嵌入式面试-C语言再学习
本文最后更新于:2023年2月22日 晚上
一、GCC编译过程
此章节内容需要一定ubuntu和Linux知识
一、GCC简介:
gcc的原名叫做GNU C语言 编译器(GNU C Compile),只能编译C语言程序,后来很快就做了扩展,支持了更多的编程语言,比如C+ Object-c …,改名为GNC 编译器 套件(GNU Compile Collection) 支持很多的硬件和操作系统。
二、编译过程
C语言的编译过程可分为四个阶段:预处理->>编译->>汇编->>链接
下面以hello.c为示例详细介绍各个编译过程:
1 | |
1、预处理
预编译过程主要处理那些源代码中以#开始的预编译指令,主要处理规则如下:
1)将所有的#define删除,并且展开所有的宏定义;
2)处理所有条件编译指令,如#if,#ifdef等;
3)处理#include预编译指令,将被包含的文件插入到该预编译指令的位置。该过程递归进行,及被包含的文件可能还包含其他文件。
4)删除所有的注释//和 /**/;
5)添加行号和文件标识,如#2 “hello.c” 2,以便于编译时编译器产生调试用的行号信息及用于编译时产生编译错误或警告时能够显示行号信息;
6)保留所有的#pragma编译器指令,因为编译器须要使用它们;
命令:
gcc -E hello.c -o hello.i
得到一个.i为后缀的预处理之后的文件,该文件叫做预处理文件,以下为预处理后的输出文件hello.i的内容:
1 | |
2、编译
编译过程就是把预处理完的文件进行一系列词法分析,语法分析,语义分析及优化后生成相应的汇编代码文件。
命令:
gcc -S hello.i -o hello.s
得到一个.s为后缀的汇编文件,以下为编译后的输出文件hello.s的内容:
1 | |
3、汇编
汇编器是将汇编代码转变成机器可以执行的命令,每一个汇编语句几乎都对应一条机器指令。汇编相对于编译过程比较简单,根据汇编指令和机器指令的对照表一一翻译即可。
命令:
gcc –c hello.s –o hello.o
得到一个.o为后缀的目标文件,由于hello.o的内容为机器码,不能以文本形式方便的呈现。可用命令hexdump hello.o 打开。
4、链接
目标代码不能直接执行,要想将目标代码变成可执行程序,还需要进行链接操作。才会生成真正可以执行的可执行程序。链接操作最重要的步骤就是将函数库中相应的代码组合到目标文件中。
命令:
gcc hello.o -o hello
实现链接的处理,默认生成可执行文件 a.out,可以通过 -o来指定输出文件名。
使用ld指令
ld -static crt1.o crti.o crtbeginT.o hello.o -start -group -lgcc -lgcc_eh -lc -end-group crtend.o crtn.o (省略了文件的路径名)
连接的过程包括按序叠加、相似段合并、符号地址的确定、符号解析与重定位、指令修正、全局构造与解析等等
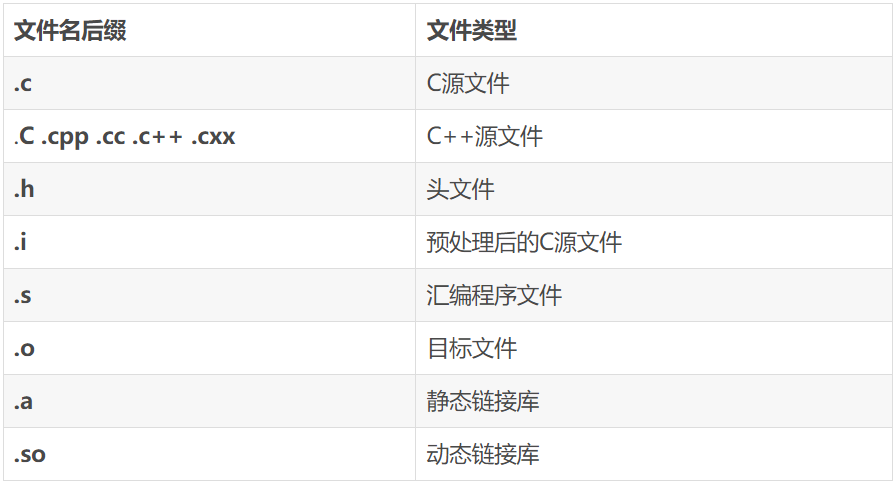
三、文件名后缀
二、注释
C语言注释有三种情况
- 单行注释:
// - 多行注释:
/* */ - #if0/1注释:
#if 0 #endif 和 #if 1 #endif
注意:注释不能嵌套,第一个 /* 符号和第一个 / 符号之间的内容都被看做是注释,不管里面还有多少个 / 符号/* hello world! /*I love you*/ */
看下面的语句:y = x/*p /* p指向除数 */
本意似乎是用 x 除以 p 所指向的值,把所得的商再赋给 y。而实际上, /* 被编译器理解为一段注释的开始,编译器将不断地读入字符,直到 */ 出现为止。也就是说,该语句直接将 x 的值赋给了 y,根本不会顾及后面出现的 p。将上面的语句重写如下:y = x / *p /* p指向除数 */
或者更加清楚一点,写作:y = x / (*p) /* p指向除数 */
面试题:
1 | |
int 定义,/*...*/ 看作注释,语句正确//efg 不是注释,是字符串中的一段字符串,语句正确\ 是反斜杠换行,等同于//hello world!,语句正确//in/*...*/t i; 是单行注释,语句正确
三、声明与定义
么是定义?什么是声明?它们有何区别?举个例子:
A) int i;
B) extern int i; (关于 extern,后面解释)
哪个是定义?哪个是声明?或者都是定义或者都是声明?我所教过的学生几乎没有一人能回答上这个问题。这个十分重要的概念在大学里从来没有被提起过!
什么是定义:所谓的定义就是(编译器)创建一个对象,为这个对象分配一块内存并给它取上一个名字,这个名字就是我们经常所说的变量名或对象名。但注意,这个名字一旦和这块内存匹配起来(可以想象是这个名字嫁给了这块空间,没有要彩礼啊。 ^_^),它们就同生共死,终生不离不弃。并且这块内存的位置也不能被改变。一个变量或对象在一定的区域内(比如函数内,全局等)只能被定义一次,如果定义多次,编译器会提示你重复定义同一个变量或对象。
什么是声明:有两重含义,如下:
- 第一重含义:告诉编译器,这个名字已经匹配到一块内存上了(伊人已嫁,吾将何去何从?何以解忧,唯有稀粥),下面的代码用到变量或对象是在别的地方定义的。声明可以出现多次。
- 第二重含义:告诉编译器,我这个名字我先预定了,别的地方再也不能用它来作为变量名或对象名。比如你在图书馆自习室的某个座位上放了一本书,表明这个座位已经有人预订,别人再也不允许使用这个座位。其实这个时候你本人并没有坐在这个座位上。这种声明最典型的例子就是函数参数的声明,例如:
void fun(int i, char c);
好,这样一解释,我们可以很清楚的判断:A)是定义; B)是声明。
那他们的区别也很清晰了。记住, 定义声明最重要的区别:定义创建了对象并为这个对象分配了内存,声明没有分配内存(一个抱伊人,一个喝稀粥。 ^_^)。
声明(declaration )指定了一个变量的标识符,用来描述变量的类型,是类型还是对象,或者函数等。声明,用于编译器(compiler)识别变量名所引用的实体。以下这些就是声明:
1 | |
定义是对声明的实现或者实例化。连接器(linker)需要它(定义)来引用内存实体。与上面的声明相应的定义如下:
1 | |
无论如何,定义 操作是只能做一次的。如果你忘了定义一些你已经声明过的变量,或者在某些地方被引用到的变量,那么,连接器linker是不知道这些引用该连接到那块内存上的。然后就会报missing symbols 这样的错误。如果你定义变量超过一次,连接器是不知道把引用和哪块内存连接,然后就会报 duplicated symbols这样的错误了。以上的symbols其实就是指定义后的变量名,也就是其标识的内存块。
总结:
如果只是为了给编译器提供引用标识,让编译器能够知道有这个引用,能用这个引用来引用某个实体(但没有为实体分配具体内存块的过程)是为声明。如果该操作能够为引用指定一块特定的内存,使得该引用能够在link阶段唯一正确地对应一块内存,这样的操作是为定义。
声明是为了让编译器正确处理对声明变量和函数的引用。定义是一个给变量分配内存的过程,或者是说明一个函数具体干什么用。
四、标识符
标识符由字母(A-Z,a-z)、数字(0-9)、下划线“_”组成,并且首字符不能是数字,但可以是字母或者下划线。例如,正确的标识符:abc,a1,prog_to。
不能把 C语言关键字作为用户标识符,例如if ,for, while等.
标识符长度是由机器上的编译系统决定的,一般的限制为8字符(注:8字符长度限制是C89标准,C99标准已经扩充长度,其实大部分工业标准都更长)。
标识符对大小写敏感,即严格区分大小写。一般对变量名用小写,符号常量命名用大写。
标识符命名应做到 “见名知意 ”,例如,长度( 外语:length),求和、总计( 外语:sum),圆周率( 外语:pi)……
C语言中把标识符分为三类: 关键字, 预定义标识符(库名、系统常量、系统函数),用户自定义标识符 [1] 。
五、转义字符
| 转义字符 | 意义 | ASCLL码值(十进制) |
|---|---|---|
| \a | 响铃(BEL) | 007 |
| \b | 退格(BS) ,将当前位置移到前一列 | 008 |
| \f | 换页(FF),将当前位置移到下页开头 | 012 |
| \n | 换行(LF) ,将当前位置移到下一行开头 | 010 |
| \r | 回车(CR) ,将当前位置移到本行开头 | 013 |
| \t | 水平制表(HT) (跳到下一个TAB位置) | 009 |
| \v | 垂直制表(VT) | 011 |
| ' | 代表一个单引号 | 039 |
| " | 代表一个双引号字符 | 034 |
| |代表一个反斜线字符’’’ | 092 | |
| ? | 代表一个问号 | 063 |
| \0 | 空字符(NUL) | 000 |
| \ddd | 1到3位八进制数所代表的任意字符 | 三位八进制 |
| \xhh | 十六进制所代表的任意字符 | 十六进制 |
\n和\t是最常用的两个转义字符:
- \n用来换行,让文本从下一行的开头输出,前面的章节中已经多次使用;
- \t用来占位,一般相当于四个空格,或者 tab 键的功能。
- \xhh 十六进制转义不限制字符个数 ‘\x000000000000F’ == ‘\xF’
单引号、双引号、反斜杠是特殊的字符,不能直接表示:
- 单引号是字符类型的开头和结尾,要使用'表示,也即’'‘;
- 双引号是字符串的开头和结尾,要使用"表示,也即”abc"123”;
- 反斜杠是转义字符的开头,要使用\表示,也即’\‘,或者”abc\123”。
六、浮点数
参考:
你应该知道的浮点数基础知识
浮点数的表示
浮点数的表示和基本运算
单精度浮点float:可以精确到小数点后6位
双精度浮点double:可以精确到小数点后12位
C可以通过f或F后缀是编译器把浮点常量当做float类型,比如2.3f和9.11E9F。
l或L后缀使一个数字成为long double类型,比如54.3l和4.32e4L。
建议使用L后缀,因为字母l和数字1容易混淆
没有后缀的浮点常量为double类型。(重点)。例:sizeof(1.9) = 8;
数据类型和占位符之间的对应关系:
float %f/%g
double %lf/%lg
%f和%lf会保留小数点后面多余的0 如 3.1400000 .2%f得 3.14
%g和%lg不会保留 如 3.14
在浮点数比较中不能使用<和>,千万要留意,无论是float还是double类型的变量,都有精度限制。所以一定要避免将浮点变量用“==”或“!=”与数字比较,应该设法转化成“>=”或“<=”形式。
请写出 float x与“零值”比较的if语句
1 | |
或者
1 | |
七、关键字sizeof与strlen
sizeof
一、简单介绍
sizeof 是 C 语言的一种单目操作符,如 C 语言的其他操作符++、–等。它并不是函数。C 规定 sizeof 返回 sieze_t 类型的值。这是一个无符号整数类型。C99更进一步,把%zd 作为用来显示 size_t 类型值的 printf() 说明符。如果你的系统没有实现 %zd,你可以试着使用 %u 或者 %lu 代替它。
sizeof 操作符以字节形式给出了其操作数的存储大小。操作数可以是一个表达式或括在括号内的类型名。操作数的存储大小由操作数的类型决定。
二、使用方法
1、用于数据类型
sizeof 使用形式: sizeof (type)
数据类型必须用圆括号括住。如:sizeof (int)
2、用于变量
sizeof 使用形式:sizeof (var_name) 或 sizeof var_name
变量名可以不用圆括号括住。如:sizeof (6.08) 或 sizeof 6.08 等都是正确的形式。带括号的用法更普遍,大多数程序员采用这种形式。
注意:sizeof 操作符不能用于函数类型,不完全类型和位字段。不完全类型指具有未知存储大小的数据类型,如未知存储大小的数组类型、未知内容的结构或联合类型、void类型等。如:
sizeof (max) 若此时变量 max 定义为 int max ( ),
sizeof (char_v) 若此时 char_v 定义为 char char_v [MAX] 且 MAX 未知
sizeof (void)
上述例子,都是不正确的形式。
3、sizeof 的结果
sizeof 操作符的结果类型是 size_t,它在头文件中 typedef 为 unsigned int 类型。该类型保证能容纳实现所建立的最大对象的字节大小。
在windows,32位系统中
char 1个字节
short 2个字节
int 4个字节
long 4个字节
double 8个字节
float 4个字节看看这三个分别是什么?
