
问题三:CAN发送数据格式?
1 | |
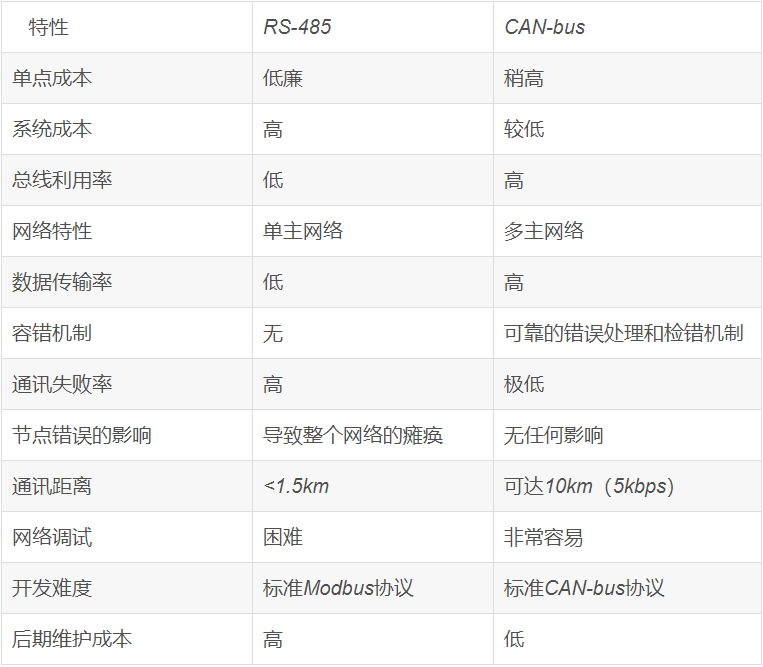
问题一:CAN总线与RS485的比较
- 速度与距离:CAN与RS485以1Mbit/S的高速率传输的距离都不超过100M,高速上的距离差不多。但在低速时CAN以5Kbit/S时,距离可达10KM,而485再低的速率也只能到1219米左右(都无中继)。
- 总线利用率:RS485是单主从结构,就是一个总线上只能有一台主机,通讯都由它发起的,它没有下命令,下面的节点不能发送,而且要发完即答,受到答复后,主机才向下一个节点询问,这样是为了防止多个节点向总线发送数据,而造成数据错乱。而CAN-bus是多主从结构,每个节点都有CAN控制器,多个节点发送时,以发送的ID号自动进行仲裁,这样就可以实现总线数据不错乱,而且一个节点发完,另一个节点可以探测到总线空闲,而马上发送,这样省去了主机的询问,提高了总线利用率,增强了快速性。所以在汽车等实性要求高的系统,都是用CAN总线,或者其他类似的总线。
- 错误检测机制,RS485只规定了物理层,而没有数据链路层,所以它对错误是无法识别的,除非一些短路等物理错误。这样容易造成一个节点破坏了,拼命向总线发数据(一直发1),这样造成整个总线瘫痪。所以RS485一旦坏一个节点,这个总线网络都挂。而CAN总线有CAN控制器,可以对总线任何错误进行检测,如果自身错误超过128个,就自动闭锁。保护总线。如果检测到其他节点错误或者自身错误,都会向总线发送错误帧,来提示其他节点,这个数据是错误的。大家小心。这样CAN总线一旦有一个节点CPU程序跑飞了,它的控制器自动闭锁。保护总线。所以在安全性要求高的网路,CAN是很强的。
- CAN具有完善的通信协议,可由CAN控制器芯片及其接口芯片来实现,从而大大降低了系统的开发难度,缩短了开发周期,这些是只仅仅有电气协议的RS-485所无法比拟的。
五、DMA
问题一:DMA介绍?
直接存储器存取(DMA) 用来提供在外设和存储器之间或者存储器和存储器之间的高速数据传输。无须CPU干预,数据可以通过DMA快速地移动,这就节省了CPU的资源来做其他操作。
问题一:DMA传输模式有几种?
DMA_Mode_Circular 循环模式
DMA_Mode_Normal 正常缓存模式
应用场景:GPS、蓝牙,都是用的循环采集,DMA_Mode_Circular模式。
————————————————
版权声明:本文为CSDN博主「聚优致成」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_29350001/article/details/116021595
六、中断
问题:什么时中断,中断处理方式?