1,‘ 1‘,“ 1”。
第一个是整形常数, 32 位系统下占 4 个 byte;
第二个是字符常量,占 1 个 byte;
第三个是字符串常量,占 2 个 byte。
三者表示的意义完全不一样,所占的内存大小也不一样,初学者往往弄错。
当操作数为指针时,sizeof 依赖于编译器。一般unix的指针为 4个字节
1
2
3
4
5
6
7
8
9#include <stdio.h>
int main (void)
{
char ptr[] = "hello";
char *str = ptr;
printf ("sizeof (str) = %d\n", sizeof (str));
return 0;
}输出结果:
sizeof (str) = 4
在 32 位系统下,不管什么样的指针类型,其大小都为 4 byte。可以测试一下 sizeof( void *)。当操作数具有数组类型时,其结果是数组的总字节数
1
2
3
4
5
6
7
8#include <stdio.h>
int main (void)
{
int ptr[20] = {1,2,3,4,5};
printf ("sizeof (ptr) = %d\n", sizeof (ptr));
return 0;
}输出结果:
sizeof (ptr) = 80联合类型操作数的 sizeof 是其最大字节成员的字节数,结构体类型操作数的sizeof,需要考虑内存对齐补齐。
1 | |
输出结果:sizeof (UN) is 4
结构体内存对齐与补齐
- 一个存储区的地址一定是它自身大小的整数倍(双精度浮点类型的地址只需要4的整数倍就行了),这个规则也叫数据对齐,结构体内部的每个存储区通常也需要遵守这个规则。数据对齐可能造成结构体内部存储区之间有浪费的字节。
结构体的大小一定是内部最大基本类型存储区大小的整数倍,这个规则叫数据补齐。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15#include <stdio.h>
typedef struct
{
char ch;
int num;
char ch1;
}str;
int main (void)
{
printf ("sizeof (str) is %d\n", sizeof (str));
return 0;
}
输出结果:
sizeof (str) is 12
- 如果操作数是函数中的数组形参或函数类型的形参,sizeof给出其指针的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16#include <stdio.h>
char ca[10];
void foo (char ca[100])
{
printf ("sizeof (ca) = %d\n", sizeof (ca));
}
int main (void)
{
char ca [25];
foo (ca);
return 0;
}
输出结果:
sizeof (ca) = 4
三、主要用途
1、sizeof操作符的一个主要用途是与存储分配和I/O系统那样的例程进行通信。例如:
void *malloc(size_t size), size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream)
2、sizeof的另一个的主要用途是计算数组中元素的个数。例如:void *memset(void *s,int c,sizeof(s))
3.在动态分配一对象时,可以让系统知道要分配多少内存。如:int *p=(int *)malloc(sizeof(int)*10);
4.由于操作数的字节数在实现时可能出现变化,建议在涉及到操作数字节大小时用sizeof来代替常量计算。
5.如果操作数是函数中的数组形参或函数类型的形参,sizeof给出其指针的大小。
四、注意的地方
1、在混合类型的算术运算的情况下,较小的类型被转换成较大的类型。反之,可能会丢失数据。
1 | |
2、判断表达式的长度并不需要对表达式进行求值
1 | |
所以sizeof (b = a + 12)并没有向 a 赋任何值。
strlen
strlen首先是一个函数,只能以char * 做参数,返回的是字符的实际长度,不是类型占内存的大小。其结果是运行的时候才计算出来的。
1 | |
函数功能:用来统计字符串中有效字符的个数
功能实现函数:
1 | |
strlen()函数被用作改变字符串长度,例如:
1 | |
可以看出:fit()函数在数组的第8个元素中放置了一个’\0’字符来代替原有的o字符。puts()函数输出停在o字符处,忽略了数组的其他元素。然而,数组的其他元素仍然存在。
sizeof 与 strlen 的区别
参看:C语言再学习 – 字符串和字符串函数
谈两者的区别之前,先要讲一下什么是字符串,字符串就是一串零个或多个字符,并且以一个位模式为全 0 的 ‘\0’ 字节结尾。如在代码中写 “abc”,那么编译器帮你存储的是 “abc\0”。
siezeof运算符提供给你的数目比strlen大1,这是因为它把用来标志字符串结束的不可见的空字符(’\0’)也计算在内。
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int main (void)
{
char *str1 = “abcde”;
char str2[] = “abcde”;
char str3[8] = “abcde”;
char str4[] = {‘a’, ‘b’, ‘c’, ‘d’, ‘e’};
char *p1 = malloc (20);
printf ("sizeof (str1) = %d, strlen (str1) = %d\n", sizeof (str1), strlen (str1));
printf ("sizeof (*str1) = %d, strlen (str1) = %d\n", sizeof (*str1), strlen (str1));
printf ("sizeof (str2) = %d, strlen (str2) = %d\n", sizeof (str2), strlen (str2));
printf ("sizeof (str3) = %d, strlen (str3) = %d\n", sizeof (str3), strlen (str3));
printf ("sizeof (str4) = %d, strlen (str4) = %d\n", sizeof (str4), strlen (str4));
printf ("sizeof (p1) = %d, sizeof (*p1) = %d\n", sizeof (p1), sizeof (*p1));
printf ("sizeof (malloc(20)) = %d\n", sizeof (malloc (20)));
return 0;
}
输出结果:
sizeof (str1) = 4, strlen (str1) = 5
sizeof (*str1) = 1, strlen (str1) = 5
sizeof (str2) = 6, strlen (str2) = 5
sizeof (str3) = 8, strlen (str3) = 5
sizeof (str4) = 5, strlen (str4) = 5
sizeof (p1) = 4, sizeof (*p1) = 1
sizeof (malloc(20)) = 4
总结:
sizeof 操作符的结果类型是 size_t,它在头文件中typedef为 unsigned int 类型。该类型保证能容纳实现所建立的最大对象的字节大小。
sizeof 是算符,strlen 是函数。
sizeof可以用类型做参数,strlen只能用char*做参数,且必须是以’’\0’’结尾的。sizeof 还可以用函数做参数,比如:
1
2
3short f();
printf("%d\n",sizeof(f()));
输出的结果是sizeof(short),即2。数组做 sizeof 的参数不退化,传递给 strlen 就退化为指针了。
5.大部分编译程序 在编译的时候就把 sizeof 计算过了 是类型或是变量的长度这就是 sizeof(x) 可以用来定义数组维数的原因
1 | |
strlen 的结果要在运行的时候才能计算出来,是用来计算字符串的长度,不是类型占内存的大小。
sizeof 后如果是类型必须加括弧,如果是变量名可以不加括弧。这是因为sizeof是个操作符不是个函数。
当适用了于一个结构类型时或变量, sizeof 返回实际的大小,当适用一静态地空间数组, sizeof 归还全部数组的尺寸。sizeof 操作符不能返回动态地被分派了的数组或外部的数组的尺寸。
数组作为参数传给函数时传的是指针而不是数组,传递的是数组的首地址,如:
1
2fun(char [8])
fun(char [])都等价于 fun(char *)
在C++里参数传递数组永远都是传递指向数组首元素的指针,编译器不知道数组的大小如果想在函数内知道数组的大小, 需要这样做:进入函数后用memcpy拷贝出来,长度由另一个形参传进去1
2
3
4
5fun(unsiged char*p1, int len)
{
unsigned char* buf= new unsigned char[len+1]
memcpy(buf, p1,len);
}
我们能常在用到 sizeof 和 strlen 的时候,通常是计算字符串数组的长度看了上面的详细解释,发现两者的使用还是有区别的,从这个例子可以看得很清楚:
1 | |
上面是对静态数组处理的结果,如果是对指针,结果就不一样了
1 | |
面试题:
1、sizeof( int) *p 表示什么意思?
需要明白 sizeof 后跟数据类型,必须要用圆括号括住的,强制类型转换也应该是 (int*) p,所以这句话所表达的意思是 sizeof (int) 乘以 p
1 | |
1 | |
2、在 32 位系统下:
1 | |
sizeof(p)的值是多少?
sizeof(*p)呢?
sizeof (p) = 4; 因为 p为指针,32位系统 指针所占字节为 4个字节
sizeof (*p) = 4; 因为 *p 为 指针所指向的变量为int类型,整型为 4个字节
1 | |
3、int a[100];
sizeof (a) 的值是多少?
sizeof(a[100])呢? //请尤其注意本例。
sizeof(&a)呢?
sizeof(&a[0])呢?
sizeof (a) = 400; 因为 a是类型为整型、有100个元素的数组,所占内存为400个字节
sizeof (a[100]) = 4; 因为 a[100] 为数组的第100元素的值该值为 int 类型,所占内存为4个字节。
sizeof (&a) = 4; 因为 &a 为数组的地址即指针,32位系统 指针所占字节为 4个字节
sizeof (&a[0]) = 4; 因为&a[0] 为数组的首元素的地址即指针,32位系统 指针所占字节为 4个字节
1 | |
4、
1 | |
sizeof (b) = 4; 因为函数中的数组形参或函数类型的形参,sizeof给出其指针的大小。参数传递数组永远都是传递指向数组首元素的指针。
1 | |
1 | |
printf、scanf占位符
一、printf()
printf()的返回值为输出的字符个数:
例:rv = printf (“hello”); 结果为rv = 5;
其格式控制如下列表所述:
表一、printf()格式转换说明符
| 转换说明 | 输出 |
|---|---|
| %a | 浮点数、十六进制数和p-记数法(C99) |
| %A | 浮点数、十六进制数和p-记数法(C99) |
| %c | 一个字符 |
| %d | 有符号十进制整数 |
| %e | 浮点数、e-记数法 |
| %E | 浮点数、E-记数法 |
| %f | 浮点数、十进制记数法 |
| %g | 根据数值不同自动选择%f或%e。%e格式在指数小于-4或者大于等于精度时使用 |
| %G | 根据数值不同自动选择%f或%E。%E格式在指数小于-4或者大于等于精度时使用 |
| %i | 有符号十进制整数(与%d相同) |
| %o | 无符号八进制整数 |
| %p | 指针 |
| %s | 字符串 |
| %u | 无符号十进制整数 |
| %x | 使用十六进制数字0f的无符号十六进制整数 |
| %X | 使用十六进制数字0F的无符号十六进制整数 |
| %% | 打印一个百分号 |
表二、printf()格式转换修饰符
| 修饰 | 意义 |
|---|---|
| 标志 | 五种标志(-、+、空格、#、0)详细说明见表三。可以使用零个或者多个 。例:“%-10d” |
| digit 或* | 字段宽度的最小值。如果该字段不能容纳要打印的数或者字符串,系统就会使用更宽的字段。当为 * 号时,表示从参数中获取宽度。例:“%4d”、printf(“%*d”, width, num) |
| .digit或 .* | 精度。对于%e、%E和%f转换,是将要在小数点的右边打印的数字的位数。对于%g和%G转换,是有效数字的最大位数。对于%s转换,是将要打印的字符的最大数目。对于整数转换,是将要打印的数字的最小位数,如果必要,要使用前导0来达到这个位数。只使用“.”和使用“.0”相同,所以%f与%.0f相同。当为 * 号时,表示从参数中获取精度。例:“%5.2f“、printf(“%5.*f”, precision, num) |
| h | 和整数转换说明符一起使用,表示一个short int 或 unsigned short int类型数值。例:”%hu“、”%hx“、”%6.4hd“ |
| hh | 和整数转换说明符一起使用,表示一个char 或 unsigned char类型数值。例:”%hhu“、”%hhx“、”%6.4hhd“ |
| j | 和整数转换说明符一起使用,表示一个intmax_t或uintmax_t值。例:”%jd“、”%8jx“ |
| l | 和整数转换说明符一起使用,表示一个long nt 或 unsigned long int类型数值。例:”%ld“、”%8lu“ |
| ll | 和整数转换说明符一起使用,表示一个long long int 或 unsigned long long int类型数值(C99)。例:”%lld“、”%llu“ |
| L | 和浮点转换说明符一起使用,表示一个long double值。例:”%Lf“、”%10.4Le“ |
| t | 和整数转换说明符一起使用,表示一个ptrdiff_t值(与两个指针之间的差相对应的类型)(C99)。例:”%td“、”%12ti“ |
| z | 和整数转换说明符一起使用,表示一个size_t值(C99)。例:”%zd”、“%12zx” |
表三、printf()格式转换修饰标志
| 标志 | 意义 |
|---|---|
| - | 项目是左对齐的。例:“%-4s” |
| + | 有符号的值若为正,则显示正号;若为负的,则显示负号。例:“%+6.2f” |
| 空格 | 有符号的值若为正,则显示空格代替正号;若为负的,则显示负号。例:“% 6.2f“ |
| # | 使用转换说明的可选形式。若为%o格式,显示前导0;若为%x和%X格式,则显示前导0x和0X。对于所有浮点形式,#保证了即使不跟任何数字,也打印一个小数点字符。对于%g和%G格式,它防止尾随零被删除。。例:”%#o“、”%#x“、”%#8.0f“、”%+#10.3E“ |
| 0 | 对于所有的数字格式,用前导0来填充字段宽度,如果出现-标志或者指定了精度(对于整数)则忽略该标志。例:”%010d“、”%08.3f“ |
二、scanf()
scanf() 开始读取输入以后,会在遇到的第一个空白制度空格(bank)、制表符(tab)或者换行符(newline)处停止读取。
表四、scanf()格式转换说明符
| 转换说明符 | 意义 |
|---|---|
| %c | 把输入解释成一个字符 |
| %d | 把输入解释成一个有符号十进制整数 |
| %e、%f、%g、%a | 把输入解释成一个浮点数(%a是C99标准) |
| %E、%F、%G、%A | 把输入解释成一个浮点数(%A是C99标准) |
| %i | 把输入解释成一个有符号十进制整数 |
| %o | 把输入解释成一个有符号八进制整数 |
| %p | 把输入解释成一个指针(一个地址) |
| %s | 把输入解释成一个字符串:输入的内容以第一个非空白字符作为开始,至下一个空白字符之前的全部字符 |
| %u | 把输入解释成一个无符号十进制整数 |
| %x、%X | 把输入解释成一个无符号十六进制整数 |
scanf()格式转换修饰符
表五、scanf()格式转换修饰符
| 修饰符 | 意义 |
|---|---|
| * | 忽略一个输入项。例:scanf(“%*d%d”, &num), 当输入为 23 45时,23将被忽略,而读取45到num中 |
| digit | 最大字段宽度。在达到最大字段宽度或遇到第一个空白字符时停止对输入项的读取 |
| hh | 指示整数将会存储在char 或 unsigned char |
| ll | 指示整数将会存储在 long long 或者 unsigned long long (C99) |
| h、l、L | ”%hd“和”%hi“指示该值将会存储在一个short int中。”%ho“、”%hx“”%hu“指示该值将会存储在一个unsigned short int中。”%ld“和”%li“指示该值将存储在一个long中。”%lo“、”lx“、”lu“指示该值将会存储在一个unsigned long中。”%le“、”%lf“、”%lg“指示该值将会存储在double中。将L与e、f、g一起使用指示该值将会存储在long double中。如果没有这些修饰符,d、i、o、x指示int类型,e、f、g指示float类型 |
| 空格 | 只能修饰 %c , 忽略输入的前导空白字符 |
对于scanf()除了%c以外,对每一个输入项忽略其前导空白字符(空格、制表符、换行符)。从第一个非空白字符开始,直到遇到空白字符或达到宽度或遇到当前输入格式的非法字符时停止当前项输入,进入下一输入项
简单总结:
数据类型和占位符之间的对应关系
char和unsingned char %c
short %hd
unsigned short %hu
long %ld
unsigned long %lu
int %d
unsigned int %u
float %f/%g
double %lf/%lg
%f和%lf会保留小数点后面多余的0 如 3.1400000 .2%f得 3.14
%g和%lg不会保留 如 3.14
%02d 两位数,如果不够前面补0, 如 02
分支与跳转语句
一、if语句
关于if语句形式2分析:
如果希望在if和else之间有多条语句,必须使用花括号创建一个代码块。下面的结构违反了C语法,因为编译器期望if和else之间只有一条语句。
1 | |
编译器会把printf()语句看作if语句的部分,将x++语句看作一条单独的语句,而不把它作为if语句的一部分。然后会认为else没有所属的if,这是个错误,应该使用花括号。或者参看do while (0)语句。
1 | |
判断条件通常是一个关系表达式,也就是用一个关系运算符构成的表达式,例如:< 或者 ==。利用C的逻辑运算符,可以作何多个关系表达式以创建更复杂的判断。
需要注意的几点:
1、赋值运算符和逻辑运算符
例如:
1 | |
2、 if(n != 0)可用if (n)代替
3、if (n >= 9 && n <= 100) 不要写成 if (90 <= n <= 100)
问题在于该代码是语义错误,不是语法错误,因为对于<=运算符的求值顺序是由左到右的,所以会把该测试表达式解释为如下形式:
1 | |
子表达式90 <= n的值为1(真)或0(假)。任何一个值都小于100,因此不管n的值是什么,整个表达式总是为真,所以需要使用&&来检查范围。
例如: if (5 > 2 > 3) 布尔值为0(假).
注意: 零值表示“假”,非零值表示“真”,负数也是非零值。
1 | |
二、循环辅助手段:continue和break
1、continue语句
continue命令可以与三种循环形式中的任何一种一起作用,但是不能和switch语句一起使用。他导致程序控制跳过循环中的剩余语句。对于while和for循环,开始下一个循环周期。对于do while循环,对退出条件进行判断,如果必要,开始下一个循环周期。
用处:可以在主语语句中消除一级缩排。当语句很长或者已经有很深的嵌套时,作为占位符,使代码根据可读性:
while (getchar () != ‘\n’)
continue;
2、break语句
循环中的break语句导致程序终止包含它的循环,并进行程序的下一阶段。break命令可以与三种循环形式中的任何一种以及switch语句一起使用。它导致程序控制跳过包含它的循环或switch语句的剩余部分,继续执行紧跟在循环或switch后的下一条命令。
break语句实质上是switch语句的附属物,顺便提一下,break语句用于循环和switch中,而continue仅用于循环。
例如:在if语句中使用continue会出现: 错误:continue语句出现在循环以外。
三、多重选择:switch和break
以上面的例子来说明switch语句:
如果i为整形值1或者2,则打印22222。如果它的值为3,则打印33333和44444(因为杂case 3后没有break语句,所以流程继续到随后的语句),如果它的值为4,则打印44444,。对于其他值,仅打印hello world
1 | |
总体注解:
程序控制按照逻辑表达式的值跳转到相应的case标签处。然后程序流程继续通过所有剩余的语句,直达再次由break语句重定向。逻辑表达式和case标签必须都是整型值(包括类型char),并且标签必须是常量或者完全有常量组成的表达式。如果没有表达式值相匹配的case标签,那么控制定位到标签为default的语句,如果它存在的话。否则,控制传递给紧跟着switch语句的下一条语句。
每个 switch 语句中只能出现一条 default 子句。但是,它可以出现在语句列表的任何位置,而且语句流会像贯穿一个 case 标签一样贯穿 default 子句。
四、goto语句
不要轻易使用
可以了解一下:
while(1)、for( ; ; )、goto这三者可作为死循环
输入/输出
一、缓冲区
输入字符的立即回显是非缓冲或直接输入的一个实例,它表示你键入的字符被收集并存储在一个被称为缓冲区的临时存储区域中。按下回车可使你所键入的字符块对程序变成可用。
为什么需要缓冲区?首先,将若干个字符作为一个块传输比逐个发送这些字符耗费的时间少。其次,如果你输入有误,就可以使用你的键盘更正功能来修改错误。当最终按下回车键时,你就可以发送正确的输入。另一个方面,一些交互性的程序需要非缓冲收入。
缓冲分为两类,完全缓冲I/O和行缓冲I/O。对完全缓冲输入来说,缓冲区满时被清空(内容被发送至目的地)。这种类型的缓冲通常出现在文件输入中。缓冲区的大小取决于系统,但512字节和4096字节是常见的值。对行缓冲I/O来说,遇到一个换行符时将被清空缓冲区。键盘输入时标准的行缓冲,因此按下回车键将清空缓冲区。
当输入函数检测到已经读取了缓冲区中的全部字符时,它会请求系统将下一块缓冲区大小的数据复制到缓冲区,通过这种方式,输入函数可以读入文件中的全部内容,直到文件结尾。函数在读入最后以缓冲区数据中的最后一个字符后,会将文件结尾指示器的值设置为真。于是下一个被调用的输入函数将返回EOF。
以类似的方式,输出函数将数据写入缓冲区,当缓冲区以满时,就将数据复制到文件中。
缓冲区相关函数:
1、ungetc ( ) 函数
函数原型:
int ungetc(int char, FILE *stream)
参数:
char – 这是要被推入的字符。该字符以其对应的 int 值进行传递。
stream – 这是指向 FILE 对象的指针,该 FILE 对象标识了输入流。
返回值:
如果成功,则返回被推入的字符,否则返回 EOF,且流 stream 保持不变。
函数功能:
把字符 char(一个无符号字符)推入到指定的流 stream 中,以便它是下一个被读取到的字符。
1 | |
假设我们有一个文本文件 abc.txt,它的内容如下。文件将作为实例中的输入:
this is w3cschool
!c standard library
!library functions and macros
让我们编译并运行上面的程序,这将产生以下结果:
this is w3cschool
+c standard library
+library functions and macros
2、fllush ( )函数
函数原型:
int fflush(FILE *stream)
参数:
stream – 这是指向 FILE 对象的指针,该 FILE 对象指定了一个缓冲流。
返回值:
如果成功,该函数返回零值。指定的流没有缓冲区或者只读打开时也返回0值。如果发生错误,则返回 EOF,且设置错误标识符(即 feof)。
函数功能:
清除读写缓冲区,需要立即把输出缓冲区的数据进行物理写入时
fflush()会强迫将缓冲区内的数据写回参数stream 指定的文件中. 如果参数stream 为NULL,fflush()会将所有打开的文件数据更新.
其他用法编辑
fflush(stdin)刷新标准输入缓冲区,把输入缓冲区里的东西丢弃[非标准]
fflush(stdout)刷新标准输出缓冲区,把输出缓冲区里的东西打印到标准输出设备上
printf(“。。。。。。。。。。。”);后面加fflush(stdout);可提高打印效率
只有满足如下四个条件中的某一个,输出缓冲区里的内容才会显示在屏幕上
1 “\n”换行字符前面的内容会打印在屏幕上
2 当主函数结束后程序打印的内容出现在屏幕上
3 当输出缓冲区被充满了的时候里面的内容会被打印在屏幕上
4 可以使用fflush(stdout)语句把输出缓冲区里的内容强制显示在屏幕上
1 | |
3、setvbuf ()函数
函数功能:
定义流 stream 应如何缓冲
函数原型:
int setvbuf(FILE *stream, char *buffer, int mode, size_t size)
参数:
stream – 这是指向 FILE 对象的指针,该 FILE 对象标识了一个打开的流。
buffer – 这是分配给用户的缓冲。如果设置为 NULL,该函数会自动分配一个指定大小的缓冲。
mode – 这指定了文件缓冲的模式:
模式:
_IOFBF 全缓冲:对于输出,数据在缓冲填满时被一次性写入。对于输入,缓冲会在请求输入且缓冲为空时被填充。
_IOLBF 行缓冲:对于输出,数据在遇到换行符或者在缓冲填满时被写入,具体视情况而定。对于输入,缓冲会在请求输入且缓冲为空时被填充,直到遇到下一个换行符。
_IONBF 无缓冲:不使用缓冲。每个 I/O 操作都被即时写入。buffer 和 size 参数被忽略。
size –这是缓冲的大小,以字节为单位。
返回值:
如果成功,则该函数返回 0,否则返回非零值。
注意:This function should be called once the file associated with the stream has already been opened but before any input or output operation has taken place.
意思是这个函数应该在打开流后,立即调用,在任何对该流做输入输出前
1 | |
让我们编译并运行上面的程序,这将产生以下结果。在这里,程序把缓冲输出保存到 buff,直到首次调用 fflush() 为止,然后开始缓冲输出,最后休眠 5 秒钟。它会在程序结束之前,发送剩余的输出到 STDOUT。
启用全缓冲
这里是 w3cschool.cc
该输出将保存到 buff
这将在编程时出现
最后休眠五秒钟
4、setbuf () 函数
函数功能:
C 库函数 void setbuf(FILE *stream, char *buffer) 定义流 stream 应如何缓冲。该函数应在与流 stream 相关的文件被打开时,且还未发生任何输入或输出操作之前被调用一次。
函数声明:
void setbuf(FILE *stream, char *buffer)
参数:
stream – 这是指向 FILE 对象的指针,该 FILE 对象标识了一个打开的流。
buffer – 这是分配给用户的缓冲,它的长度至少为 BUFSIZ 字节,BUFSIZ 是一个宏常量,表示数组的长度。
返回值:
该函数不返回任何值。
说明:
setbuf函数具有打开和关闭缓冲机制。为了带缓冲进行I/O,参数buf必须指向一个长度为BUFSIZE(定义在stdio.h头文件中)的缓冲区。通常在此之后该流就是全缓冲的,但是如果该流与一个终端设备相关,那么某些系统也可以将其设置为行缓冲。为了关闭缓冲,可以将buf参数设置为NULL。
1 | |
//示例一
1 | |
程序先把outbuf与输出流相连,然后输出一个字符串,这时因为缓冲区已经与流相连,所以outbuf中也保存着这个字符串,紧接着puts函数又输出一遍,所以现在outbuf中保存着两个一样的字符串。刷新输出流之后,再次puts,则又输出两个字符串。为了关闭缓冲,可以将buf参数设置为NULL。
1 | |
看一下下面这种写法对不对:
1 | |
遗憾的是,这个程序是错误的,仅仅是因为一个细微的原因。程序中对库函数 setbuf 的调用,通知了输入/输出库所有字符的标准输出应该首先缓存在buf中。要找到问题出自何处,我们不妨思考一下 buf 缓冲区最后一次被清空是在什么时候?答案是在main函数结束之后,作为程序交回控制给操作系统之前C运行时库所必须进行的清理工作的一部分。但是,在此之前buf字符数组已经被释放!要避免这种类型的错误有两种办法。
第一种办法是让缓冲数组成为静态数组,既可以直接显式声明buf为静态:
static char buf[BUFSIZ];
也可以把buf声明完全移到main函数之外。第二种办法是动态分配缓冲区,在程序中并不主动释放分配的缓冲区(译注:由于缓冲区是动态分配的,所以main函数结束时并不会释放该缓冲区,这样C运行时库进行清理工作时就不会发生缓冲区已释放的情况):
char *malloc();
setbuf(stdout,malloc(BUFSIZ));
如果读者关心一些编程“小技巧”,也许会注意到这里其实并不需要检查malloc函数调用是否成功。如果malloc函数调用失败,将返回一个null指针。setbuf函数的第二个参数取值可以为null,此时标准输出不需要进行缓冲。这种情况下,程序仍然能够工作,只不过速度较慢而已。
下面这个例子可以很好的看出上面所讲。
1 | |
段错误 (核心已转储)
二、键盘输入
参看:C语言再学习 – 文件
1、键盘输入由一个被称为sdin的流表示,而屏幕(或电传打字机,或其他输出设备)上的输出由一个称为stdout的流表示。getchar()、putchar、printf()、scanf()函数都是标准的I/O的成员,这些函数通这两个流打交道。
2、在printf函数调用语句里用%s做占位符就可以把一个字符串打印在屏幕上可以使用scanf函数从键盘得到一个字符串并把它记录在一个数组里(这个时候要使用%s作为占位符)如果输入内容有空格则只能得到空格前的部分如果输入内容超过数组容量则会出现严重错误fgets函数也可以用来从键盘得到字符串并记录到一个数组里 fgets(str,10,stdin)
这个函数需要三个参数
1 数组名称
2 数组中存储区个数
3 用stdin表示键盘
如果输入的字符个数不够则会把最后输入的回车当作’\n’字符也放到数组里 如果输入的字符过多则只会截取前面的一部分下次都字符串的时候会从后面没有处理的内容里读取应该在每次使用fgets函数获得字符串以后把可能存在的垃圾数据清理掉清理语句应该放在一个分支里,只有当确保有垃圾数据的时候才需要清理
1 | |
3、判断文件结尾
C的处理方法是让getchar()函数在到文件完结为时返回一个特殊值,而不是去管操作系统是如何检测文件结尾的。赋予该值的名称为EOF(End Of File)。因此,检测到文件尾时getchar()的返回值是EOF。scanf()函数在检测到文件结尾时也返回EOF。通常EOF在stdio.h文件中定义。如下所示:
#define EOF (-1)
将getchar()的返回值与EOF进行比较。如果不相同,则你还没有到达文件结尾。换句话说,你可以使用如下表达式:
while ((ch = getchar ()) != EOF)
在Unix系统中,你能通过在一行开始键入Ctrl+D来从键盘模拟文件结束条件;DOS系统则使用Ctrl+Z来达到这个目的。
顺便提一句,Linux中按下Ctrl+Z,表示将该进程中断,在后台挂起,用 fg 命令可以重新切回到前台;按下Ctrl+C表示终止该进程。
参看:C语言再学习 – EOF、feof函数、ferror函数
1 | |
三、scanf() 清空缓冲区
在不同速度的设备之间传递数据的时候需要使用缓冲区临时储存数据
scanf函数工作是会利用有一个输入缓冲区把用户在键盘上输入的字符历史存储起来,程序实际上从这个输入缓冲区里获得数字先进入输入缓冲区的数据必须优先处理,如果计算机先输入的内容没有处理如果用户输入的内容和scanf函数要求的格式不一致则他们会一直无法被处理这会导致后面输入的内容也无法处理,可以使用如下两条语句把输入缓冲区里可能存在的错误数据丢弃:
scanf(“%[^\n]”); //把输入缓冲区里第一个换行字符前的所有内容丢弃
scanf(“%*c”); //把输入缓冲区里第一个换行字符丢弃
1 | |
四、printf() 函数使用输出缓冲区临时存储要打印的内容
只有满足如下四个条件中的某一个,输出缓冲区里的内容才会显示在屏幕上
1 “\n”换行字符前面的内容会打印在屏幕上
2 当主函数结束后程序打印的内容出现在屏幕上
3 当输出缓冲区被充满了的时候里面的内容会被打印在屏幕上
4 可以使用fflush(stdout)语句把输出缓冲区里的内容强制显示在屏幕上
1 | |
五、getcahr()和putchar()
getchar ()函数没有参数,他返回来自输入设备的下一个字符。例如,下面的语句读取下一个输入字符并将它的值赋给变量ch:
ch = getchar();
该语句与下面的语句有同样的效果: scanf (“%c”, &ch);
putchar()函数打印它的参数。例如下面的语句将先前赋给ch的值作为字符打印出来:
putchar (ch);
该语句与下面的语句有同样的效果: printf (“%c”, ch); /不打印换行符(’\0’)/
注意: 它们不需要格式说明符,因为它们只对字符起作用。这两个函数通常都在stdio.h文件中定义(而且他们通常只是预处理器宏(macro)),而不是真正的函数。
1 | |
六、getchar()和scanf()混合使用
getchar()读取每个字符,包括空格、制表符和换行符;而scanf()在读取数字是则会跳过空格、制表符和换行符。因此他们不能很好的混合在一起。
例如:
1 | |
七、输入确认
两个例子:
1 | |
1 | |
输入有字符组成,但scanf()可以将输入转换成整数或浮点值。使用想%d或%f这样的说明符能限制可接受的输入的字符类型,但getchar()和使用%c的scanf()接受任何字符。
八、字符串输入
三种方法:
1、scanf()函数输入
char *str1[20];
char *str2[20];
scanf (“%s %s”, str1, str2);
str是已分配的20字节存储块的地址,也可以使用C库里分配存储空间的函数,如malloc()。
char *ptr = (char)malloc (20sizeof (char));
scanf()可以不仅可以读取字符串还可以获取单个字符。如果使用%s格式,字符串读到(但不包括)下一个空白字符(比如空格、制表符或换行符)输入结束。
scanf()函数返回一个整数值,这个值是成功读取的项目数,或者当遇到文件结束时返回一个EOF(文件结尾符)。
1 | |
2、gets()函数输入
gets()函数从系统的标准输入设备(通常是键盘)获得一个字符串。因为字符串没有预定的长度,所以gets()需要知道输入何时结束。解决办法是读字符串直到遇到一个换行字符串(\n),按回车键可以产生这个字符。它将读取换行符并将其丢弃,这样下一次读取就会在新的一行开始。它读取换行符之前(不包括换行符)的所有字符,在这些字符后添加一个字符(\0),然后把这个字符交给调用它的程序。
gets()函数通过两种方式获得输入:
A、它使用一个地址把字符串赋予name
B、gets()的代码使用return关键字返回字符串的地址,程序把这个地址分配给ptr。注意到ptr是一个指针,这意味着gets()必须返回一个指向char的指针值。需要注意的是gets()返回的指针与传递给它的是同一个指针。输入字符串只有一个备份,它放在作为函数参数传递过来的地址中。
1 | |
3、fgets()函数输入
fgets()是为文件I/O而设计的,它与gets()有三方面不同:
A、gets()不检查预留存储区是否能够容纳实际输入的数据,多出来的字符简单地溢出到相邻的内存区。而fgets()函数可以在第二个参数来说明最大读入字符数,如果这个参数值为n,fgets()就会读取最多n-1个字符或者读完一个换行符为止,由这二者最先满足的那个来结束输入。
B、如果fgets()读取到换行符,就会把它存到字符串里,这样每次显示字符串时就会显示换行符;而不是像gets()那样丢弃它。
C、fgets()还需第三个参数来说明读哪一个文件。从键盘上读数据时,可以使用stdin(代表standard input)作为该参数,这个标识符在stdio.h中定义。
1 | |
去掉换行符:
1 | |
函数
一、函数概述
1、首先什么是函数?
函数是用于完成特定任务的程序代码的自包含单元。
2、为什么使用函数?