中断是指在计算机运行期间,系統內發生非尋常的或急需處理的事件,使得CPU暂时中断当前正在執行的程序而转去執行相应的事件处理程序。待处理完毕后又返回原來被中断处继续执行得过程
步驟:
- 暫停目前process的進行,並將執行狀況儲存起來
- 根據interrupt id 找尋 interrupt vector,取得interrupt service routine(中断处理程序)的起始地址
- 執行ISR
- 執行完ISR後,回到中斷前的執行進度
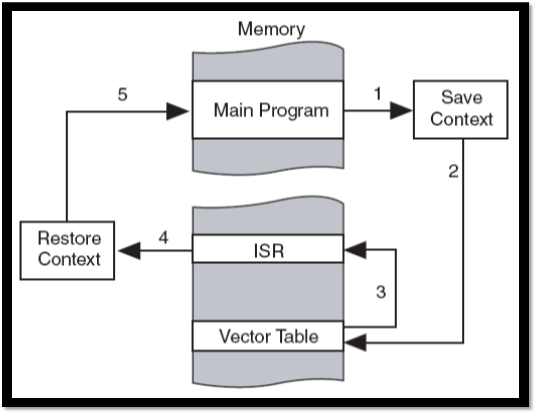
中断处理程序注意事项:
- ISR不能有返回值;
- ISR不能传递參數;
- ISR應該是短而高效的,在ISR中做浮点运算是不明智的;
- ISR中不應該有重入和性能上的問題,因此不應該使用printf()函數。浮点一般都是不可重入的
问题一:描述一下中断的处理流程?
(1)初始化中断,设置触发方式是上升沿/下降沿/双沿触发。
(2)触发中断,进入中断服务函数
问题二:STM32的中断控制器支持多少个外部中断?
STM32的中断控制器支持19个外部中断/事件请求:
从图上来看,GPIO 的管脚 GPIOx.0~GPIOx.15(x=A,B,C,D,E,F,G)分别对应中断线 0 ~ 15。
另外四个EXTI线的连接方式如下:
● EXTI线16连接到PVD输出
● EXTI线17连接到RTC闹钟事件
● EXTI线18连接到USB唤醒事件
● EXTI线19连接到以太网唤醒事件(只适用于互联型产品)
中断服务函数列表:
IO口外部中断在中断向量表中只分配了7个中断向量,也就是只能使用7个中断服务函数。
EXTI0_IRQHandler
EXTI1_IRQHandler
EXTI2_IRQHandler
EXTI3_IRQHandler
EXTI4_IRQHandler
EXTI9_5_IRQHandler
EXTI15_10_IRQHandler
————————————————
版权声明:本文为CSDN博主「聚优致成」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_29350001/article/details/116021595
七、时钟系统
问题一:STM32有几个时钟源?
STM32 有5个时钟源:HSI、HSE、LSI、LSE、PLL。
①、HSI是高速内部时钟,RC振荡器,频率为8MHz,精度不高。
②、HSE是高速外部时钟,可接石英/陶瓷谐振器,或者接外部时钟源,频率范围为4MHz16MHz。16倍,但是其输出频率最大不得超过72MHz。
③、LSI是低速内部时钟,RC振荡器,频率为40kHz,提供低功耗时钟。
④、LSE是低速外部时钟,接频率为32.768kHz的石英晶体。
⑤、PLL为锁相环倍频输出,其时钟输入源可选择为HSI/2、HSE或者HSE/2。倍频可选择为2
————————————————
版权声明:本文为CSDN博主「聚优致成」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_29350001/article/details/116021595
ADC
问题一:简述STM32的ADC系统的功能特性?
(1)12bit分辨率
(2)自动校准
(3)可编程数据对齐(转换结果支持左对齐或右对齐方式存储在16位数据寄存器)
(4)单次和连续转换模式
定时器
问题:
问题一:已知STM32的系统时钟为72MHz,如何设置相关寄存器,实现20ms定时?