第一、函数的使用可以身故重复代码的编写。第二、函数使得程序更加模块化,有利于程序的阅读修改和完善。
3、main函数原型
int main (int argc, char * argv[], char * envp[]) {….}
第一个参数:命令行参数的个数
第二个参数:命令行参数的地址信息
第三个参数:环境表的首地址
参数argc表示输入参数的个数(含命令名),如果有命令行参数,argc应不小于1;argv表示传入的参数的字符串,是一个字符串数组,argv[0]表示命令名,argv[1]指向第一个命令行参数;至于第三个参数env,它与全局变量environ相比也没有带来更多益处,所以POSIX.1也规定应使用environ而不使用第三个参数。通常用getenv和putenv函数来存取特定的环境变量,而不是直接使用environ变量。例如:
//main函数原型的使用
#include <stdio.h>
int main(int argc,char* argv[],char* envp[])
{
printf(“argc=%d\n”,argc);
int i=0;
for(i=0;i<argc;i++)
{
printf(“感谢%s\n”,argv[i]);
}
//声明全局变量
extern char** environ;
printf(“environ=%p,envp=%p\n”,environ,envp);//直接访问环境表
return 0;
}
输出结果为:
argc=1
感谢./a.out
environ=0xbfab74cc,envp=0xbfab74cc
再如:
命令行为:myprogram c:\a.txt c:\b.txt
则:argc==3
argv[0]==”myprogram”
argv[1]==”c:\a.txt”
argv[2]==”c:\b.txt”
再再如:
#include <stdio.h>
int main (int argc, char *argv[])
{
int count;
printf (“The command line has %d arguments: \n”, argc - 1);
for (count = 1; count < argc; count++)
printf (“%d: %s\n”, count, argv[count]);
printf (“\n”);
return 0;
}
输出结果:
tarena@ubuntu:~/project/C$ ./a.out I LOVE YOU
The command line has 3 arguments:
1: I
2: LOVE
3: YOU
每个C程序都必须有一个 main 函数,因为它是程序执行的起点。关键字 int 表示函数返回一个整型值,关键字 void 表示函数不接受任何参数。main 函数的函数体包括左花括号和与之匹配的右花括号之间的任何内容。
注意:如果没有写明返回值,一般默认为 int 类型。
main (void)
{
…
return 0;
}
二、函数声明和定义
1、函数声明
在任何程序在使用函数之前都需要声明该函数的类型。
例如:int imax (int a, int b);
第一个int指的是函数类型;位于圆括号内的两个int表明该函数的形式参数为int类型。分号的作用表示该语句是进行函数声明而不是函数定义。
在函数原型中可以根据自己的喜好省略变量名。
int imax (int , int);
需要注意的是这些变量名只是虚设的名字,他们不必和函数定义中使用的变量名想匹配。使用这种函数原型信息,编译器就可以检查函数调用语句是否和其原型声明一致。比如检查参数个数是否正确,参数类型是否匹配。将声明语句放置在main ()之前和之内两种方式都是正确的。需要重点注意的是函数声明要在使用函数之前进行。当在main之前函数定义的话,就不需要声明语句了。
#include <stdio.h>
int imin (int, int);
int main (void)
{
int inim (int, int);
}
2、隐式声明
如果被调用函数写在调用函数后面则编译器会猜测被调用函数的格式,这叫做函数的隐式声明。隐式声明可以和实际情况不一致这时就会出错,可以把被调用函数的声明单独写在文件开头,这叫做函数的显示声明。除了主函数以外的所有函数都应该进行显示声明,因为主函数永远不是被调用函数。如果main()之后又函数定义,main()之前却没有函数声明的话,编译的时候会出现隐式声明报错。
3、头文件的使用
如果把main ()函数放在第一个文件中吧自定义哈拿书放在第二个文件中实现,那么第一个文件仍需要使用函数原型。如果把函数原型放在一个头文件中,就不必每次使用这些函数时输入其原型声明了。
#ifndef 02READ_H
#define 02READ_H
extern int num; //主函数全局变量写在了头文件里且要加extern关键字
int read(char, int); //函数声明
#define PI 3.14
#endif
4、函数定义
函数声明只是将函数类型告诉编译器,而函数定义部分则是函数的实际实现代码。之所以使用函数原型,是为了在编译器编译第一个调用函数的语句之前想其表明该函数的使用方法。因此,可以在首次调用某函数之前对该函授进行完整的定义。这样函数定义部分就和函数原型有着相同的作用。通常对较小的函数会这样做:
//下面既是一个函数的定义,也是它的原型
#include <stdio.h>
int imax (int a, int b)
{
return a > b ? a : b;
}
int main (void)
{
int x, z;
scanf (“%d”, &x);
z = imax (x, 50);
printf (“%d\n”, z);
return 0;
}
三、函数形参与实参
1、形式参数
函数定义为下面的函数:
void show (char ch, int num)
这行代码通知编译器show()使用名为ch和num的两个参数,并且这两个参数的类型分别为char和int。变量ch和num被称为形式参数。
注意:ANSI C形式要求在每个变量前声明其类型。也就是说,不能像通常变量声明那样使用变量列表声明同一类型的变量。如下所示:
void dibs (int x, y, z) /不正确的函数头/
void dibs (int x, int y, int z) /正确的函数头/
2、实际参数
函数调用中,通常使用实际参数对ch和num赋值,如:
show (SPACE, 12);
形式参数是被调函数中的变量,而实际参数是调用函数分配给被调用函数变量的特定数值。实际参数可以是常量、变量或一个复杂的表达式。但是无论何种形式的实际参数,执行时首先要计算其值,然后将该值复制给被调用函数中相应的形式参数。
3、无参数
void dibs (void);
为了表示一个函数确实不使用参数,需要在圆括号内加入void关键字。
四、递归函数
1、递归介绍
C允许一个函数条用其本身,这种调用过程被称为递归。
递归与循环比较:
采用递归函数解决问题的思路叫递归
采用循环解决同样问题的思路叫递推
递归一般可以代替循环语句使用。有些情况下使用循环语句比较好,而有些时候使用递归更有效。递归方法虽然使用程序结构优美,但其执行效率却没有循环语句高。一般来说,选择循环更好一些。首先,因为每次递归调用都拥有自己的变量集合,所以就需要占用较多的内存;每次递归调用需要把心的变量集合存储在堆栈中。其次,由于进行每次函数调用需要花费一定的时间,所以递归的执行速度较慢。
//示例一
#include <stdio.h>
void show (int);
int main (void)
{
show (1);
return 0;
}
void show (int n)
{
printf (“Level %d: n location %p\n”, n, &n);
if (n < 4)
show (n + 1);
printf (“Level %d: n location %p\n”, n, &n);
}
执行结果如下:
Level 1: n location 0xbf8bf680
Level 2: n location 0xbf8bf660
Level 3: n location 0xbf8bf640
Level 4: n location 0xbf8bf620
Level 4: n location 0xbf8bf620
Level 3: n location 0xbf8bf640
Level 2: n location 0xbf8bf660
Level 1: n location 0xbf8bf680
//示例二
#include <stdio.h>
void print (int num)
{
if (num == 1)
{
printf (“1\n”);
return ;
}
printf (“%d\n”, num);
print (num -1);
}
int main (void)
{
print (10);
return 0;
}
输出结果:
10
9
8
7
6
5
4
3
2
1
2、递归的基本原理
第一:每一级的函数调用都有自己的变量。
第二:每一次函数调用都会有一次返回。
第三:递归函数中,位于递归调用前的语句和各级被调用函数具有相同的执行顺序。
第四:递归函数中,位于递归调用后的语句的执行顺序和各个被调用函数的顺序相反。
第五:虽然每一级递归都有自己的变量,但是函数代码并不会得到复制。
最后:递归函数中必须包含可以终止递归调用的语句。
3、递归的优缺点
其优点在于为某些变成问题提供了最简单的解决方法,而缺点是一些递归算法会很快耗尽计算机的内存资源。同时,使用递归的程序难于阅读和维护。
五、指针函数和函数指针
指针函数:返回指向char的指针的函数,例如:char * fump ( );
函数指针:指向返回类型char的函数指针,例如:char (* frump) ( );
这里需要明白一个符号之间优先级的问题,”( )”的优先级比”*”要高。
再考虑一个,char (* flump[3]) ( );
由3个指针组成的数组,每个指针指向返回类型为 char 的函数
————————————————
版权声明:本文为CSDN博主「聚优致成」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_29350001/article/details/52351060
九、字符串输出
1、printf()函数输出
printf (“%s, %s\n”, name, str);
printf ()函数需要一个字符串地址作为参数,优点在于可以格式化多种数据类型。
2、puts()函数输出
puts()函数只需要给出字符串参数的地址,每一个字符串都是单行显示。与printf()不同,puts()显示字符串时自动在其后添加一个换行符。当遇到空字符就会停止,必须确保有空字符(\0)存在。
#include <stdio.h>
int main (void)
{
char code1[] = “haha!”;
char code[] = {‘h’,’e’,’l’,’l’,’o’,’ ‘,’w’,’o’,’r’,’l’,’d’ };
char code2[] = “show!”;
puts (code);
return 0;
}
输出结果:
hello worldhaha!
说明:code没有空字符(\0),因此它是一个字符数组不是一个字符串,puts()函数将继续执行直到遇到code2中的空字符。
3、fputs()函数输出
fputs()函数需要第二个参数来说明要写的文件。可以使用stdout (代表 stdndard output)作为参数来进行输出显示,stdout在stdio.h中定义。与puts()不同,fputs()并不为输出自动添加换行符。
注意:gets()丢掉输入里的换行符,但是puts()为输出添加换行符。fgets()存储输入中的换行符,而fputs不为输出添加换行符。由此可见:
gets()和 puts()一起使用,fgets()和fputs()一起使用。
4、putcahr()函数输出,扩展
#include <stdio.h>
int put (const char *); /使用const关键字/
int main (void)
{
char arr[] = {‘h’, ‘e’, ‘ ‘ , ‘l’, ‘l’, ‘o’}; /*区分空格符 ‘’*和空白符’\0’/
char *ptr = arr;
while (*ptr != ‘\0’){ /*等价于 while (ptr)/
putchar (*ptr++);
}
putchar (‘\n’);
printf (“I love you %d\n” ,
(“hello world!”)); /计算机先计算put()函数,所以先输出hello world!/
return 0;
}
int put (const char *string)
{
int count = 0;
while (*string){
putchar (*string++);
count++;
}
putchar (‘\n’); /putchar不打印换行符/
return count;
}
输出结果:
he llo
hello world!
I love you 12
十、文件输入
1、getc ()函数输入
函数功能:
从流中取字符
函数用法:
int getc(FILE *stream);
//read the next character from stream and return it as an unsigned char cast to a int ,or EOF on end of file or error.
注意: 此函数被ISO C声明为一个宏,所以在用时不能将其做为函数指针传(有一些编用时不能将其做为函数指针传(有一些编译器将其以函数形式也给另说)。
//示例
#include<stdio.h>
int main()
{
char c;
printf(“请输入字符:”);
c = getc(stdin);
printf(“输入的字符:”);
putc(c, stdout);
return(0);
}
getc、fgetc、getchar函数区别:
//函数原型
#include <stdio.h>
int getc(FILE *stream);
int fgetc(FILE *stream);
int getchar(void);
getchar ()函数从标准输入(键盘)获得一个字符:
ch = getchar ( );
getc ()函数从fp指定的文件中获得一个字符:
ch = getc (fp);
所以,ch = getc (stdin) 和 ch = getchar ( )的作用是一样的。
参看:fgetc和getc的区别
两个都是用来从stream中取得一个字符的,区别在于调用getc函数时所用的参数stream不能是有副作用的表达式,而fgetc函数则可以,也就是说,getc可以被当作宏来调用,而fgetc只能作为函数来调用。一般来说,调用宏比调用函数耗费的时间少。
扩展:有副作用的表达式,指的是表达式执行后,会改变表达式中某些变量的值
最简单的如++i,这个表达式执行后,i的值会改变,这样的表达式是不应该在宏调用里出现的
//fgetc()示例
#include <stdio.h>
int main(void)
{
FILE *fp;
int c;
fp = fopen(“abc.txt”, “r”);
while((c = fgetc(fp)) != EOF)
{
if (c == ‘b’)
{
putchar(c);
}
}
fclose(fp);
return 0;
}
2、fprintf ()函数
fprintf ()的工作方式和printf()相似,区别在于前者需要第一个参数来指定合适的文件。
函数声明:
int fprintf(FILE * stream, const char * format, …);
函数说明:
fprintf()会根据参数format 字符串来转换并格式化数据, 然后将结果输出到参数stream 指定的文件中, 直到出现字符串结束(‘\0’)为止。
返回值:
关于参数format 字符串的格式请参考printf(). 成功则返回实际输出的字符数, 失败则返回-1, 错误原因存于errno 中.
参数:
stream – 这是指向 FILE 对象的指针,该 FILE 对象标识了流。
format – 这是 C 字符串,包含了要被写入到流 stream 中的文本。它可以包含嵌入的 format 标签,format 标签可被随后的附加参数中指定的值替换,并按需求进行格式化。
参看:C语言再学习 – printf、scanf占位符
/*
fprintf函数演示
*/
#include <stdio.h>
int main()
{
FILE *p_file = fopen(“b.txt”,”w”);
if(p_file)
{
// printf(“%c,%g,%d\n”,’c’,3.14f,46); //打印在屏幕上
fprintf(p_file,”%c,%g,%d\n”,’c’,3.14,46);//fprintf函数可以把数据按照格式记录到文本文件中
fclose(p_file);
p_file=NULL;
}
return 0;
}
十一、文件输出
1、putc ()函数
函数功能:
用于输入一个字符到指定流中
函数原型:
int putc(int ch, FILE *stream);
参数:
参数ch表示要输入的位置,参数stream为要输入的流。
返回值:
若正确,返回输入的的字符,否则返回EOF。
//putc示例
#include <stdio.h>
int main ()
{
FILE *fp;
int ch;
fp = fopen(“abc.txt”, “w”);
for( ch = 33 ; ch <= 100; ch++ )
{
putc(ch, fp);
}
fclose(fp);
return(0);
}
//fgetc读取
#include <stdio.h>
int main ()
{
FILE *fp;
int c;
fp = fopen(“file.txt”,”r”);
while(1)
{
c = fgetc(fp);
if( feof(fp) )
{
break ;
}
printf(“%c”, c);
}
fclose(fp);
return(0);
}
putc与putchar的区别:
putchar函数,输出到显示器
putc函数,将字符输入到文件
把stdout作为putc()函数的第二个参数。stdout是在stdout中定义的与标准输出相关的文件指针,
所以putc (ch, stdout) 和 putchar ( )的作用是一样的。
2、fscanf ()函数
fscanf ()的工作方式和scanf()相似,区别在于前者需要第一个参数来指定合适的文件。
函数声明:
int fscanf(FILE *stream, const char *format, …)
参数:
stream – 这是指向 FILE 对象的指针,该 FILE 对象标识了流。
format – 这是 C 字符串,包含了以下各项中的一个或多个:空格字符、非空格字符和format说明符。
参看:C语言再学习 – printf、scanf占位符
返回值:
如果成功,该函数返回成功匹配和赋值的个数。如果到达文件末尾或发生读错误,则返回 EOF。
/*
fscanf函数演示
*/
#include <stdio.h>
int main()
{
char ch=0;
float fnum=0.0;
int num=0;
FILE *p_file=fopen(“b.txt”,”r”);
if(p_file)
{
// scanf(“%c%g%d”,&ch,&fnum,&num);
fscanf(p_file,”%c %g %d”,&ch,&fnum,&num);//fscanf函数可以从文件中按照格式把数据拷贝到内存的存储区里
printf(“%g %c %d\n”,fnum,ch,num); //拷贝到存储区我们就可以打印出来
fclose(p_file);
p_file=NULL;
}
return 0;
}
————————————————
版权声明:本文为CSDN博主「聚优致成」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_29350001/article/details/52316708
关键字
C语言一共有32个关键字,如下表所示:
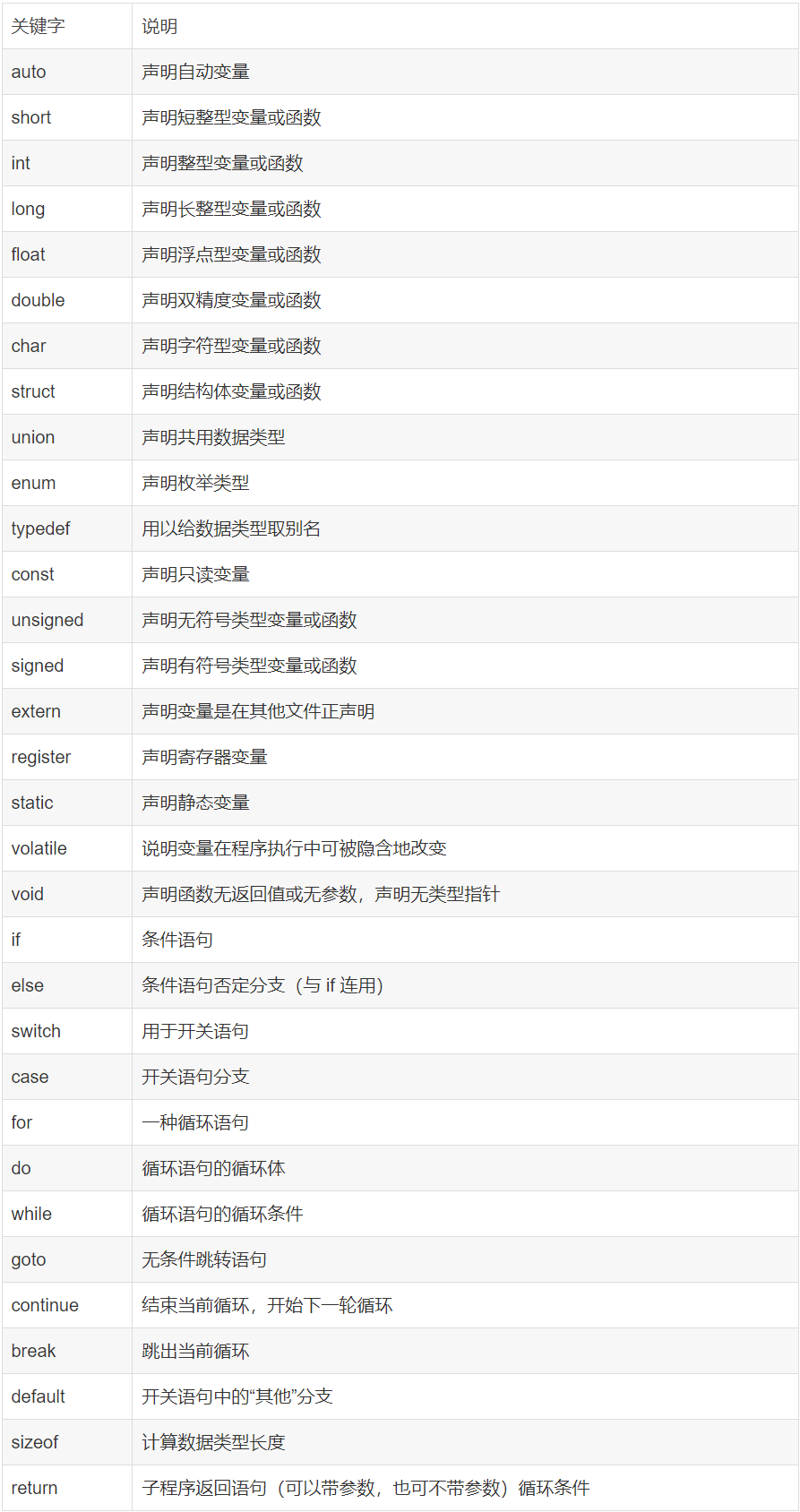
C语言32个关键字详解
1. 数据类型关键字
A)基本数据类型(5个)
void:声明函数无返回值或无参数,声明无类型指针,显式丢弃运算结果
char:字符型类型数据,属于整型数据的一种
int:整型数据,通常为编译器指定的机器字长
float:单精度浮点型数据,属于浮点数据的一种
double:双精度浮点型数据,属于浮点数据的一种
B)类型修饰关键字(4个)
short:修饰int,短整型数据,可省略被修饰的int。
long:修饰int,长整形数据,可省略被修饰的int。
signed:修饰整型数据,有符号数据类型
unsigned:修饰整型数据,无符号数据类型
C)复杂类型关键字(5个)
struct:结构体声明
union:共用体声明
enum:枚举声明
typedef:声明类型别名
sizeof:得到特定类型或特定类型变量的大小
D)存储级别关键字(6个)
auto:指定为自动变量,由编译器自动分配及释放。通常在栈上分配
static:指定为静态变量,分配在静态变量区,修饰函数时,指定函数作用域为文件内部
register:指定为寄存器变量,建议编译器将变量存储到寄存器中使用,也可以修饰函数形参,建议编译器通过寄存器而不是堆栈传递参数
extern:指定对应变量为外部变量,即在另外的目标文件中定义,可以认为是约定由另外文件声明的对象的一个“引用“
const:与volatile合称“cv特性”,指定变量不可被当前线程/进程改变(但有可能被系统或其他线程/进程改变)
volatile:与const合称“cv特性”,指定变量的值有可能会被系统或其他进程/线程改变,强制编译器每次从内存中取得该变量的值
2. 流程控制关键字
A)跳转结构(4个)
return:用在函数体中,返回特定值(或者是void值,即不返回值)
continue:结束当前循环,开始下一轮循环
break:跳出当前循环或switch结构
goto:无条件跳转语句
B)分支结构(5个)
if:条件语句
else:条件语句否定分支(与if连用)
switch:开关语句(多重分支语句)
case:开关语句中的分支标记
default:开关语句中的“其他”分治,可选。
C)循环结构(3个)
for:for循环结构,for(1;2;3)4;的执行顺序为1->2->4->3->2…循环,其中2为循环条件
do:do循环结构,do 1 while(2);的执行顺序是1->2->1…循环,2为循环条件
while:while循环结构,while(1) 2;的执行顺序是1->2->1…循环,1为循环条件
以上循环语句,当循环条件表达式为真则继续循环,为假则跳出循环。
下面来详细介绍各个关键字:
(简单的就一笔带过,有必要的会另起一篇文章,详细讲述。)
基本数据类型(5个)和 类型修饰关键字(4个)
基本数据类型(5个)
void
char
int
float
double
类型修饰关键字(4个)
short
long
signed
unsigned
1)在windows,32位系统中
char 1个字节
short 2个字节
int 4个字节
long 4个字节
double 8个字节
float 4个字节
2)数据类型和占位符之间的对应关系
char和unsingned char %c
short %hd
unsigned short %hu
long %ld
unsigned long %lu
int %d
unsigned int %u
float %f/%g
double %lf/%lg
%f和%lf会保留小数点后面多余的0 如 3.1400000 .2%f得 3.14
%g和%lg不会保留 如 3.14
规定整型值相互之间大小的规则:
长整型至少应该和整型一样长,而整型至少应该和短整型一样长。
扩展:C语言再学习 5–浮点数
扩展:C语言再学习 19 – 负数
3)signed、unsigned关键字
signed char取值范围是 -2^7 到 2^7-1
unsigned char取值范围是 0 到 2^8
signed int取值范围是 -2^31 到 2^31-1
unsigned int取值范围是 0 到 2^32
留两个问题思考:
1), int i = -20;
unsigned j = 10;
i+j 的值为多少?为什么?
-10 应该是按照有符号的来计算的
2), 下面的代码有什么问题?
unsigned i ;
for (i=9;i>=0;i–)
{
printf(“%u\n”,i);
}
一直打印无法停止,到了0 后,变成-1。因为-1是有符号的了,再变成 4294967295一直又减下去了
4)void关键字:
参看:C语言再学习 19 – void
复杂类型关键字(5个)
struct
union
enum
typedef
sizeof
1)struct
参看:C语言再学习 – 关键字struct(转)
2)union、enum
参看:C语言再学习 – 结构和其他数据形式
3)typedef
参看:C语言再学习 – 关键字typedef
4)sizeof
参看:C语言再学习 – sizeof与strlen
存储级别关键字(6个)
auto
static
register
extern
const
volatile
1)auto、static、register、extern
参看:C语言再学习 – 存储类型关键字
2)const
参看:C语言再学习 – 关键字const
3)volatile
参看:C语言再学习 – 关键字volatile
流程控制关键字
A)跳转结构(4个)
return
continue
break
goto
1)return
参看:C语言再学习 – 关键字return和exit
2)continue、break、goto
参看:C语言再学习 – 分支与跳转语句
B)分支结构(5个)
if
else
switch
case
default
1)if、else、switch、case、default
参看:C语言再学习 – 分支与跳转语句
C)循环结构(3个)
for
do
while
1)for、do、while
参看:C语言再学习 – 循环语句
ASCII码表
ASCII码大致可以分作三部分组成。
- 第一部分是:ASCII非打印控制字符
- 第二部分是:ASCII打印字符;
- 第三部分是:扩展ASCII打印字符
第一部分:ASCII非打印控制字符表
ASCII表上的数字0–31分配给了控制字符,用于控制像打印机等一些外围设备。例如,12代表换页/新页功能。此命令指示打印机跳到下一页的开头。(参详ASCII码表中0-31)
第二部分:ASCII打印字符
数字 32–126 分配给了能在键盘上找到的字符,当您查看或打印文档时就会出现。数字127代表 DELETE 命令。(参详ASCII码表中32-127)
ASCII码表 0-127
| Bin | Dec | Hex | 缩写/字符 | 解释 |
|---|---|---|---|---|
| 00000000 | 0 | 00 | NUL(null) | 空字符 |
| 00000001 | 1 | 01 | SOH(start of headling) | 标题开始 |
| 00000010 | 2 | 02 | STX (start of text) | 正文开始 |
| 00000011 | 3 | 03 | ETX (end of text) | 正文结束 |
| 00000100 | 4 | 04 | EOT (end of transmission) | 传输结束 |
| 00000101 | 5 | 05 | ENQ (enquiry) | 请求 |
| 00000110 | 6 | 06 | ACK (acknowledge) | 收到通知 |
| 00000111 | 7 | 07 | BEL (bell) | 响铃 |
| 00001000 | 8 | 08 | BS (backspace) | 退格 |
| 00001001 | 9 | 09 | HT (horizontal tab) | 水平制表符 |
| 00001010 | 10 | 0A | LF (NL line feed, new line) | 换行键 |
| 00001011 | 11 | 0B | VT (vertical tab) | 垂直制表符 |
| 00001100 | 12 | 0C | FF (NP form feed, new page) | 换页键 |
| 00001101 | 13 | 0D | CR (carriage return) | 回车键 |
| 00001110 | 14 | 0E | SO (shift out) | 不用切换 |
| 00001111 | 15 | 0F | SI (shift in) | 启用切换 |
| 00010000 | 16 | 10 | DLE (data link escape) | 数据链路转义 |
| 00010001 | 17 | 11 | DC1 (device control 1) | 设备控制1 |
| 00010010 | 18 | 12 | DC2 (device control 2) | 设备控制2 |
| 00010011 | 19 | 13 | DC3 (device control 3) | 设备控制3 |
| 00010100 | 20 | 14 | DC4 (device control 4) | 设备控制4 |
| 00010101 | 21 | 15 | NAK (negative acknowledge) | 拒绝接收 |
| 00010110 | 22 | 16 | SYN (synchronous idle) | 同步空闲 |
| 00010111 | 23 | 17 | ETB (end of trans. block) | 传输块结束 |
| 00011000 | 24 | 18 | CAN (cancel) | 取消 |
| 00011001 | 25 | 19 | EM (end of medium) | 介质中断 |
| 00011010 | 26 | 1A | SUB (substitute) | 替补 |
| 00011011 | 27 | 1B | ESC (escape) | 溢出 |
| 00011100 | 28 | 1C | FS (file separator) | 文件分割符 |
| 00011101 | 29 | 1D | GS (group separator) | 分组符 |
| 00011110 | 30 | 1E | RS (record separator) | 记录分离符 |
| 00011111 | 31 | 1F | US (unit separator) | 单元分隔符 |
| 00100000 | 32 | 20 | (space) | 空格 |
| 00100001 | 33 | 21 | ! | |
| 00100010 | 34 | 22 | “ | |
| 00100011 | 35 | 23 | # | |
| 00100100 | 36 | 24 | $ | |
| 00100101 | 37 | 25 | % | |
| 00100110 | 38 | 26 | & | |
| 00100111 | 39 | 27 | ‘ | |
| 00101000 | 40 | 28 | ( | |
| 00101001 | 41 | 29 | ) | |
| 00101010 | 42 | 2A | * | |
| 00101011 | 43 | 2B | + | |
| 00101100 | 44 | 2C | , | |
| 00101101 | 45 | 2D | - | |
| 00101110 | 46 | 2E | . | |
| 00101111 | 47 | 2F | / | |
| 00110000 | 48 | 30 | 0 | |
| 00110001 | 49 | 31 | 1 | |
| 00110010 | 50 | 32 | 2 | |
| 00110011 | 51 | 33 | 3 | |
| 00110100 | 52 | 34 | 4 | |
| 00110101 | 53 | 35 | 5 | |
| 00110110 | 54 | 36 | 6 | |
| 00110111 | 55 | 37 | 7 | |
| 00111000 | 56 | 38 | 8 | |
| 00111001 | 57 | 39 | 9 | |
| 00111010 | 58 | 3A | : | |
| 00111011 | 59 | 3B | ; | |
| 00111100 | 60 | 3C | < | |
| 00111101 | 61 | 3D | = | |
| 00111110 | 62 | 3E | > | |
| 00111111 | 63 | 3F | ? | |
| 01000000 | 64 | 40 | @ | |
| 01000001 | 65 | 41 | A | |
| 01000010 | 66 | 42 | B | |
| 01000011 | 67 | 43 | C | |
| 01000100 | 68 | 44 | D | |
| 01000101 | 69 | 45 | E | |
| 01000110 | 70 | 46 | F | |
| 01000111 | 71 | 47 | G | |
| 01001000 | 72 | 48 | H | |
| 01001001 | 73 | 49 | I | |
| 01001010 | 74 | 4A | J | |
| 01001011 | 75 | 4B | K | |
| 01001100 | 76 | 4C | L | |
| 01001101 | 77 | 4D | M | |
| 01001110 | 78 | 4E | N | |
| 01001111 | 79 | 4F | O | |
| 01010000 | 80 | 50 | P | |
| 01010001 | 81 | 51 | Q | |
| 01010010 | 82 | 52 | R | |
| 01010011 | 83 | 53 | S | |
| 01010100 | 84 | 54 | T | |
| 01010101 | 85 | 55 | U | |
| 01010110 | 86 | 56 | V | |
| 01010111 | 87 | 57 | W | |
| 01011000 | 88 | 58 | X | |
| 01011001 | 89 | 59 | Y | |
| 01011010 | 90 | 5A | Z | |
| 01011011 | 91 | 5B | [ | |
| 01011100 | 92 | 5C | | | |
| 01011101 | 93 | 5D | ] | |
| 01011110 | 94 | 5E | ^ | |
| 01011111 | 95 | 5F | _ | |
| 01100000 | 96 | 60 | ` | |
| 01100001 | 97 | 61 | a | |
| 01100010 | 98 | 62 | b | |
| 01100011 | 99 | 63 | c | |
| 01100100 | 100 | 64 | d | |
| 01100101 | 101 | 65 | e | |
| 01100110 | 102 | 66 | f | |
| 01100111 | 103 | 67 | g | |
| 01101000 | 104 | 68 | h | |
| 01101001 | 105 | 69 | i | |
| 01101010 | 106 | 6A | j | |
| 01101011 | 107 | 6B | k | |
| 01101100 | 108 | 6C | l | |
| 01101101 | 109 | 6D | m | |
| 01101110 | 110 | 6E | n | |
| 01101111 | 111 | 6F | o | |
| 01110000 | 112 | 70 | p | |
| 01110001 | 113 | 71 | q | |
| 01110010 | 114 | 72 | r | |
| 01110011 | 115 | 73 | s | |
| 01110100 | 116 | 74 | t | |
| 01110101 | 117 | 75 | u | |
| 01110110 | 118 | 76 | v | |
| 01110111 | 119 | 77 | w | |
| 01111000 | 120 | 78 | x | |
| 01111001 | 121 | 79 | y | |
| 01111010 | 122 | 7A | z | |
| 01111011 | 123 | 7B | { | |
| 01111100 | 124 | 7C | ||
| 01111101 | 125 | 7D | } | |
| 01111110 | 126 | 7E | ~ | |
| 01111111 | 127 | 7F | DEL (delete) | 删除 |
第三部分:扩展ASCII打印字符
扩展的ASCII字符满足了对更多字符的需求。扩展的ASCII包含ASCII中已有的128个字符(数字0–32显示在下图中),又增加了128个字符,总共是256个。即使有了这些更多的字符,许多语言还是包含无法压缩到256个字符中的符号。因此,出现了一些ASCII的变体来囊括地区性字符和符号。例如,许多软件程序把ASCII表(又称作ISO8859-1)用于北美、西欧、澳大利亚和非洲的语言。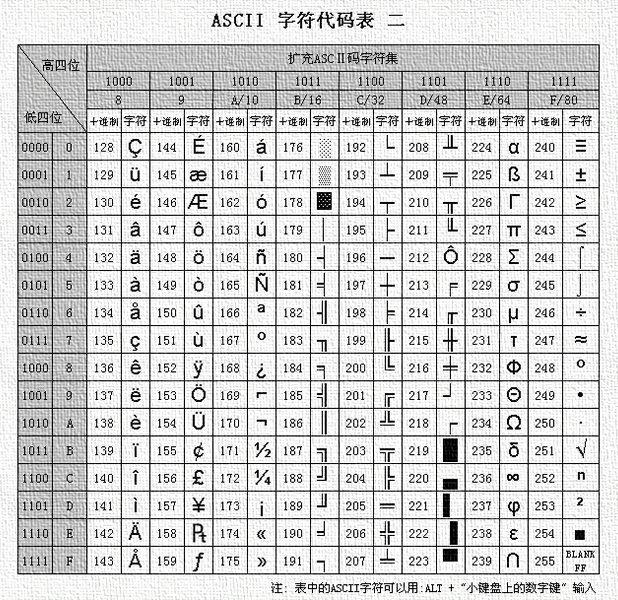
字符串和字符串函数
一、字符串
1、字符串介绍
字符串是以空字符(\0)结尾的char数组,例如:
char ar[20] = “hello world”;
2、定义字符串
字符常量,又称字符串文字,是指位于一对双引号中的任何字符。双引号里的字符加上编译器自动提供的结束标志(\0)字符,作为一个字符串被存储在内存里。
1 | |
3、字符串初始化
定义一个字符串数组时,必须让编译器知道它需要多大空间。
方法一,指定一个足够大的数组来容字符串
1 | |
指定数组大小时,一定要确保数组元素数比字符串长度至少多1(多出来的1个元素用于容纳空字符),未被使用的元素均被自动初始化为0。这里的0是char形式的空字符\0,不是数字字符0.