解答:
参看:STM32开发 – Systick定时器
通过SysTick_Config(SystemCoreClock / OS_TICKS_PER_SEC))//1ms定时器
其中:
uint32_t SystemCoreClock = SYSCLK_FREQ_72MHz; /!< System Clock Frequency (Core Clock) /
#define SYSCLK_FREQ_72MHz 72000000
#define OS_TICKS_PER_SEC 1000 / Set the number of ticks in one second
1
2
3
如果需要20ms则,可以通一设置一个全局变量,然后定初值得为20,这样,每个systick中断一次,这个全局变量减1,减到0,即systick中断20次,时间为:1ms20=20ms。从而实现20ms的定时。
————————————————
版权声明:本文为CSDN博主「聚优致成」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_29350001/article/details/116021595
HardFault_Handler处理
问题一:造成原因?
(1)数组越界操作;
(2)内存溢出,访问越界;
(3)堆栈溢出,程序跑飞;
(4)中断处理错误;
问题二:处理方式?
(1)在startup_stm32f10x_cl.s里找到HardFault_Handler的地址重映射,并重新编写,让其跳转到HardFaultHandle函数。
(2)打印查看R0、R1、R2、R3、R12、LR、PC、PSR寄存器。
(3) 查看Fault状态寄存器组(SCB->CFSR和SCB->HFSR)
————————————————
版权声明:本文为CSDN博主「聚优致成」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_29350001/article/details/116021595
低功耗模式
问题一:低功耗模式有几种?唤醒方式是什么?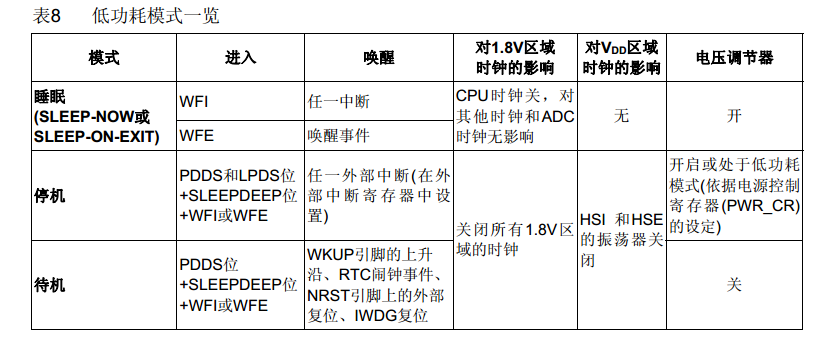
八、协议
Modbus
FreeRTOS
uCOSII
UCOSII任务调度
问题:
问题一:RTOS的任务是怎么写的?如何切出这个任务?
解答:
一个任务,也称作一个线程。
UCOS有一个任务调度机制,根据任务的优先级进行调度。
一个是硬件中断, 那么系统会将当前任务有关变量入栈,然后执行中断服务程序,执行完成后出栈返回.
另一个是任务之间的切换,使用的方法就是任务调度,每一个任务有自己的栈,顺度也是一样的入栈,然后执行另一个程序,然后出线返回。
并非是每一任务按优先级顺序轮流执行的,而是高优先级的任务独占运行,除非其主动放弃执行,否则低优先级任务不能抢占,同时高优先级可以把放出去给低优先级任务使用的CPU占用权抢回来。所以ucos的任务间要注意插入等待延时,以便ucos切出去让低优先级任务执行。
十二、UCOSII中任务间的通信
问题:
问题一:UCOSII中任务间的通信方式有哪几种?
解答:
在UCOSII中,是使用信号量、邮箱(消息邮箱)和消息队列这些被称作事件的中间环节来实现任务间的通信的,还有全局变量。
信号量:
参看:ucosII 信号量使用总结(举例讲解)
信号量用于:
1.控制共享资源的使用权(满足互斥条件)
2.标志某时间的发生
3.使2个任务的行为同步
应用实例:互斥信号量
作为互斥条件,信号量初始化为1。
实现目标:调用串口发送命令,必须等待返回“OK”字符过后,才能发送下一条命令。每个任务都有可能使用到此发送函数,不能出现冲突!
邮箱(消息邮箱):
消息队列:
概念:
(1)消息队列实际上就是邮箱阵列。
(2)任务和中断都可以将一则消息放入队列中,任务可以从消息队列中获取消息。
(3)先进入队列的消息先传给任务(FIFO)。
(4)每个消息队列有一张等待消息任务的等待列表,如果消息列中没有消息,则等待消息的任务就被挂起,直到消息到来。
应用场景:
串口接收程序中的接收缓冲区。
储存外部事件。
————————————————
版权声明:本文为CSDN博主「聚优致成」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_29350001/article/details/116021595