方法二,让编译器决定数组大小
1 | |
注意:标示结束的空字符。如果没有它,得到的就只是一个字符数组而不是一个字符串。
注意区分:数字字符 0,空字符 \0,空格 ‘ ‘,空指针 NULL。
方法三,指针初始化字符串
1 | |
说明:数组和指针初始化字符串的区别
- 数组初始化是从静态存储区把一个字符串复制给数组,而指针初始化只是复制字符串的地址。其主要区别在于数组名ar是一个常量,而指针str则是一个变量。如,只有指针变量可以进行 str++。数组的元素是变量(除非声明数组时带有关键字const),但是数组名不是变量。如,*(ar + 2) = ‘m’; 是可以的。
扩展,区分单个字符和字符串
用单引号引起的一个字符实际上代表一个整数,整数值对应于该字符的编译器采用的字符集中的序列值。因此,对于采用 ASCII 字符集的编译器而言,’a’ 的含义与 0141(八进制)或者97(十进制)严格一致。
用双引号引起的字符串,代表的却是一个指向无名数组起始字符的指针,该数组被双引号之间的字符以及一个额外的二进制值为零的字符 ‘\0’ 初始化。
1 | |
根据上面的例子,可知 str1、str2以空字符(\0)结尾是字符串。而 str4 不是字符串。
如果两者混用,那么编译器的类型检查功能将会检测到这样的错误:
1 | |
1 | |
还有需要注意的,在用双引号括起来的字符串中,注释符 /* 属于字符串的一部分,而在注释中出现的双引号 “” 又属于注释的一部分。
1 | |
再再有注意宏定义,用于定义字符串,尤其是路径
1 | |
A 为 定义路径, B 为定义字符串
4、字符串输入/输出
参看:输入/输出
二、字符串函数
字符串函数,其原型在/kernel/include/linux/string.h有声明
这类字符串库函数的功能实现函数的答案在内核源码/kernel/lib/string.c
扩展:size_t类型为unsigned int类型,占位符使用%u或%lu,C99用%zd。
下面来介绍一些最有用和最常用的函数:
1、strlen() 函数
#include <string.h>
size_t strlen(const char *s);
函数功能:用来统计字符串中有效字符的个数
功能实现函数:
1 | |
strlen()函数被用作改变字符串长度,例如:
1 | |
可以看出:fit()函数在数组的第8个元素中放置了一个’\0’字符来代替原有的o字符。puts()函数输出停在o字符处,忽略了数组的其他元素。然而,数组的其他元素仍然存在。
2、strcat()函数
1 | |
函数功能:合并两个字符串
缺点:超出字符串存储区范围的话,有可能修改数组以外的存储区这会导致严重错误
功能实现函数:
1 | |
strcat()函数它将第二个字符串的一份拷贝添加到第一个字符串的结尾,从而使第一个字符串成为一个新的组合字符串,第二个字符串并没有改变,例如:
1 | |
3、strncat()函数
上面有提到strcat()函数的缺点,它并不能检查第一个数组是否能够容纳第二个字符串。如果没有为第一个数组分配足够大的空间,多出来的字符溢出到相邻存储单元时就会出现问题。
1 | |
函数功能:合并两个字符串
功能实现函数:
1 | |
例如:
1 | |
4、strcmp()函数
1 | |
函数功能:比较两个字符串的大小,比较依据的是ASCII码
返回值:依次比较字符串每一个字符的ASCII码,如果两个字符串参数相同,返回0;如果第一个字符串参数较大,则返回1,如果第二个字符串较大,则返回-1。
功能实现函数:
1 | |
需要注意的是:
strcmp()函数比较的是字符串,而不是数组和字符。它可以用来比较存放在不同大小数组里的字符串。
1 | |
这里提一下:
- strcmp比较区分字母大小写 相当是比较的时候纯粹按照ascii码值来比较从头到尾。
- 而 stricmp 是不区分字母的大小写的。
5、strncmp()函数
1 | |
函数功能:只比较两个字符串里前n个字符
功能实现函数:
1 | |
6、strcpy()函数
1 | |
函数功能:把一个字符串复制到另外一个字符数组里
缺点:有可能修改不属于数组的存储区,这会导致错误
功能实现函数:
1 | |
例如:
1 | |
因为pts1和pts2都是指向字符串的指针,上面的表达式只复制字符串的地址而不是字符串本身。
字符串之间的复制应使用strcpy ()函数,它在字符串运算中的作用等价于赋值运算符。
总之,strcpy()接受两个字符串指针参数。指向最初字符串的第二个指针可以是一个已声明的指针、数组名或字符串常量。指向复制字符串的第一个指针应指向空间大到足够容纳该字符串的数据对象,比如一个数组。记住,声明一个数组将为数据分配存储空间,而声明一个指针只为一个地方分配存储空间。
1 | |
上述例子,运用了strcpy()函数的两个属性。首先,它是char*类型,它返回的是第一个参数的值,即一个字符的地址;其次,第一个参数不需要指向数组的开始,这样就可以只复制数组的一部分。
7、strncpy()函数
1 | |
函数功能:把一个字符串复制到另外一个字符数组里
功能实现函数:
1 | |
上面有讲,strcpy()函数的缺点,就是不能检查目标字符串是否容纳得下源字符串。使用strncpy()函数,它的第三个参数可指明最大可复制的字符数。
1 | |
8、strstr()函数
1 | |
函数功能:在一个字符串中查找另外一个字符串所在位置
功能实现函数:
1 | |
例如:
1 | |
如果needle字符串不是haystack的一部分,则会出现警告:assignment discards ‘const’ qualifier from pointer target type
9、memset()函数
1 | |
函数功能:可以把字符数组中所有的字符存储区填充同一个字符数据
功能实现函数:
1 | |
举例:
1 | |
10、sprintf()函数
1 | |
函数功能:按照格式把数据打印在字符数组中,形成一个字符串
1 | |
注意:使用sprintf()和使用printf()的方法一样,只是结果字符串被存放在数组fornal中,而不是被显示在屏幕上。
再有如果想将2转化为字符串“02”,该怎么办呢?
1 | |
11、memcpy函数
1 | |
函数功能:从存储区src 复制 n 个字符到存储区dest。
参数:
dest – 指向用于存储复制内容的目标数组,类型强制转换为 void* 指针。
src – 指向要复制的数据源,类型强制转换为 void* 指针。
n – 要被复制的字节数。
返回值:该函数返回一个指向目标存储区 dest 的指针。
功能实现函数:
1 | |
//示例一
1 | |
//示例二
1 | |
strcpy 和 memcpy 的区别:
(1)strcpy 和 memcpy 都是标准 C 库函数
(2)strcpy 提供了字符串的复制。即 strcpy 只用于字符串复制,并且它不仅复制字符串内容之外,还会复制字符串的结束符。
(3)strcpy函数的原型是:char* strcpy(char* dest, const char* src);
(4)memcpy提供了一般内存的复制。即memcpy对于需要复制的内容没有限制,因此用途更广。
(5)memcpy函数的原型是:void *memcpy( void *dest, const void *src, size_t count );
strcpy 和 memcpy 主要有以下3方面的区别:
(1)复制的内容不同。strcpy 只能复制字符串,而memcpy可以复制任何内容,例如字符串数组、整型、结构体、类等。
(2)复制的方法不同。strcpy不需要指定长度,它遇到被复制字符串结束符’\0’才结束,所以容易溢出。memcpy则是根据其第3个参数决定复制的长度。
(3)用途不同。通常在复制字符串时用strcpy,而需要复制其他类型数据时则一般用memcpy。
12、memcmp函数
1 | |
函数功能:
把存储区 str1 和存储区 str2 的前 n 个字节进行比较。
参数:
str1 – 指向内存块的指针。
str2 – 指向内存块的指针。
n – 要被比较的字节数。
返回值:
如果返回值 < 0,则表示 str1 小于 str2。
如果返回值 > 0,则表示 str2 小于 str1。
如果返回值 = 0,则表示 str1 等于 str2。
示例:
1 | |
三、将字符串转换成数字
atoi()函数、atol()函数、atof()函数
1 | |
函数功能: 分别把数字的字符串表示转换为 int、long和double形式。如果没有执行有效的转换返回0.
atoi()功能实现函数:
1 | |
测试:
1 | |
测试:
1 | |
itoa函数功能实现:
1 | |
测试:
1 | |
四、字符转十六进制
1 | |
值传递,址传递,引用传递
一、值传递
当函数被调用的时候,形参被创建,调用时带的参数被拷贝到刚创建好的形参,函数结束时,形参被摧毁。由于是参数的一个副本被传递到被调用的函数。所以,原始的参数不会被函数修改。
值传递的优点: 通过值来传递的参数可以是数字,变量,表达式。参数的值不会被“被调用的函数”修改。
值传递的缺点: 当函数被多次调用,值传递结构体和类会带来性能上的损害(耗时),给调用者返回值只能通过被调用函数的返回值。
事实上,关于 C 函数的参数传递规则可以表述如下:
所有传递给函数的参数都是按值传递的。
1 | |
看调用swap函数的代码:
swap (a, b) 时所完成的操作代码如下所示:
1 | |
请注意在调用执行 swap 函数的操作中我人为地加上了头两句:
1 | |
这是调用函数时的两个隐含动作。它确实存在,现在我只不过把它显式地写了出来而已。问题一下就清晰起来啦(看到这里,现在你认为函数里面交换操作的是a,b变量或者只是x,y变量呢?)
原来 ,其实函数在调用时是隐含地把实参a,b 的值分别赋值给了x,y,之后在你写的 swap 函数体内再也没有对a,b进行任何的操作了。交换的只是x,y变量。并不是a,b。当然a,b的值没有改变啦!函数只是把a,b的值通过赋值传递给了x,y,函数里头操作的只是x,y的值并不是a,b的值。这就是所谓的参数的值传递了。
哈哈,终于明白了,正是因为它隐含了那两个的赋值操作,才让我们产生了前述的迷惑(以为a,b已经代替了x,y,对x,y的操作就是对a,b的操作了,这是一个错误的观点啊!)。
参看:存储类、链接
上面的解释虽然便于理解,但是不对。按照值传递的特点,我们可以很清楚的看到,虽然在 swap 函数中暂时使得运行结果显示了交换后的数据,即达到了交换的目的,但实际情况却是随着 swap 函数的结束,被作为局部参数的形参 x,y 以及 swap 函数本身的局部参数 temp 都将结束期生存期,在内存中的存储空间释放,因此实参 a , b 并未受到影响,依然保持原值。
二、址传递
址传递又可以理解为指针传递,可以改变指针指向内容的值,但是不能改变指针本身,无需复制开销。如果需要改变指针本身,可以使用二重指针或者指针引用。
1 | |
看函数的接口部分:swap (int *px, int *py),请注意参数px,py都是指针
再看调用处:swap (&a, &b); 它将 a 的地址 &a 代入到 px,b 的地址 &b 代入到 py。同上面的值传递一样,函数调用时做了两个隐含的操作,将 &a ,&b 的值赋给了px,py。
整个 swap 函数调用执行如下:
1 | |
这样,有了头两行的隐含赋值操作,我们现在已经可以看出,指针 px,py 的值已经分别是 a,b 变量的地址值了。接下来,对 px,py 的操作当然也就是对 a,b 变量本身的操作了。所以函数里头的交换就是对 a,b 值的交换了,这就是所谓的址传递(传递 a,b 的地址给 px,py)
总结:
在这个程序中用指针变量作参数,虽然传送的是变量的地址,但实参和形参之间的数据传递依然是单向的“值传递”,即调用函数不可能改变实参指针变量的值。但它不同于一般值传递的是,它可以通过指针间接访问的特点来改变指针变量所指变量的值,即最终达到了改变实参的目的。
问题:如何实现C语言返回多个值??
数组的地址作为函数的形参,以址传递方式传递数组参数
1 | |
三、引用传递
为了通过引用来传递一个变量,把函数的参数声明为引用,当函数被调用时,所声明的引用形参,就会为其的引用。
引用传递的优点:改不改变 argument 的值是可以控制的,传递结构体、类时速度快,因为不用做一系列copy的工作;使用引用传递可以返回多个值;引用必须被初始化。
引用传递的缺点:使用引用传递时,北调函数会改变argument的值,向“调用者”保证,argument不会被“被调用函数”改变。
1 | |
看函数的 接口部分:swap (int &x, int &y) ,参数 x,y 是int的变量,调用时我们可以像值传递一样调用函数,但是 x,y 前都有一个取地址符号 &。有了这个,调用 swap 时函数会将 a,b 分别代替了 x,y。我们称 x,y 分别引用了 a,b 变量。这样函数里头操作的其实就是实参 a,b 本身了,也就是说函数里可以直接修改到 a,b 的值了。
面试题:动态分配内存问题
问题一:
1 | |
请问运行 Test 函数会有什么样的结果?
答:程序崩溃。
因为 GetMemory 并不能传递动态内存,Test 函数中的 str 一直都是 NULL。strcpy(str, “hello world”);将使程序崩溃。
在函数内部修改形参并不能真正的改变传入形参的值,执行完
char *str = NULL;
GetMemory( str );
后的str仍然为NULL;
二级指针作为函数的形式参数可以让被调用函数使用其他函数的指针类型存储区
1 | |
第二种方法:使用返回值
1 | |
问题二:
1 | |
请问运行 Test 函数会有什么样的结果?
答:可能是乱码。
因为 GetMemory 返回的是指向“栈内存”的指针,该指针的地址不是 NULL,但其原现的内容已经被清除,新内容不可知。
char p[] = “hello world”;
return p;
p[]数组为函数内的局部自动变量,在函数返回后,内存已经被释放。这是许多程序员常犯的错误,其根源在于不理解变量的生存期。
1 | |
关键字typedef
内存管理
存储类型关键字
定义: 是对声明的实现或者实例化。连接器(linker)需要定义来引用内存实体。与上面的声明相应的定义如下:参看:C语言再学习 – 存储类、链接
C语言中有 5 个作为存储类说明符的关键字。关键字typedef 与内存存储无关,由于语法原因被归入此类。
现在简单了解一下这五个存储类说明符的关键字:
说明符 auto 表明一个变量具有自动存储时期。该说明符只能用于在具有代码块作用域的变量声明中,而这样的变量已经拥有自动存储时期,因此它主要用来明确指出意图,使程序更易读。
说明符 register 也只能用于具有代码块作用域的变量。它将一个变量归入寄存器存储类,这相当于请求将该变量存储在一个寄存器内,以更快地存取。它的使用也使得不能获得变量的地址。
说明符 static 在用于具有代码块的作用域的变量的声明时,使该变量具有静态存储时期,从而得以在程序运行期间(即使在包含该变量的代码块没有运行时)存在并保留其值。变量仍具有代码块作用域和空链接。static 用于具有文件作用域的变量的声明时,表明该变量具有内部链接。
说明符 extern 表明在声明一个已经在别处定义了的变量。如果包含 extern 的声明具有文件作用域,所指向的变量必须具有外部链接。如果包含 extern 的声明具有代码块作用域,所指向的变量可能具有外部链接也可能具有内部链接,这取决于该变量的定义声明。
关键字 typedef 参看:C语言再学习 – 关键字typedef
注意,这 5 个作为存储类说明符的关键字,不可以同时出现的。
例如: typedef static int int32 是错误的。
下面来一一详细介绍:
1、auto关键字
auto 关键字在C语言中只有一个作用,那就是修饰局部变量。
auto 修饰局部变量,表示这个局部变量是自动局部变量,自动局部变量分配在栈上。(既然在栈上,说明它如果不初始化那么值就是随机的)
平时定义局部变量时就是定义的auto的,只是省略了auto关键字而已。可见,auto的局部变量其实就是默认定义的普通的局部变量。 即 int a = 10; 等价于 auto int a = 10;
auto 修饰局部变量,若省去数据类型,变量默认为 int 类型
1 | |
2、register关键字
在 C 语言中的 register 修饰的变量表示将此变量存储在CPU的寄存器中,由于CPU访问寄存器比访问内存快很多,可以大大提高运算速度。但在使用register时有几点需要注意。
- 用register修饰的变量只能是局部变量,不能是全局变量。CPU的寄存器资源有限,因此不可能让一个变量一直占着CPU寄存器。
- register变量一定要是CPU可以接受的值。
- 不可以用&运算符对register变量进行取址。比如 int i;(自动为auto)int *p=&i;是对的, 但register int j; int *p = &j; 是错的,因为无法对寄存器取址。
- register只是请求寄存器变量,不一定能够成功。
- 随着编译程序设计技术的进步,在决定那些变量应该被存到寄存器中时,现在的C编译环境能比程序员做出更好的决定。实际上,许多编译程序都会忽略register修饰符,因为尽管它完全合法,但它仅仅是暗示而不是命令。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15#include <stdio.h>
//register int n; 修饰全局变量 错误: ‘n’的寄存器名无效
int main (void)
{
register int i;
//int *p = &i; 对i取地址 错误: 要求寄存器变量‘i’的地址。
int tmp = 0;
for (i = 1; i < 100; i++)
tmp += i;
printf ("tmp = %d\n", tmp);
return 0;
}
输出结果:
tmp = 4950
寄存器变量(register): 寄存器变量会尽量把变量放到寄存器(而不是栈或堆), 从而加快存取速度。下面的例子可以很好的看出:
1 | |
3、static关键字
参看:C语言再学习 – 内存管理
参看:C语言再学习 – 存储类、链接
首先了解下,进程中的内存区域划分
(1)代码区 存放程序的功能代码的区域,比如:函数名
(2)只读常量区 主要存放字符串常量和const修饰的全局变量
(3)全局区 主要存放 已经初始化的全局变量 和 static修饰的全局变量
(4)BSS段 主要存放 没有初始化的全局变量 和 static修饰的局部变量,BSS段会在main函数执行之前自动清零
(5)堆区 主要表示使用malloc/calloc/realloc等手动申请的动态内存空间,内存由程序员手动申请和手动释放
(6)栈区 主要存放局部变量(包括函数的形参),const修饰的局部变量,以及块变量,该内存区域由操作系统自动管理
下面详细介绍 static 关键字,主要有三类用法:
1)static 修饰全局变量
static 修饰的全局变量也叫静态全局变量,和已经初始化的全局变量同 在全局区。
该类具有静态存储时期、文件作用域和内部链接,仅在编译时初始化一次。如未明确初始化,它的字节都被设定为0。static全局变量只初使化一次,是为了防止在其他文件单元中被引用;利用这一特性可以在不同的文件中定义同名函数和同名变量,而不必担心命名冲突。
示例说明:
1 | |
2)static 修饰局部变量
static 修饰的局部变量也叫静态局部变量,和没有初始化的全局变量同 在BBS段。而非静态局部变量是被分配在栈上面的。非静态局部变量,函数调用结束后存储空间释放;静态局部变量,具有静态存储时期。只在程序开始时执行一次,函数调用结束后存储区空间并不释放,保留其当前值。
该类具有静态存储时期、代码作用域和空链接,仅在编译时初始化一次。如未明确初始化,它的字节都被设定为0。
1 | |
3)static 修饰函数
外部函数可被其他文件中的函数调用,而静态函数只可以在定义它的文件中使用。例如,考虑一个包含如下函数声明的文件:
1 | |
函数gamma ()和delta ()可被程序的其他文件中的函数使用,而beta ()则不可以,因为beta ()被限定在一个文件内,故可在其他文件中使用相同名称的不同函数。使用 static 存储类的原因之一就是创建为一个特定模块所私有的函数,从而避免可能的名字冲突。
通常使用关键字 extern 来声明在其他文件中定义的函数。这一习惯做法主要是为了程序更清晰,因为除非函数声明使用了关键字 static ,否则认为就是extern 的。
4、extern 关键字
首先,再讲解之前先要了解下,声明和定义的区别。
参看:C语言再学习 – 声明与定义
举个例子:
A) int i;
B) extern int i;
哪个是定义?哪个是声明?或者都是定义或者都是声明?
什么是定义:所谓的定义就是(编译器)创建一个对象,为这个对象分配一块内存并给它取上一个名字,这个名字就是我们经常所说的变量名或对象名。但注意,这个名字一旦和这块内存匹配起来,它们就同生共死,终生不离不弃。并且这块内存的位置也不能被改变。一个变量或对象在一定的区域内(比如函数内,全局等)只能被定义一次,如果定义多次,编译器会提示你重复定义同一个变量或对象。
什么是声明:有两重含义,如下:
第一重含义:告诉编译器,这个名字已经匹配到一块内存上了,下面的代码用到变量或对象是在别的地方定义的。声明可以出现多次。
第二重含义:告诉编译器,我这个名字我先预定了,别的地方再也不能用它来作为变量名或对象名。比如你在图书馆自习室的某个座位上放了一本书,表明这个座位已经有人预订,别人再也不允许使用这个座位。其实这个时候你本人并没有坐在这个座位上。这种声明最典型的例子就是函数参数的声明,例如:
void fun(int i, char c);
好,这样一解释,我们可以很清楚的判断: A)是定义; B)是声明。
记住, 定义声明最重要的区别:定义创建了对象并为这个对象分配了内存,声明没有分配内存。
声明: 指定了一个变量的标识符,用来描述变量的类型,是类型还是对象,或者函数等。声明,用于编译器(compiler)识别变量名所引用的实体。以下这些就是声明:
1 | |
定义: 是对声明的实现或者实例化。连接器(linker)需要它(定义)来引用内存实体。与上面的声明相应的定义如下:
1 | |
无论如何,定义 操作是只能做一次的。如果你忘了定义一些你已经声明过的变量,或者在某些地方被引用到的变量,那么,连接器linker是不知道这些引用该连接到那块内存上的。然后就会报missing symbols 这样的错误。如果你定义变量超过一次,连接器是不知道把引用和哪块内存连接,然后就会报 duplicated symbols这样的错误了。以上的symbols其实就是指定义后的变量名,也就是其标识的内存块。
总结:
如果只是为了给编译器提供引用标识,让编译器能够知道有这个引用,能用这个引用来引用某个实体(但没有为实体分配具体内存块的过程)是为声明。如果该操作能够为引用指定一块特定的内存,使得该引用能够在link阶段唯一正确地对应一块内存,这样的操作是为定义。
声明是为了让编译器正确处理对声明变量和函数的引用。定义是一个给变量分配内存的过程,或者是说明一个函数具体干什么用。
通过上述对声明和定义的解释可以看出,在C语言中,修饰符 extern 用在变量或者函数的声明前,用来说明“此变量/函数是在别处定义的,要在此处引用”。extern 是 C/C++ 语言中表明函数和全局变量作用范围(可见性)的关键字,该关键字告诉编译器,其声明的函数和变量可以在本模块或其它模块中使用。
1)extern 修饰变量的声明
具有外部链接的静态变量具有文件作用域,外部链接和静态存储时期。这一类型有时被称为外部存储类,这一类型的变量被称为外部变量。把变量的定义声明放在所有函数之外,即创建了一个外部变量。为了使程序更加清晰,可以在使用外部变量的函数中通过使用 extern 关键字来再次声明它。如果变量是在别的文件中定义,使用 extern 来声明该变量就是必须的。
1 | |
下列 3 个例子展示了外部变量和自动变量的 4 种可能组合:
/例1/
1 | |
/例2/
1 | |
/例3/
1 | |
这些例子说明了外部变量的作用域:从声明的位置开始到文件结尾为止。它们也说明了外部变量的生存期。
外部变量H和P存在的时间与程序运行时间一样,并且它们不局限于任一函数,在一个特定函数返回时并不消失。
多文件的程序中声明外部变量,使用 extern 来声明该变量就是必须的。注意能够被其他模块以extern修饰符引用到的变量通常是全局变量,可以放在file2.c文件的任何位置
1 | |
1 | |
2)extern 修饰函数的声明
外部函数可被其他文件中的函数调用,而静态函数只可以在定义它的文件中使用。例如,考虑一个包含如下函数声明的文件:
1 | |
函数gamma ()和delta ()可被程序的其他文件中的函数使用,而beta ()则不可以,因为beta ()被限定在一个文件内,故可在其他文件中使用相同名称的不同函数。使用 static 存储类的原因之一就是创建为一个特定模块所私有的函数,从而避免可能的名字冲突。
通常使用关键字 extern 来声明在其他文件中定义的函数。这一习惯做法主要是为了程序更清晰,因为除非函数声明使用了关键字 static ,否则认为就是extern 的。换句话说,在定义(函数)的时候,这个extern可以被省略。
如果函数的声明中带有关键字 extern,仅仅是暗示这个函数可能再别的源文件里定义,没有其它作用。即下述这两个函数声明没有明显的区别:extern int foo (); 和 int foo (); 函数定义和声明时 extern 可有可无。
1 | |
1 | |
一般把所有的全局变量和全局函数都放在一个 *.c 文件中,然后用一个同名的 *.h 文件包含所有的函数和变量的声明.
1 | |
1 | |
注意:
- extern int num = 10; 没有这种形式,不是定义。如果在 read.h中如此写的话会出现:
read.h:3:12: 警告: ‘num’已初始化,却又被声明为‘extern’ [默认启用] In file included from read.c:2:0: read.h:3:12: 警告: ‘num’已初始化,却又被声明为‘extern’ [默认启用] /tmp/ccQ3Jzzm.o:(.data+0x0): multiple definition of `num’ /tmp/cceLUBvB.o:(.data+0x0): first defined here collect2: ld 返回 1 - 再有,在使用 extern 时候要严格对应声明时的格式,例如:
声明的函数为: extern void read (void);
定义的时候 返回值、形参类型、函数名 需要一致,为 void read (void) {…}
C 程序中,不允许出现类型不同的同名变量。 - 定义数组,修饰指针
在一个源文件里定义了一个数组:char a[100];
在另外一个文件里用下列语句进行了声明:extern char *a;
这样是不可以的,程序运行时会告诉你非法访问。原因在于,指向类型T的指针并不等价于类型T的数组。extern char *a声明的是一个指针变量而不是字符数组,因此与实际的定义不同,从而造成运行时非法访问。应该将声明改为extern char a[ ]。
但是,extern char a[]与 extern char a[100]等价。
因为这只是声明,不分配空间,所以编译器无需知道这个数组有多少个元素。
3) extern “C”
上面讲到了,C 程序中,不允许出现类型不同的同名变量。例如:
1 | |
而C++程序中 却允许出现重载。重载的定义:同一个作用域,函数名相同,参数表不同的函数构成重载关系,例如:
1 | |
gcc -c rename.cpp //生成 rename.o
nm rename.o //查看
1 | |
可以看到:函数被 C++编译后在库中的名字与 C 语言的不同。
函数void foo (int i); 的库名为_Z3fooi
函数void foo (int i, double d); 的库名为 _Z3fooid
通过库名,可以看出来包含了函数名、函数参数数量及类型信息,C++就是靠这种机制来实现函数重载的。而 C 语言则不会,因此会造成链接时找不到对应函数的情况,此时C函数就需要用extern “C”进行链接指定,来解决名字匹配问题,这告诉编译器,请保持我的名称,不要给我生成用于链接的中间函数名。
未加 extern “C” 声明的,在C++中因为重载,库名是 _Z3fooid,加上 extern “C” 会采用 C语言的方式 编译生成 foo。extern “C”这个声明的真实目的是为了实现C++与C及其它语言的混合编程。
参看:c/c++ 混合编程的 extern “C” 参看:extern “c”用法之一
参看:extern “c”用法解析
参看:extern ”C”的使用
C++中 extern “C” 的两种用法:
1)用C++语言写的一个函数,如果想让这个函数可以被其他C语言程序所用,则用extern “C” 来告诉C++编译器,请用C语言习惯来编译此函数。如:
1 | |
1 | |
1 | |
__cplusplus是cpp中自定义的一个宏,告诉编译器,这部分代码按C语言的格式进行编译,而不是C++的。
源文件为*.c,__cplusplus没有被定义,extern “C” {}这时没有生效对于C他看到只是 extern int add(int, int);
add 函数编译符号成 add
gcc -c main.c nm main.o U add 00000000 T main U printf
源文件为*.cpp(或*.cc,.C,.cpp,.cxx,.c++), __cplusplus被定义 ,对于C++他看到的是 extern “C” { extern int add( int ,int);}编译器就会知道 add(13, 6);调用的C风格的函数,就会知道去找add符号而不是_Z3addii ;因此编译正常通过。
注:-lstdc++ 申明用c++库
如果将,add.h 如下改写,不使用 extern “C”:
1 | |
因为g++会自动将c的模块中的符号表转换为 _Z3addii 这也是GNU compiler的强大之处,可是别的编译器也许就不这么智能了。所以在c/c++混合编程时还是最好加上extern “C”。
2)如果要在C++程序中调用C语言写的函数, 在C++程序里边用 extern “C” 修饰要被调用的这个C程序,告诉C++编译器此函数是C语言写的,是C语言编译器生成的,调用他的时候请按照C语言习惯传递参数等。
1 | |
存储类、链接
一、存储类
C为变量提供了5种不同的存储类型,或称存储类。
下面是C的5种存储类:
自动 —— 在一个代码块内(或在一个函数头部作为参量)声明的变量,无论有没有存储类修饰符 auto,都属于自动存储类。该类具有自动存储时期、代码块作用域和空链接。如未经初始化,它的值是不定的。
寄存器 —— 在一个代码块内(或在一个函数头部作为变量)使用存储类修饰符 register 声明的变量属于寄存器存储类。该类具有自动存储时期、代码块作用域和空链接,并且您无法获得其地址。把一个变量声明为寄存器变量可以指示编译器提供可用的最快访问。如未经初始化,它的值是不定的。
静态、空链接 —— 在一个代码块内使用存储类修饰符 static 声明的变量属于静态空链接存储类。该类具有静态存储时期、代码作用域和空链接,仅在编译时初始化一次。如未明确初始化,它的字节都被设定为0。
静态、外部链接 —— 在所有函数外部定义、未使用存储类修饰符 static 的变量属于静态、外部链接存储类。该类具有静态存储时期、文件作用域和外部链接,仅在编译时初始化一次。如未明确初始化,它的字节都被设定为0。
静态、内部链接 —— 在所有函数外部定义、使用存储类修饰符 static 的变量属于静态、内部链接存储类。该类具有静态存储时期、文件作用域和内部链接,仅在编译时初始化一次。如未明确初始化,它的字节都被设定为0。
这5种存储类有一个共同之处:在决定了使用哪一个存储类之后,就自动决定了作用域和存储时期。
其实还有一种选择就是使用 malloc() 函数来分配和管理内存,该函数返回一个指向具有所请求字节数的内存块的指针。将这一内存的地址作为参数来条用函数free(),可以使该内存块重新可用。
存储类
时期
作用域
链接
声明方式
自动
自动
代码块
空
代码块内
寄存器
自动
代码块
空
代码块内,使用关键字register
具有外部链接的静态
静态
文件
外部
所有函数之外
具有内部链接的静态
静态
文件
内部
所有函数之外,使用关键字static
空链接的静态
静态
代码块
空
代码块内,使用关键字static
上面提到的一些术语如:作用域、链接和存储时期。我们来做一下了解。
1、作用域
作用域描述了程序中可以访问一个标识符的一个或多个区域。一个C变量的作用域可以是代码块作用域、函数原型作用域,或者文件作用域。
代码块作用域:
double blocky (double cleo)
{
double patcrick = 0.0;
int i;
for (i = 0; i < 10; i++)
{
double q = cleo * i; /q作用域的开始/
…
patrick * = q;
} /q作用域的结束/
return patrick;
}
上面代码中的变量 cleo 和 patrick 都有直到结束花括号的代码块作用域,q的作用域被限制在内部代码块内,只有该代码块内的代码可以访问q。
由上可知,代码块中定义的变量,从该变量被定义的地方到包含该定义的代码块的末尾该变量可见。另外,函数的形式参量尽管在函数的开始花括号前进行定义,同样也具有代码块作用域,隶属于包含函数体的代码块。
函数原型作用域:
适用于函数原型中使用的变量名,如下所示:
int mighty (int mouse, double large);
int mighty (int , double ); (同上)
函数原型作用域从变量定义处一直到原型声明的末尾,这意味着编译器在处理一个函数原型的参数是,它所关心的只是该参数的类型。
文件作用域:
一个在所有函数之外定义的变量具有文件作用域,具有文件作用域的变量从它定义处到包含该定义的文件结尾都是可见的。
#include <stdio.h>
int unite = 0;
void critic (void);
int main (void)
{
…
return 0;
}
void critic (void)
{
…
}
这里,变量 units 具有文件作用域,在 main () 和 critic () 中都可以使用它。因为它们可以在不止一个函数中使用,文件作用域变量也被称为全局变量。
2、链接
一个C变量具有下列链接之一:外部链接、内部链接、空链接。
外部链接:
一个具有外部链接的变量可以在一个多文件程序的任何地方使用。
int n = 5; /*文件作用域,外部链接,未使用 static */
int main (void)
{
…
return 0;
}
内部链接:
一个具有内部链接的变量可以在一个文件的任何地方使用。
static int dodgers = 3; /文件作用域,内部链接,使用了 static ,该文件所私有/
int main (void)
{
…
return 0;
}
空链接:
具有代码块作用域或者函数原型作用域的变量有空链接,意味着它们是由其定义所在的代码块或函数原型所私有的。
double blocky (double cleo)
{
double patcrick = 0.0; /代码块作用域,空链接,该代码块所私有/
int i;
for (i = 0; i < 10; i++)
{
double q = cleo * i; /q作用域的开始/
…
patrick * = q;
} /q作用域的结束/
return patrick;
}
3、存储时期
一个C变量有以下两种存储时期之一:静态存储时期和自动存储时期。
静态存储时期:
如果一个变量具有静态存储时期,它在程序执行期间将一直存在。具有文件作用域的变量具有静态存储时期。
注意对于具有文件作用域的变量,关键字 static 表明链接类型,并非存储时期。一个使用 static 声明了的文件作用域变量具有内部链接,而所有的文件作用域变量,无论它具有内部链接,还是具有外部链接,都具有静态存储时期。
总结上面这句话就是, static 修饰的静态全局变量,具有内部链接,不能被其他文件使用。
自动存储时期:
具有代码块作用域的变量,一般情况下具有自动存储时期。
在程序进入定义这些变量的代码块时,将为这些变量分配内存;当退出这个代码块时,分配的内存将被释放。
4、自动变量
属于自动存储类的变量具有自动存储时期、代码块作用域和空链接。默认情况下,在代码块或函数的头部定义的任意变量都属于自动存储类。
关键字auto:
关键字auto称为存储类说明符。
int main (void)
{
auto int p;
}
为了表明有意覆盖一个外部函数定义时,或者为了表明不能把变量改变为其他存储类这一点很重要时,可以这样做。
代码块作用域和空链接意味着只有变量定义所在的代码块才可以通过名字访问变量(当然,可以用参数想其他函数传送该变量的值和地址,但那是以间接的方式知道的)。另一个函数可以使用具有同样名字的变量,但那将是存储在不同内存位置中的一个独立变量。
int loop (int n)
{
int m; // m的作用域
scanf (“%d, &m”);
{
int i; //m 和 i 的作用域
for (i = m; i < n; i++)
put (“i is local to a sub-block\n”);
}
return m; //m的作用域, i 已经消失
}
如上嵌套代码块中,只有定义变量的代码块及其内部的任何代码块可以访问的变量,变量 i 仅在内层花括号中是可见的。如果试图在内层代码块之前或之后使用该变量,将得到一个编译错误。
如果在内层代码块定义了一个具有和外层代码块变量同一个名字的变量,我们称之为内层定义覆盖了外部定义,但当运行离开内层代码块时,外部变量重新恢复作用。
#include <stdio.h>
int main (void)
{
int x = 30;
printf (“x in outer block : %d\n”, x);
{
int x = 77;
printf (“x int inner block : %d\n”, x);
}
printf (“x in outer block : %d\n”, x);
while (x++ < 33)
{
int x = 100;
x++;
printf (“x in while loop : %d\n”, x);
}
printf (“x in outer block : %d\n”, x);
return 0;
}
输出结果:
x in outer block : 30
x int inner block : 77
x in outer block : 30
x in while loop : 101
x in while loop : 101
x in while loop : 101
x in outer block : 34
1)不带 {} 的代码块
语句若为循环或者 if 语句的一部分,即使没有使用 { },也认为是一个代码块。更完整地说,整个循环是该循环所在代码块的子代码块,而循环体是整个循环代码块的子代码块。
#include <stdio.h>
int main (void)
{
int n = 10;
printf (“Initially, n = %d\n”, n);
for (int n = 1; n < 3; n++)
printf (“loop 1: n = %d\n”, n);
printf (“After loop 1, n = %d\n”, n);
for (int n = 1; n < 3; n++)
{
printf (“loop 2 index n = %d\n”, n);
int n = 30;
printf (“loop 2 n = %d\n”, n);
n++;
}
printf (“After loop 2, n = %d\n”, n);
return 0;
}
输出结果:
Initially, n = 10
loop 1: n = 1
loop 1: n = 2
After loop 1, n = 10
loop 2 index n = 1
loop 2 n = 30
loop 2 index n = 2
loop 2 n = 30
After loop 2, n = 10
注意,有些编译器可能不支持这些新的C99作用域规则,需要使用 -std=c99选项来激活这些规则:
例如: gcc -std=c99 forc99.c
2)自动变量的初始化
除非显式的初始化自动变量,否则它不会被自动初始化。
int main (void)
{
int n;
int m = 5;
}
变量 m 的初始化为5,而变量 n 的初值则是先前占用分配给它的空间任意值。不要指望这个值是 0 。除非你对自动变量进行显示的初始化,否则当自动变量创建时,它们的值总是垃圾值。
#include <stdio.h>
int main (void)
{
int a;
int b = a + 3;
printf (“a = %d, b = %d\n”, a, b);
return 0;
}
输出结果:
a = 134513705, b = 134513708
倘若一个非常量表达式中所用到的变量先前定义过的话,可将自动变量初始化为该表达式:
int main (void)
{
int n = 1;
int m = 5 * n; //使用先前定义过的变量
}
5、寄存器变量
寄存器变量多是存放在一个寄存器而非内存中,所以无法获得寄存器变量的地址。具有代码块作用域、空链接以及自动存储时期。通过使用存储类说明符 register 可以声明寄存器变量:
int main (void)
{
register int n;
}
可以把一个形式参量请求为寄存器变量,只需在函数头部使用 register 关键字:
void macho (register int n)
可以使用 register 声明的类型是有限的。例如,处理器可能没有足够大的寄存器来容纳 double 类型。
6、具有代码块作用域的静态变量
“静态”是指变量的位置固定不动,而非变量不可变。具有文件作用域的变量自动(也是必须的)具有静态存储时期。也可以创建具有代码块作用域,兼具静态存储的局部变量。这些变量和自动变量具有相同的作用域,但当包含这些变量的函数完成工作时,它们并不消失。也就是说,这些变量具有代码块作用域、空链接,却有静态存储时期。从一次函数调用到下一次调用,计算机都记录着它们的值。这样的变量通过使用存储类说明符 static (这提供了静态存储时期)在代码块内声明(这提供了代码块作用域和空链接)创建。
#include <stdio.h>
void trystat (void);
int main (void)
{
int count;
for (count = 1; count <= 3; count++)
{
printf (“Hello World %d\n”, count);
trystat ();
}
return 0;
}
void trystat (void)
{
int fade = 1;
static int stay = 1;
printf (“fade = %d and stay = %d\n”, fade++, stay++);
}
输出结果:
Hello World 1
fade = 1 and stay = 1
Hello World 2
fade = 1 and stay = 2
Hello World 3
fade = 1 and stay = 3
在每次调用trystat()时fade都被初始化,而stay只在编译trystat()时被初始化一次。如果不显式地对静态变量进行初始化,它们将被初始化为0.
7、具有外部链接的静态变量
具有外部链接的静态变量具有文件作用域,外部链接和静态存储时期。这一类型有时被称为外部存储类,这一类型的变量被称为外部变量。把变量的定义声明放在所有函数之外,即创建了一个外部变量。为了使程序更加清晰,可以在使用外部变量的函数中通过使用 extern 关键字来再次声明它。如果变量是在别的文件中定义,使用 extern 来声明该变量就是必须的。
int n; /外部定义的变量/
double Up[100]; /外部定义的数组/
extern char Coal; /必须的声明,因为Coal在其他文件中定义/
void next (void);
int main (void)
{
extern double Up[]; /可选的声明,此处不必指明数组大小/
extern int n; /可选的声明,如果将extern漏掉,就会建立一个独立的自动变量/
}
void next (void)
{
…
}
下列 3 个例子展示了外部变量和自动变量的 4 种可能组合:
/例1/
int H;
int magic ();
int main (void)
{
extern int H; /声明H为外部变量/
…
}
int magic ()
{
extern int H; /与上面的H是同一变量/
}
/例2/
int H;
int magic ();
int main (void)
{
extern int H; /声明H为外部变量/
…
}
int magic ()
{
… /未声明H,但知道该变量/
}
/例3/
int H; /对main()和magic()不可见,但是对文件中其他不单独拥有局部H的函数可见/
int magic ();
int main (void)
{
int H; /声明H, 默认为自动变量,main()的局部变量/
…
}
int P;/对magic()可见,对main()不可见,因为P声明子啊main()之后/
int magic ()
{
auto int H; /把局部变量H显式地声明为自动变量/
}
这些例子说明了外部变量的作用域:从声明的位置开始到文件结尾为止。它们也说明了外部变量的生存期。
外部变量H和P存在的时间与程序运行时间一样,并且它们不局限于任一函数,在一个特定函数返回时并不消失。
1)外部变量初始化
外部变量可以被显式地初始化,如果不对外部变量初始化,则它们将自动被赋初值 0. 这一原则也适用于外部定义的数组元素。不同于自动变量,只可以用常量表达式来初始化文件作用域变量。
int x = 10; //可以, 10是常量
int y = 3 + 20; //可以,一个常量表达式
size_t = sizeof (int); //可以,一个常量表达式
int x2 = 2 * x; //不可以, x是一个变量
(只要类型不是一个变长数组,sizeof表达式就被认为是常量表达式)
2)外部变量的使用
#include <stdio.h>
int units = 0; //一个外部变量
void critic (void);
int main (void)
{
extern int units; //可选的二次声明
printf (“How many pounds to a firkin of butter?\n”);
scanf (“%d”, &units);
while (units != 56)
critic ();
printf (“You must have looked it up!\n”);
return 0;
}
void critic (void)
{ //这里省略了可选的二次声明
printf (“No luck, chummy. Try again\n”);
scanf (“%d”, &units);
}
输出结果:
How many pounds to a firkin of butter?
23
No luck, chummy. Try again
56
You must have looked it up!
两个函数main() 和 critic() 都是标识符 units 来访问同一个变量。在 C 的术语中,称 units 具有文件作用域、外部链接以及静态存储时期。
在上述例子中,声明主要是使程序的可读性更好。存储类说明符 extern 告诉编译器在该函数中用到的 units 都是指同一个在函数外部(甚至在文件之外)定义的变量。再次,main()和 critic ()都使用了外部定义的 units。
3)定义和声明
可参看:C语言再学习 2–声明与定义
这里需要注意的是,关键字 extern 用于声明,而非定义。
8、具有内部链接的静态变量
具有内部链接的静态变量,具有静态存储时期、文件作用域以及内部链接。通过使用存储类说明符 static 在所有函数外部进行定义(正如定义外部变量那样)来创建一个这样的变量。
int n = 1; //外部链接
static int m = 1; //具有内部链接的静态变量
int main (void)
{
extern int n; //使用全局变量 n
extern int m; //使用全局变量 m
}
可以在函数中使用存储类说明符 extern 来再次声明任何具有文件作用域的变量。这样的声明并不改变链接。
9、存储类说明符
C语言中有 5 个作为存储类说明符的关键字,分别是 auto、register、static、extern 以及 typedef。关键字typedef 与内存存储无关,由于语法原因被归入此类。
在文章:C语言再学习 18–关键字 里面我们将详细介绍各个关键字。
现在简单了解一下这五个存储类说明符的关键字:
说明符 auto 表明一个变量具有自动存储时期。该说明符只能用于在具有代码块作用域的变量声明中,而这样的变量已经拥有自动存储时期,因此它主要用来明确指出意图,使程序更易读。
说明符 register也只能用于具有代码块作用域的变量。它将一个变量归入寄存器存储类,这相当于请求将该变量存储在一个寄存器内,以更快地存取。它的使用也使得不能获得变量的地址。
说明符 static在用于具有代码块的作用域的变量的声明时,使该变量具有静态存储时期,从而得以在程序运行期间(即使在包含该变量的代码块没有运行时)存在并保留其值。变量仍具有代码块作用域和空链接。static 用于具有文件作用域的变量的声明时,表明该变量具有内部链接。
说明符 extern表明在声明一个已经在别处定义了的变量。如果包含 extern 的声明具有文件作用域,所指向的变量必须具有外部链接。如果包含 extern 的声明具有代码块作用域,所指向的变量可能具有外部链接也可能具有内部链接,这取决于该变量的定义声明。
//parta.c
#include <stdio.h>
void report_count ();
void accumulate (int k);
int count = 0; //文件作用域,外部链接
int main (void)
{
int value; //自动变量
register int i; //寄存器变量
printf ("Enter a positive integer (0 to quit): ");
while (scanf ("%d", &value) == 1 && value > 0)
{
++count; //使用文件作用域变量
for (i = value; i >= 0; i--)
accumulate (i);
printf ("Enter a posotove integer (0 to quit):");
}
report_count ();
return 0;
}
void report_count ()
{
printf (“Loop executed %d times\n”, count);
}
//partb.c
#include <stdio.h>
extern int count; //引用声明,外部链接
static int total = 0; //文件作用域、静态定义,内部链接
void accumulate (int k); //原型
void accumulate (int k) //k 具有代码块作用域,空链接
{
static int subtotal = 0; //静态、空链接
if (k <= 0)
{
printf (“Loop cycle: %d\n”, count);
printf (“subtotal: %d; total: %d\n”, subtotal, total);
subtotal = 0;
}
else
{
subtotal += k;
total += k;
}
}
gcc parta.c partb.c -o part
输出结果:
Enter a positive integer (0 to quit): 5
Loop cycle: 1
subtotal: 15; total: 15
Enter a posotove integer (0 to quit):10
Loop cycle: 2
subtotal: 55; total: 70
Enter a posotove integer (0 to quit):2
Loop cycle: 3
subtotal: 3; total: 73
Enter a posotove integer (0 to quit):0
Loop executed 3 times
10、存储类和函数
外部函数可被其他文件中的函数调用,而静态函数只可以在定义它的文件中使用。例如,考虑一个包含如下函数声明的文件:
double gamma (); //默认为外部的
static double beta (); //静态函数
extern double delta ();
函数gamma ()和delta ()可被程序的其他文件中的函数使用,而beta ()则不可以,因为beta ()被限定在一个文件内,故可在其他文件中使用相同名称的不同函数。使用 static 存储类的原因之一就是创建为一个特定模块所私有的函数,从而避免可能的名字冲突。
通常使用关键字 extern 来声明在其他文件中定义的函数。这一习惯做法主要是为了程序更清晰,因为除非函数声明使用了关键字 static ,否则认为就是extern 的。